Why teams adopt microservices, event sourcing, and CQRS without the conditions that make them work — and what those conditions actually are.
In the 1940s, Melanesian islanders built bamboo airstrips and wooden control towers, hoping to attract the cargo planes they had watched land during World War II. They replicated every visible detail. What they lacked was any understanding of the supply chain behind the planes. Software architecture has a version of this problem — and it is far more widespread than the industry admits.
The pattern is well-documented in anthropology but almost never applied to software: organisations copy the visible artefacts of successful architectures — the service boundaries, the message buses, the separate read and write models — without replicating the organisational size, team structure, traffic scale, and operational maturity that made those choices rational in the first place. Netflix’s architecture makes sense for Netflix. The same architecture in a twelve-person team running a B2B SaaS product is overhead masquerading as sophistication.
Moreover, this is not simply a mistake made by junior engineers. It is a structural problem in how the industry transmits architectural knowledge. Understanding it requires looking at three things: the specific gravity of the Java enterprise world, the actual conditions that justify each major pattern, and the conference-talk pipeline that systematically amplifies complexity at scale.
1. The Cargo Cult Analogy
Richard Feynman coined the phrase “cargo cult science” in his 1974 Caltech commencement address to describe research that mimics the outward appearance of the scientific method without its substance. The researchers wore headphones, ran experiments, published papers. But they were missing what Feynman called “a kind of scientific integrity” — the willingness to ask whether the ritual was actually generating knowledge, rather than simply resembling knowledge generation.
The software equivalent is strikingly similar. A team reads about how Uber decomposed its monolith into hundreds of microservices and achieved massive scale. They note the service boundaries, the API gateway, the distributed tracing setup. They replicate the topology. What they miss is the sequence: Uber built a monolith first, scaled it until the monolith’s costs became undeniable, had hundreds of engineers to staff the resulting services, and built years of operational tooling before the decomposition made economic sense. The bamboo airstrip looks right. The supply chain is absent.
“Microservices are a solution to a problem you probably don’t have yet. The problem is organisational, not technical.”— Martin Fowler & Sam Newman, MicroservicePremium
The Complexity Premium: Monolith vs. Microservices at Different Team Sizes
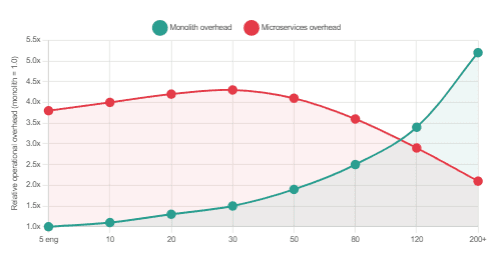
As the chart illustrates, the operational overhead of microservices is disproportionately high at small team sizes. The crossover point — where the distributed architecture starts paying for itself — does not arrive until a team is large enough to dedicate distinct ownership to individual services, build shared infrastructure, and absorb the cognitive cost of distributed debugging. For most startups and mid-size companies, that crossover never comes.
1.1 The Actual Conditions That Justify Microservices
Use microservices when…
- Independent deployment frequency is a real bottleneck
- Services have genuinely divergent scaling requirements
- Team topology already maps to distinct domains
- You have dedicated platform capacity to own the infrastructure
- You have experienced the pain of a monolith at scale
- Polyglot requirements are real, not aspirational
Do not use microservices when…
- Your team is fewer than ~30–40 engineers
- You are pre-product-market fit
- Your bottleneck is feature velocity, not deployment throughput
- You have no observability infrastructure
- The domain model is still being discovered
- You are doing it because Netflix does
2. Event Sourcing: Power With a Price
Event sourcing is one of the more genuinely powerful patterns in distributed systems design. Instead of storing the current state of an entity, you store the sequence of events that produced that state. As a result, you gain a complete audit log, the ability to replay history, and a natural basis for event-driven integration between services.
The problem is that event sourcing imposes a substantial operational and cognitive overhead that is only justified in a narrow set of contexts. Greg Young, who did more than anyone to popularise the pattern, has been notably direct about this in his later writing: event sourcing is appropriate when you genuinely need the audit trail — financial systems, healthcare records, legal workflows — or when temporal queries are a core product requirement. It is not appropriate as a default persistence strategy, yet that is precisely how it is frequently adopted.
Furthermore, event sourcing compounds with microservices in a way that is particularly dangerous. Each individually justified pattern multiplies the complexity of the other. Distributed sagas, eventual consistency, event schema evolution, snapshot strategies, event store infrastructure — these are non-trivial engineering problems. Teams that adopt both patterns simultaneously often discover that they have built a distributed system that is harder to understand, harder to debug, and harder to change than the monolithic CRUD application they replaced.
Microservices + Event Sourcing + CQRS is not three patterns — it is a combinatorial explosion of failure modes, operational concerns, and cognitive load. Each pattern is hard. Each pair is harder. All three together require a level of organisational and engineering maturity that most teams will never reach, and should not aspire to until the simpler approach has provably failed.
3. CQRS: When Read/Write Separation Earns Its Keep
Command Query Responsibility Segregation (CQRS) — separating the models used to read data from those used to write it — is a pattern with a legitimate home in a specific class of problems. When read and write workloads have radically different shapes, different consistency requirements, or different scale characteristics, maintaining a single unified model creates genuine friction. In that context, CQRS is a clean solution.
