Platform Engineering in Practice: Building an Internal Developer Platform Without the Hype
Most articles on IDPs read like vendor brochures. This one doesn’t. Here’s what an internal developer platform actually needs — and what you can safely ignore.
Why platform engineering is having its moment
If you’ve attended any DevOps conference in the last two years, you’ve heard it: platform engineering is the future. And honestly? The numbers back that up. But before we get swept away by the momentum, it’s worth asking why this trend is happening now — and what’s driving real adoption versus vendor marketing.
The short answer is that DevOps worked too well. “You build it, you run it” made total sense in small teams. But as organisations scaled past 50 or 100 engineers, something broke. Developers were suddenly responsible not just for writing code, but for understanding Kubernetes network policies, configuring CI pipelines, managing Vault secrets, setting up Prometheus dashboards, and handling cloud IAM permissions. That cognitive load became unsustainable.
The real triggerResearch from Spotify’s developer productivity team found that engineers in DevOps-mature organisations were spending30–40% of their timeon infrastructure tasks entirely unrelated to business logic. The State of DevOps Report 2025 confirmed that organisations with high developer cognitive load had40% longer lead timesfor changes. That’s what platform engineering is solving.
Consequently, the market has responded. Platform engineering is now firmly mainstream — and the data, for once, is genuinely striking.

Furthermore, the market value tells its own story. According to Virtue Market Research, the IDP market was valued at $8.24 billion in 2025 and is projected to reach $23.90 billion by 2030 — a 23.7% compound annual growth rate. So yes, the hype is backed by real numbers. However, that’s precisely why you need to be careful: where there’s this much money, there are a lot of vendors willing to oversell you.
Platform engineering adoption rate over time
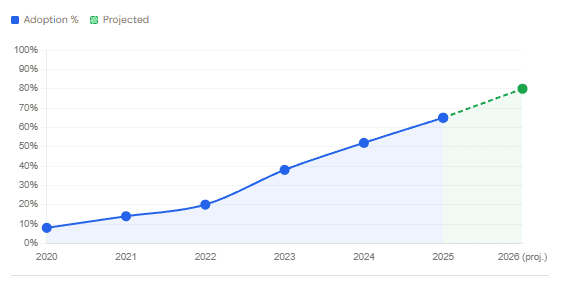
What an IDP actually is — and isn’t
Here’s something that trips up a lot of teams right from the start: the platform is not the portal. Yet a surprising number of organisations kick off an IDP project by deploying Backstage and calling it done. That’s like building the car dashboard and forgetting to install the engine.
The distinction matters enormously. The Internal Developer Platform (IDP) is the underlying engine: the automation, the infrastructure, the CI/CD pipelines, the secret management, the golden paths. The Internal Developer Portal is the front door — the UI where developers interact with all of that. One is the plumbing; the other is the tap.
A common anti-pattern“Platform implementation should begin with a solid back end, not the front end,” says Luca Galante, core contributor at Platform Engineering. Too many teams do it backwards: they spend three months polishing a Backstage UI and then discover there’s nothing meaningful wired up behind it.
So, to put it plainly: an IDP is a self-service layer that lets developers provision environments, deploy services, observe their applications, and manage dependencies — without raising a ticket or waiting on another team. The whole point is reducing cognitive load and eliminating bottlenecks. If your platform still requires Slack approvals for basic operations, it isn’t working yet.
Platform engineering vs. DevOps: what’s actually different?
This is worth clarifying because there’s genuine confusion here, and vendors have made it worse. Platform engineering isn’t DevOps renamed, nor is it a replacement for DevOps culture. It’s better understood as a structural response to the scaling problem that DevOps creates when it grows past a certain size.
| Dimension | DevOps | Platform Engineering |
|---|---|---|
| Primary focus | Breaking silos between dev and ops | Reducing developer cognitive load at scale |
| Audience | All engineers share ops responsibilities | Dedicated platform team serves devs as customers |
| Scales well to | Teams of ~10–50 engineers | Teams of 50–5,000+ engineers |
| Main artefact | CI/CD pipelines, automation scripts | Internal Developer Platform with golden paths |
| Success metric | Deployment frequency, MTTR | Developer experience score, lead time, cognitive load |
| Mindset | Cultural movement | Product management discipline |
In practice, the two coexist. DevOps culture is still the foundation — platform engineering is just what it looks like when it grows up.
What your IDP genuinely needs
Rather than listing every capability a vendor might pitch, let’s focus on what actually moves the needle. Based on real-world implementations and the patterns documented by Google, Spotify’s Backstage team, and others, an IDP needs these core components — and in roughly this order of priority.
1. Golden paths, not golden cages
A golden path is an opinionated, well-tested route for building and deploying an application. It handles the boring stuff automatically — repository creation, CI pipeline setup, namespace provisioning, monitoring configuration — so a developer can go from idea to running service without touching five different tools. The critical word, though, is opinionated, not mandatory. Engineers who need to deviate should be able to — they just take on additional complexity consciously. Remove the escape hatches, and you’ll lose adoption fast.
