How Pydantic v2’s Rust-powered validation and Elasticsearch’s search engine capabilities complement each other — and why the new BaseESModel integration changes how Python teams build data pipelines.
Every data pipeline has the same silent enemy: data that looks valid until the moment it reaches the database. A date stored as a plain string. A numeric ID that arrived as None. A nested object where a required field was simply omitted. In a strongly typed language, the compiler catches these problems early. In Python, they tend to surface at runtime, buried inside a stack trace in production, after the document has already been written — or worse, rejected — by Elasticsearch.
Pydantic and Elasticsearch address this gap together in a way that neither tool does alone. Pydantic enforces data shape and type constraints at the Python boundary, before any document is sent to the cluster. Elasticsearch stores, indexes, and makes that validated data searchable at scale. Together, they form a pipeline where the structure of your data is defined once, enforced continuously, and consistent from ingestion to retrieval. This article explains how that pairing works, how to set it up, and where the integration has matured significantly in 2025 and 2026.
Why This Pairing Works So Well
To understand why Pydantic and Elasticsearch make such a natural pair, it helps to understand what each one is actually responsible for — and what each one cannot do on its own.
Elasticsearch is a distributed search and analytics engine built on Apache Lucene. It accepts JSON documents, indexes them according to a mapping you provide (or infers for you), and makes them searchable through a rich query DSL. What Elasticsearch does not do, however, is validate your data before writing it. Its dynamic mapping is convenient but also dangerous — if you send a date as a string in one document and as a Unix timestamp in the next, Elasticsearch will silently accommodate both, leading to mapping conflicts and unreliable query results. It stores what you give it.
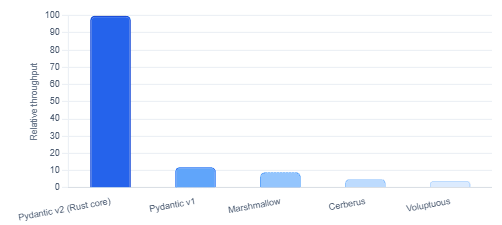
Pydantic fills the gap upstream. By defining your data model as a BaseModel subclass, you get runtime type checking and coercion, field-level constraint enforcement, clear and structured validation error messages, and the ability to generate a JSON schema from your model automatically. Pydantic v2, rewritten in Rust in 2023, is 5 to 50 times faster than v1 depending on the workload, which means the validation overhead on a high-throughput ingestion pipeline is genuinely negligible. Used by FastAPI, LangChain, OpenAI, and over 466,000 repositories on GitHub, it has become the de facto standard for Python data validation.
The core insight: Pydantic owns the contract — it decides what a valid document looks like. Elasticsearch owns the storage and retrieval — it decides how to index and query documents. When your Pydantic model and your Elasticsearch mapping agree, your entire pipeline becomes consistent by construction, not by convention.
Ingestion Layer
Raw JSON or dict from API, Kafka, or file. Pydantic validates and coerces before anything reaches Elasticsearch.
Pydantic Model
BaseModel defines fields, types, constraints. Validation errors surface here — before any network call is made.
Mapping Generation
Pydantic’s type information drives Elasticsearch index mapping, keeping schema and storage in sync.
Elasticsearch
Stores validated documents. Dynamic mapping is either disabled or pre-seeded from the Pydantic schema.
Pydantic v2 in One Minute
A Pydantic model is a Python class that inherits from BaseModel. Each field is declared with a type annotation, and optionally enriched with a Field() call that adds constraints like min_length, gt (greater than), or a default value. When you instantiate the model, Pydantic validates and coerces the input immediately. If the data does not conform, it raises a ValidationError with a clear, structured description of every field that failed — not just the first one.
