For years, Java and serverless computing seemed fundamentally incompatible. The JVM’s startup characteristics—loading classes, initializing the runtime, warming up JIT compilation—made Java functions painfully slow to start. While Python and Node.js functions would initialize in tens of milliseconds, Java functions routinely took 5-10 seconds for cold starts. This made Java impractical for serverless workloads where functions might start and stop dozens of times per hour.
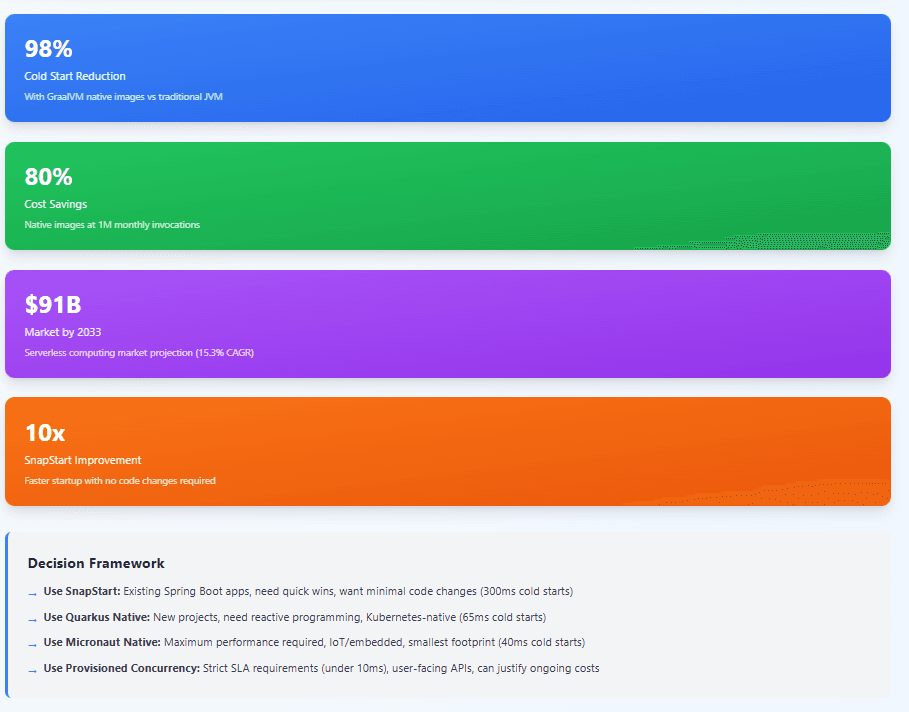
That narrative has changed dramatically. The serverless computing market, valued at $25.25 billion in 2025, is projected to reach $90.94 billion by 2033, growing at a 15.3% CAGR. Java is no longer sitting on the sidelines of this growth. Through a combination of innovations—AWS Lambda SnapStart, GraalVM native compilation, and cloud-native frameworks like Quarkus and Micronaut—Java has become not just viable but competitive for serverless deployments.
The transformation centers on solving Java’s fundamental challenge: startup time. AWS Lambda SnapStart can reduce cold starts from several seconds to sub-second performance, often achieving 200-400ms initialization times. GraalVM native images eliminate the JVM entirely, producing binaries that start in under 100ms. Combined with frameworks designed specifically for serverless constraints, Java developers can now build functions that rival Node.js and Python in responsiveness while leveraging Java’s type safety, tooling, and enterprise ecosystem.
This isn’t just about making Java work in serverless—it’s about making it excel there. Organizations with significant Java investments can now extend their applications into serverless architectures without language fragmentation or rewriting codebases. The question is no longer whether to use Java for serverless, but how to do it effectively.
Understanding Serverless Architecture Patterns for Java
Serverless architecture fundamentally differs from traditional application deployment in ways that particularly impact Java applications. In traditional deployments, your Java application starts once and runs continuously, amortizing startup costs across hours or days of operation. In serverless, your function might start fresh for each request during low-traffic periods, making initialization overhead critical.
The typical lifecycle of a Java Lambda function consists of three phases: the INIT phase where Lambda downloads your code, starts the Java runtime, and executes static initializers; the INVOKE phase where your handler method processes requests; and eventual SHUTDOWN when Lambda determines the execution environment is no longer needed. For Java functions without optimization, the INIT phase dominates latency, often consuming 80-90% of first-request time.