2. Self-service environment provisioning
This is often the single biggest win. If spinning up a staging environment still requires a Jira ticket and a two-day wait, you haven’t built a platform — you’ve built a form on top of the old process. True self-service means a developer can run a single command or click a button and get an isolated, properly configured environment within minutes. The underlying infrastructure handles IAM roles, networking, database setup, and expiry automatically.
npx create-sandbox --template node-express --ttl 48h
The command above is illustrative of the experience you’re building toward — one command, isolated VPC, pre-configured database, auto-expiry. The exact tooling (Terraform, Pulumi, Crossplane) is secondary to the experience.
3. A software catalog
New engineers should be able to understand what services exist, who owns them, what their dependencies are, and where the documentation lives — without asking anyone. A software catalog solves this. Backstage’s catalog is the most widely adopted open-source option, but Port, Cortex, and others offer strong alternatives.
4. Observability by default
Instead of making developers configure Prometheus, Grafana, and log aggregation for every new service, the platform should wire this up automatically. Every service deployed through your golden path should emit metrics, traces, and logs without any extra developer steps. OpenTelemetry has become the de-facto standard for this, with trace-first design now baked into most modern IDP blueprints.
5. Security and compliance guardrails — not gates
The word “guardrail” is deliberate here. Security should prevent developers from making dangerous mistakes by default, not block them from moving fast. Embedding Open Policy Agent at the admission controller level, pre-configuring secret rotation, and auto-scanning container images at build time are all guardrails. Requiring a security review ticket for every deployment is a gate — and it will break your platform’s adoption.
The 7-concept ruleCognitive load research (Miller’s Law) tells us that when a task requires holding more than 7 concepts in working memory simultaneously, errors spike and velocity drops. Deploying a new microservice at a typical company without an IDP can require 12+ concepts: Kubernetes manifests, Helm chart syntax, CI pipeline YAML, Docker builds, secret management, Terraform provisioning, service mesh config, log aggregation setup, and more. Your platform’s job is to get that below 7.
Where developer time goes — with and without an IDP
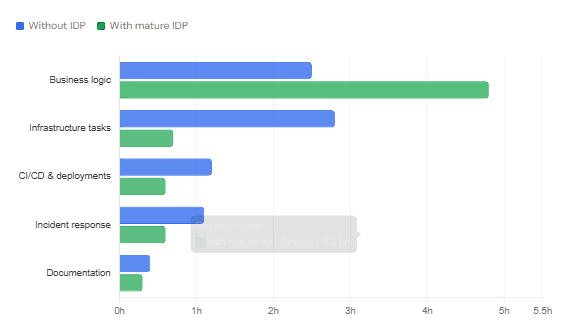
The traps most teams fall into
Here’s the uncomfortable truth: most IDP initiatives fail not because the technology is wrong, but because of how teams approach the problem. According to Platform Engineering’s analysis, the failure mode is almost never technical incompetence. It’s usually one of these.
Building everything at once
The “big bang” approach — designing the perfect platform architecture before writing a single line — is consistently cited as the most expensive mistake. Netflix, Spotify, and Rabobank all converge on the same advice: start small, instrument early, expand based on evidence. Microsoft’s platform engineering guidance explicitly warns against this pattern. Start with one golden path for your most common service type. Get it right. Then add the next one.
Treating it as an infrastructure project, not a product
This is subtle but critical. An infrastructure project has a deadline and a launch date. A product has a roadmap, a backlog, user feedback loops, and an owner who talks to customers weekly. Your developers are the customers of your IDP. If the platform team isn’t sitting with product engineers regularly — or isn’t measuring developer satisfaction — you’re building in a vacuum. As InfoWorld reports, “embracing a product manager mindset is key.”
“Give the teams some ownership — don’t push them to adopt.”— Tom Barkan-Benkler, Director of Product Management at Spotify. At Spotify, 100% of engineers use Backstage because engineers can write plugins for it.
Top-down mandates
Forcing adoption through policy rather than value is a reliable way to breed resentment. Developers will route around a platform they don’t trust or find frustrating — through shadow tooling, manual scripts, or just asking someone with more access. Instead, make the golden path the easiest path. If following the platform is genuinely faster than going around it, adoption takes care of itself.
Over-engineering too early
Don’t build a PaaS. You’re not Heroku. Build targeted abstractions for your specific needs, and wait until you have at least three instances of the same repeated pattern before abstracting it. CodeIntelligently’s research puts it well: “The companies shipping fastest in 2026 aren’t the ones with the best engineers. They’re the ones whose platforms let good engineers focus on what they were hired to do.”
Measuring the wrong things
Tracking feature counts — “we shipped 14 new capabilities this quarter” — is meaningless. What matters is lead time, deployment frequency, change failure rate, developer satisfaction (via NPS surveys), and portal adoption rates. An unmeasured IDP cannot be improved, and Security Boulevard’s analysis notes that low adoption of specific capabilities almost always signals a usability or communication problem worth investigating immediately.