However, in the vast majority of applications, the read and write models are naturally aligned. A user profile is written through one form and read in one view. Separating those concerns into independent models, separate data stores, and an asynchronous synchronisation mechanism introduces a consistency lag and an operational dependency that provides no benefit whatsoever. Martin Fowler’s own description of the pattern includes a warning that is worth quoting directly: “CQRS is a pattern that I see regularly misused.”
4. The Conference-Talk Pipeline
Perhaps the most structurally important cause of cargo-culting is one that receives very little analysis: the selection bias inherent in the conference-talk pipeline. Consider who gives architecture talks at major software conferences: senior engineers and architects from large organisations. They were selected to speak because their problems were interesting and their solutions were impressive. Their problems are, by definition, not representative of the median team in the audience.
Furthermore, conference talks have a natural narrative arc that favours the complexity of the solution over the specificity of the problem. A talk titled “How We Scaled to 10 Million Users Using Event Sourcing” is more compelling than one titled “How We Ran a Reliable CRUD App For Five Years and Never Needed Event Sourcing.” The former gets submitted and accepted. The latter describes the experience of the majority of software teams in the world.
Adoption vs. Appropriate Use: Where These Patterns Actually Belong

This creates a systematic distortion: the solutions most widely transmitted through the community are solutions to problems that the majority of the community does not have. As a result, the knowledge pipeline is not neutral. It is structurally biased toward the architectural choices of large, operationally mature organisations — and away from the simpler, more appropriate choices that smaller teams actually need.
| What the Talk Presents | What It Leaves Out | Who It Actually Applies To |
|---|---|---|
| “We decomposed into 200 microservices” | 5 years of monolith pain; a 300-person platform team | Teams >150 engineers with a proven scale bottleneck |
| “Event sourcing gave us full audit trails” | The regulatory requirement that mandated it; the 2-year migration | Fintech, healthcare, legal — domain-specific |
| “CQRS let us scale reads independently” | The 100:1 read/write ratio that created the imbalance | High-traffic read-heavy systems with divergent models |
| “Our event-driven architecture decoupled our teams” | The org restructuring that preceded it; event schema governance | Large orgs with team autonomy as a strategic goal |
5. The Actual Decision Framework
The antidote to cargo-culting is not scepticism of complexity per se — it is a discipline of asking what specific problem this pattern solves, and whether you have that problem right now. That sounds obvious, but it is routinely skipped in practice, particularly when a pattern has achieved cultural momentum and adoption feels like the default choice.
A useful heuristic, articulated by Fowler’s “Monolith First” principle: you should not introduce a distributed or event-driven architecture until you can point to a specific, measurable pain point that the simpler architecture is producing. Not a hypothetical future pain point. Not a pain point that Netflix had. A pain point your team is experiencing right now, concretely.
| Pattern | Justified When | Team Threshold | Prerequisite Maturity |
|---|---|---|---|
| Microservices | Deployment independence is a real bottleneck; teams own distinct domains | ~30–50+ engineers | CI/CD pipeline, full observability, service mesh |
| Event Sourcing | Audit log is a core requirement, or temporal queries are a product feature | Any — but domain-specific | Event store infrastructure; schema evolution strategy |
| CQRS | Read/write models are genuinely divergent in shape or scale | Medium–large (10:1+ read ratio) | Clear consistency requirements; async sync infrastructure |
| Modular Monolith | Almost always — until the above conditions are demonstrably met | 1–50 engineers | Basic CI/CD; standard observability |
The modular monolith deserves particular emphasis here because it is almost never the subject of a conference talk and is therefore severely under-represented in the community’s awareness. A well-structured modular monolith — with clear domain boundaries, enforced module interfaces, and a disciplined dependency graph — provides most of the organisational benefits of microservices at a fraction of the operational cost. It also preserves the option value to decompose later, when the conditions actually warrant it.
Indeed, the architecture that best positions a small team for future scale is not one that preemptively adopts the patterns of large-scale systems. It is one that maintains clarity, enforces boundaries, and makes the eventual migration tractable when — and only when — the time comes. Building bamboo airstrips does not make planes land. Building a clean codebase does.
6. What We Have Learned
Throughout this article, we have traced the cargo cult problem from its anthropological roots through to its specific manifestations in software architecture. We started with the Feynman analogy: the gap between visible artefacts and the underlying conditions that give them value. We then explored why the Java enterprise ecosystem is particularly susceptible — through framework-first culture, large-organisation dominance of publishing, and the conflation of architectural complexity with professional seniority.
We examined each of the three major patterns in turn. Microservices are justified by organisational scale and deployment bottlenecks — not by the desire to appear modern. Event sourcing is justified by genuine audit or temporal query requirements — not as a default persistence strategy. CQRS is justified by demonstrably divergent read/write models — not by the fact that it sounds sophisticated. The compound complexity of all three together is warranted only in a narrow slice of organisations, and that slice does not include most of the teams in any given conference audience.
Finally, we identified the conference-talk pipeline as a structural amplifier of the problem — one that selects for the architectural decisions of large, operationally mature organisations and transmits them to audiences whose problems are entirely different. The antidote is not a rejection of complexity in the abstract. It is the discipline of asking, for any given pattern: what specific problem am I solving, and can I point to it concretely right now? If the honest answer is no, the bamboo airstrip should stay on the drawing board.

amazing