This leads to the first architectural principle for serverless Java: minimize initialization work. Every bean you instantiate, every dependency you inject, every connection pool you configure during startup adds to cold start time. Traditional Spring Boot applications might initialize dozens of beans, scan multiple packages for components, and establish database connections before handling a single request. This approach proves untenable in serverless where initialization happens frequently.
Successful serverless Java patterns often involve lazy initialization. Instead of connecting to a database during INIT, establish the connection on first use. Rather than loading all application context, load only what’s needed for the specific function. This might mean having multiple focused functions instead of one large application with multiple endpoints. Each function does one thing and initializes only what that thing requires.
Event-driven patterns particularly suit serverless Java. A function triggered by an S3 upload processes that file and publishes results to an SNS topic. Another function consumes from a Kinesis stream and writes to DynamoDB. These patterns work because each function has a clear, bounded responsibility and the asynchronous nature of events tolerates the occasional cold start better than synchronous APIs.
For synchronous use cases like REST APIs, the pattern shifts toward keeping functions warm through traffic. When a function receives regular invocations, Lambda reuses the execution environment, eliminating cold starts. This creates a natural division: high-traffic endpoints suit serverless deployment, while rarely-accessed functionality might perform better in traditional always-on containers where initialization cost is amortized.
API composition emerges as another important pattern. Rather than building monolithic Lambda functions that serve multiple endpoints, create focused functions mapped to specific API Gateway routes. This allows independent scaling, deployment, and optimization of each endpoint. The trade-off involves increased operational complexity managing more functions, but tools like AWS SAM and the Serverless Framework handle this orchestration effectively.
Cold Start Mitigation: Making Java Competitive
The cold start problem has defined Java’s relationship with serverless computing, but recent solutions have transformed the landscape. Understanding these approaches and when to use each is crucial for building responsive serverless Java applications.
AWS Lambda SnapStart
Lambda SnapStart represents AWS’s infrastructure-level solution to Java cold starts. When you publish a function version with SnapStart enabled, Lambda fully initializes your function, takes a Firecracker microVM snapshot of the complete memory and disk state, encrypts it, and caches it across multiple availability zones. When your function needs to scale, Lambda restores from this snapshot instead of initializing from scratch.
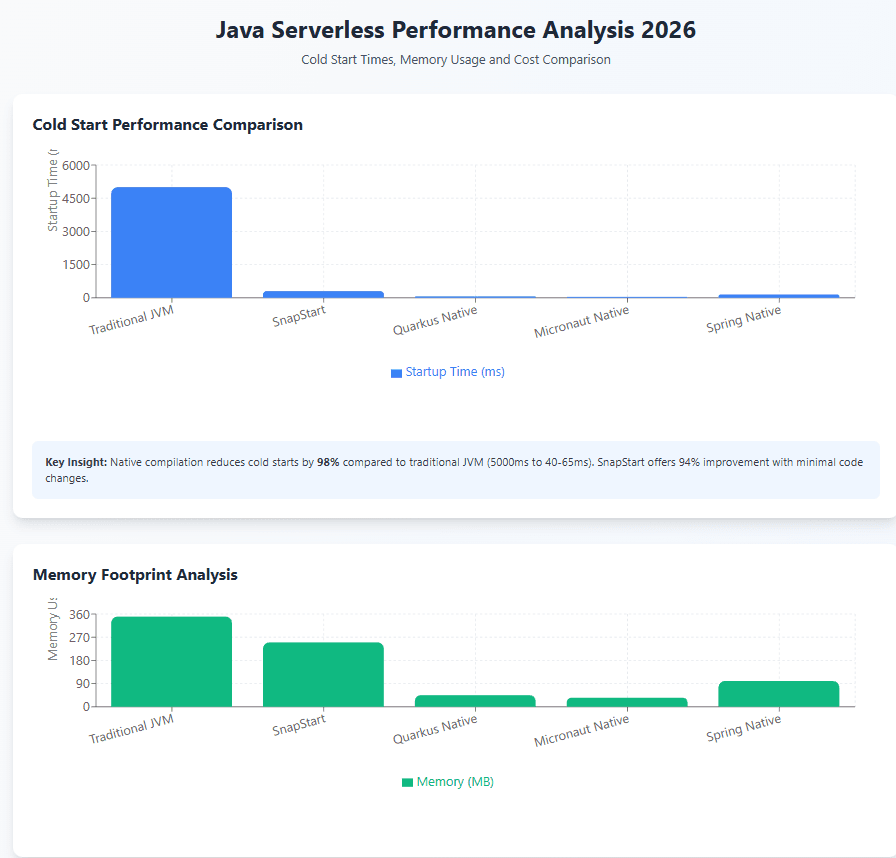
The performance impact is substantial. Traditional Java Lambda functions might initialize in 3-10 seconds depending on dependencies and complexity. With SnapStart, that drops to 200-400ms for most applications—a 10x improvement that brings Java within range of Node.js and Python cold starts. For a Spring Boot application with moderate dependencies, Coveo Engineering reported reducing initialization from several seconds to just 10% of the original time.