from datetime import date
from typing import Optional
from pydantic import BaseModel, Field, field_validator
class Author(BaseModel):
name: str
email: Optional[str] = None
class Book(BaseModel):
title: str = Field(min_length=1, max_length=300)
author: Author
publish_date: date
pages: int = Field(gt=0)
isbn: str
@field_validator("isbn")
@classmethod
def isbn_must_be_13_digits(cls, v: str) -> str:
digits = v.replace("-", "")
if not digits.isdigit() or len(digits) != 13:
raise ValueError("ISBN must contain exactly 13 digits")
return v
# This validates, coerces the string date, and constructs cleanly
book = Book(
title="Designing Data-Intensive Applications",
author={"name": "Martin Kleppmann", "email": "mk@example.com"},
publish_date="2017-03-16", # string → date, coerced automatically
pages=616,
isbn="978-1-4920-3259-5"
)
print(book.model_dump_json(indent=2))
Notice the nested Author model inside Book. Pydantic validates nested objects recursively, which maps cleanly onto Elasticsearch’s nested field type. The publish_date field receives a string and returns a proper Python date object — the same coercion that prevents the date-as-string problem mentioned in the introduction. And the custom validator for isbn runs after the type check, adding business-rule enforcement without any extra framework.
From Pydantic Model to Elasticsearch Mapping
One of the most immediately practical benefits of the Pydantic-Elasticsearch pairing is that your model’s type information can drive index mapping creation, eliminating the need to maintain two parallel schema definitions. Rather than writing a Pydantic model for validation and a separate Elasticsearch mapping for storage — and keeping them in sync manually — you derive the mapping programmatically from the model.
The traditional approach, used by many teams before the official integration existed, is to write a mapping translator function that walks the Pydantic field types and produces the corresponding Elasticsearch field types. The type correspondence is straightforward for most common types:
| Python / Pydantic type | Elasticsearch mapping type | Notes |
|---|---|---|
str | text or keyword | Use keyword for exact-match / aggregation fields |
int | integer or long | long for large IDs |
float | float or double | |
bool | boolean | |
datetime / date | date | Format must be set; avoid dynamic inference |
Nested BaseModel | nested or object | Use nested when querying sub-fields independently |
list[str] | keyword (array) | ES arrays are implicit — same field type |
The mapping translator pattern means that when a developer adds a field to the Pydantic model, the index mapping updates on the next deployment cycle rather than requiring a separate schema migration. Furthermore, because Pydantic’s model_json_schema() method produces a full JSON Schema document — compliant with JSON Schema Draft 2020-12 — teams that need to share schema definitions across services or generate API documentation get that for free as a side effect.
The Official BaseESModel Integration (Elasticsearch 9.x)
The integration between Pydantic and Elasticsearch has formalised significantly since the release of the Python Elasticsearch client 9.2.0, which introduced native Pydantic support through a new base class: BaseESModel (and its async counterpart AsyncBaseESModel). This removes the need for custom mapping translators entirely and provides a seamless bridge between your Pydantic model definition and the Elasticsearch Document DSL.
With BaseESModel, you replace BaseModel as the parent class and add an inner Index class to specify the target index name. Standard Pydantic field annotations continue to work exactly as before, and you can additionally use Elasticsearch-specific DSL annotations inside Annotated type hints to control exactly how each field is indexed — for example, marking a string as a Keyword for exact-match queries rather than the full-text-analysed default.
from typing import Annotated
from pydantic import BaseModel, Field
from elasticsearch import dsl
from elasticsearch.dsl.pydantic import AsyncBaseESModel
# Inner models remain plain Pydantic BaseModel classes
class Phone(BaseModel):
type: Annotated[str, dsl.Keyword()] = Field(default="Home")
number: str
class Person(AsyncBaseESModel):
name: str
email: Annotated[str, dsl.Keyword()] # exact-match, no analysis
age: int = Field(ge=0, le=150)
main_phone: Phone
other_phones: list[Phone] = []
class Index:
name = "people"
# The model behaves as a normal Pydantic model everywhere
person = Person(
name="Elena Papadopoulos",
email="elena@example.com",
age=34,
main_phone={"type": "Mobile", "number": "+30 210 1234567"},
)
# But it also knows how to talk to Elasticsearch
# person._doc → the generated Document class for index operations
# person.to_doc() → converts to an ES document
# Person.from_doc(hit) → reconstructs a Person from an ES search hit
The BaseESModel approach is important for several reasons beyond convenience. Because the class is still a valid Pydantic model, it works in FastAPI request/response schemas, in test fixtures, and in any other context where BaseModel would be used. There is no parallel object hierarchy to maintain. You define the data contract once, and it serves both the validation layer and the storage layer.