Tooling landscape at a glance
Rather than telling you which tool to pick — that depends entirely on your stack, team size, and existing infrastructure — here’s an honest overview of the major options and what they’re actually good at. The key principle: choose tools that solve your current problems, not the problems you might have in three years.
| Tool / Layer | What it covers | Best for | Watch out for |
|---|---|---|---|
| Backstage | Developer portal, software catalog, scaffolding | Large orgs with dedicated platform teams | Heavy to maintain; needs strong back end |
| Port | Portal + scorecards + self-service actions | Mid-size teams wanting faster setup | SaaS dependency; pricing at scale |
| Cortex | Service catalog, reliability scorecards, ownership | SRE-heavy teams focused on service health | Less strong on self-service provisioning |
| Crossplane | Infrastructure provisioning via Kubernetes CRDs | Kubernetes-native environments | Steep learning curve; complex debugging |
| Pulumi | Infrastructure as code with real programming languages | Multi-cloud with developer-friendly IaC | More expressive than Terraform; state management |
| Argo CD | GitOps continuous delivery for Kubernetes | GitOps backbone — almost universal | Kubernetes-only; pair with Argo Workflows for pipelines |
| OpenTelemetry | Vendor-neutral observability instrumentation | Everyone — standard for traces/metrics/logs | Collector configuration complexity |
One data point worth noting: 67% of 2025 respondents cite GitOps as their delivery pattern of choice, and 93% of organisations plan to continue or increase GitOps use. That means Argo CD or Flux will almost certainly feature in your stack regardless of everything else. Additionally, 47.4% of platform teams in 2025 operate on lean annual budgets under $1 million, which means open-source frameworks aren’t just philosophically appealing — they’re practically necessary.
On AI and your IDPThe DORA 2025 report found something striking: organisations with fragmented tooling and no coherent internal platform saw AI coding tools amplify their existing dysfunction — incidents per PR increased by 242.7% in organisations using AI without robust control systems. In other words, your platform maturity is now the floor on which every AI investment stands. Build the platform first, then layer on AI.
How to measure whether it’s working
Before wrapping up, it’s worth spending a moment on metrics — because this is where a lot of otherwise well-built platforms lose executive support. The challenge is that the right metrics for a platform aren’t the same as the right metrics for a product or a deployment pipeline.
The most effective platform teams track across three dimensions: developer experience, delivery performance, and business impact. Importantly, DORA 2025 research found that the platform capability most correlated with positive developer experience is simply giving “clear feedback on the outcome of my tasks” — meaning logs, diagnostics, and deployment status exposed through the portal. That’s a surprisingly low bar, and yet many teams miss it.
| Metric | What it measures | Target direction | How to collect |
|---|---|---|---|
| Lead time for changes | Time from commit to production | ↓ Lower | CI/CD pipeline data |
| Deployment frequency | How often teams deploy to production | ↑ Higher | Deployment logs / portal data |
| Change failure rate | % of deployments causing incidents | ↓ Lower | Incident tracking (PagerDuty, etc.) |
| Developer NPS | Would devs recommend the platform? | ↑ Higher | Monthly dev survey |
| Portal adoption rate | % of eligible actions done through the IDP | ↑ Higher | Portal analytics |
| Environment provisioning time | Time from request to usable environment | ↓ Lower | Self-service action timing |
| Time on non-core work | Hours/day spent on infra vs. business logic | ↓ Lower | Developer time surveys |
Pick three or four of these to start with and track them consistently. Avoid the trap of tracking everything at once — it leads to paralysis and makes it harder to communicate progress to stakeholders. As a practical starting point, lead time for changes, deployment frequency, and developer NPS give you a solid triangle of delivery speed, reliability, and experience.
What we’ve learned
After reviewing the research, the real-world case studies, and the honest post-mortems from teams who’ve built IDPs — both successfully and unsuccessfully — a few things stand out clearly.
- Platform engineering is real and backed by strong adoption numbers, but the hype has outpaced the practice. Most teams are still mid-journey, not at the finish line.
- The IDP is the engine, the portal is the dashboard — and too many teams build the dashboard first. Start with the golden paths and self-service provisioning before worrying about the UI.
- Cognitive load reduction is the core metric. If your platform doesn’t make a developer’s daily work measurably simpler, it isn’t working — regardless of how technically impressive it is.
- Treat it as a product, not a project. Developers are your customers. Talk to them weekly, track their NPS, and evolve the platform based on what they actually need.
- Start small, prove value, expand. The teams with the best outcomes consistently began with one golden path and grew from there. Big-bang builds consistently fail.
- Guardrails beat gates. Security and compliance should be embedded in the happy path, not bolted on as approvals. The moment your platform requires a ticket, it’s already losing to the workarounds.
- AI amplifies platform maturity — for better or worse. A fragmented toolchain plus AI coding tools is a dangerous combination. Get your platform foundations right before layering AI on top.