Requires: pip install elasticsearch[async] version 9.2.0 or later. The AsyncBaseESModel class is available in the elasticsearch.dsl.pydantic module. For synchronous applications, use BaseESModel from the same module.
Community Libraries: ESORM and Pydastic
Before the official integration existed, the Python community developed several Elasticsearch ORM libraries built on top of Pydantic. Two of the most actively maintained are worth knowing, particularly for teams on older Elasticsearch versions or those wanting higher-level abstractions on top of the official client.
ESORM (installable as pyesorm) is a fully asynchronous Elasticsearch ODM that extends Pydantic’s BaseModel with automatic index creation, CRUD operations, bulk context managers, nested document support, optimistic concurrency control, and TypedDict helpers for query and aggregation building. It is tested against Elasticsearch 7.x, 8.x, and 9.x and Python 3.8 through 3.13. For teams that want an Active Record-style interface rather than a manual mapping layer, ESORM is the most feature-complete option.
Pydastic takes a lighter approach — it provides simple CRUD operations and dynamic index support for use cases where you want a thin, predictable wrapper around the official client rather than a full ORM. Both libraries reinforce the same fundamental pattern: a Pydantic model as the authoritative schema definition, with Elasticsearch as the downstream storage target.
Pydantic v2 Validation Performance vs Alternatives (relative ops/sec, higher is better)
Practical Patterns for Production Pipelines
Disable Dynamic Mapping on Your Index
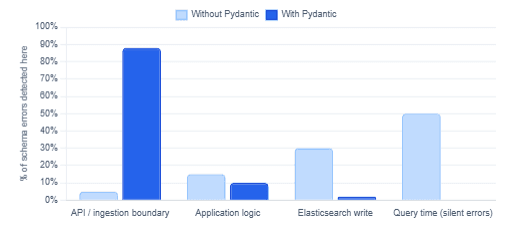
The first production decision to make when combining Pydantic with Elasticsearch is to disable or control dynamic mapping on the index. Dynamic mapping — where Elasticsearch infers field types from the first document it receives — is a source of subtle bugs in any pipeline that processes heterogeneous data. Because Pydantic already guarantees document shape before data reaches the cluster, dynamic mapping becomes unnecessary. Setting dynamic: strict on the index mapping means any document that contains a field not in your mapping will be rejected outright, surfacing schema mismatches at write time rather than at query time. This is the right production default for a Pydantic-backed pipeline.
Validate at the Boundary, Not Inside Elasticsearch
A common antipattern is to ingest raw documents into Elasticsearch and rely on post-ingestion validation or query-time filtering to handle bad data. Pydantic makes this antipattern unnecessary. The ValidationError that Pydantic raises on a malformed document is rich, structured, and actionable — it tells you exactly which field failed, why, and what value was received. Wrapping ingestion in a try-except block that catches ValidationError and routes bad documents to a dead-letter queue is a far more maintainable approach than defensive querying. It also means your Elasticsearch index stays clean, which reduces the cost and complexity of maintaining search relevance.
Use model_dump(mode="json") for Indexing
When sending a Pydantic model instance to Elasticsearch for indexing, always use model.model_dump(mode="json") rather than model.model_dump(). The default model_dump() returns native Python types — including datetime objects, Decimal instances, and UUID objects — that the Elasticsearch client cannot serialise directly. The mode="json" argument converts all values to JSON-compatible primitives first, producing a plain dictionary that the client accepts without additional serialisation logic.
from elasticsearch import Elasticsearch
es = Elasticsearch("http://localhost:9200")
# Correct: serialise to JSON-safe dict before indexing
doc = book.model_dump(mode="json")
es.index(index="books", id=book.isbn, document=doc)
# Incorrect: will fail on datetime fields
# es.index(index="books", document=book.model_dump())
Schema Evolution and Index Aliases
Over time, your Pydantic models will evolve. Fields will be added, renamed, or removed. In Elasticsearch, certain field type changes — such as changing a text field to a keyword — require a full index reindex rather than a simple mapping update. The cleanest way to handle this is through index aliases: maintain a versioned index (books-v1, books-v2) and use an alias (books) to abstract the current version from your application. When a breaking schema change is needed, reindex from the old version to the new one, update the alias, and application code continues reading and writing to the stable alias name. Pydantic’s explicit field definitions make it straightforward to track which version of the model corresponds to which index version, because the model itself is the source of truth.
Where Schema Errors Are Caught — Without vs. With Pydantic
Plugging into FastAPI: The Full Stack
In practice, the most common architecture that combines Pydantic and Elasticsearch also includes FastAPI as the API layer — which is unsurprising given that FastAPI is built on Pydantic internally. In this stack, the same Pydantic model serves three roles simultaneously: it is the FastAPI request body schema (with automatic OpenAPI documentation), the validation layer for incoming documents, and the schema definition for the Elasticsearch index. This single-model approach eliminates the category of bugs that arise from inconsistency between how an API documents a field, how Python validates it, and how Elasticsearch stores it.
The flow is clean: a POST /books endpoint accepts a Book model as its request body. FastAPI validates the incoming request against the model automatically. If validation passes, the handler calls model_dump(mode="json") and indexes the document. If validation fails, FastAPI returns a structured 422 response with Pydantic’s validation error detail — before any database operation occurs. On the read side, search results from Elasticsearch are passed through Book.model_validate(hit["_source"]), giving you a typed Python object rather than a raw dictionary.
When the Combination Is the Right Choice
| Use case | Pydantic + ES a good fit? | Key reason |
|---|---|---|
| Full-text search over validated documents | Strong fit | Validation upstream + full-text search downstream |
| High-throughput ingestion pipelines | Strong fit | Pydantic v2 validation overhead is negligible at scale |
| FastAPI + Elasticsearch API service | Strong fit | Single model for request schema, validation, and index |
| Schema-enforced log or event aggregation | Strong fit | Dead-letter queue for invalid events at ingestion |
| Simple key-value or relational storage | Overkill | PostgreSQL or Redis likely more appropriate |
| Purely transactional workloads (ACID required) | Wrong tool | Elasticsearch is not ACID-compliant; use a relational DB |
What We Learned
Pydantic and Elasticsearch address complementary problems that appear together in nearly every real-world Python data pipeline. We covered why dynamic Elasticsearch mapping is a liability in production and how Pydantic’s type-annotated models eliminate the root cause — bad data entering the cluster — rather than patching it after the fact. We walked through the practical setup, from defining nested BaseModel classes with field validators to using model_dump(mode="json") correctly for indexing.
We examined the official BaseESModel integration introduced in the Elasticsearch 9.2.0 Python client, which makes the pairing first-class: a single class definition that serves as a Pydantic model, a FastAPI schema, and an Elasticsearch document template simultaneously. We also covered production patterns — disabling dynamic mapping, validating at the boundary, and managing schema evolution through index aliases. The combination is particularly powerful in FastAPI-based services, where the same Pydantic model drives request validation, OpenAPI documentation, and Elasticsearch index structure. Together, the two tools enforce a principle that is easy to state and hard to maintain without the right primitives: your data should be valid by the time it is stored, and your storage schema should be derived from the same definition that enforces that validity.