However, SnapStart introduces new considerations around state management. Since the snapshot captures everything in memory at initialization time, any state generated during INIT persists across all function invocations restored from that snapshot. This affects several common patterns:
If your initialization code generates random IDs or cryptographic keys, those values won’t be unique across execution environments restored from the same snapshot. You must regenerate unique values after restoration. Database connections established during INIT will fail when restored because TCP connections can’t survive the snapshot-restore cycle. Network resources need lazy initialization or restoration using the CRaC (Coordinated Restore at Checkpoint) hooks that SnapStart integrates.
Advanced priming techniques can further optimize SnapStart performance. By using the beforeCheckpoint() hook from the CRaC project, you can proactively invoke application endpoints or load classes during the INIT phase before the snapshot is taken. This ensures that JIT-compiled code and initialized resources are captured in the snapshot. AWS research shows this can reduce first-response times by an additional 30-50% beyond basic SnapStart.
GraalVM Native Images
GraalVM takes a radically different approach: eliminate the JVM entirely. Using ahead-of-time compilation, GraalVM analyzes your Java application and compiles it directly to native machine code. The resulting binary starts in tens of milliseconds and uses a fraction of the memory of a JVM-based application.
For serverless deployments, native images solve the cold start problem completely. Functions built with GraalVM and frameworks like Quarkus or Micronaut regularly achieve sub-100ms initialization times. This makes Java competitive with Go or Rust for latency-sensitive serverless workloads. Memory usage also drops dramatically—a native image might use 50MB where the equivalent JVM application uses 200MB, directly reducing Lambda costs.
The trade-off involves limitations and complexity. Native compilation requires closed-world analysis: the compiler must understand all code paths at build time. This makes reflection, dynamic proxy generation, and runtime class loading problematic. While frameworks like Quarkus provide extensive configuration to handle common reflection patterns, applications heavy with dynamic behavior may struggle with native compilation.
Build times also increase substantially. Where a traditional Maven build might complete in minutes, native image compilation can take 5-15 minutes depending on application complexity. This affects development velocity and CI/CD pipeline design. Many teams maintain separate profiles: JVM mode for development with fast iteration, and native mode for production deployment.
Performance characteristics differ between JVM and native modes in subtle ways. The JVM’s JIT compiler optimizes hot code paths over time, potentially achieving better peak throughput for long-running workloads. Native images optimize for startup and consistent performance but may not match JVM peak performance for compute-intensive tasks. For serverless workloads where executions are short-lived, this trade-off usually favors native images.
Provisioned Concurrency
When cold start optimization isn’t enough, Lambda offers provisioned concurrency—pre-initialized execution environments that remain ready to respond. This effectively eliminates cold starts by keeping functions “warm,” but introduces ongoing costs since you’re paying for capacity whether it’s used or not.
Provisioned concurrency makes sense for specific scenarios: user-facing APIs with strict latency SLAs, functions that handle unpredictable bursts where auto-scaling isn’t fast enough, or Java applications that have inherent initialization requirements that can’t be optimized away. The cost calculation is straightforward: compare the cost of provisioned concurrency against the business impact of cold start latency.
For example, a function receiving 1,000 requests per hour with 20% cold starts might see 200 slow responses. If provisioned concurrency costs $15/month and cold starts are causing user abandonment worth more than that, the investment is justified. If cold starts merely add 500ms that users barely notice, SnapStart or native images might be more cost-effective.
Comparison of Cold Start Mitigation Strategies
| Strategy | Startup Time | Memory Overhead | Cost | Development Complexity | Best For |
|---|---|---|---|---|---|
| Standard JVM | 3-10 seconds | High (200-400MB) | Pay per use | Low | Development, non-latency-sensitive workloads |
| SnapStart | 200-400ms | Moderate (150-300MB) | Storage cost only | Low-Moderate | Production Spring Boot, existing JVM apps |
| GraalVM Native | 50-100ms | Low (50-100MB) | Pay per use + build time | High | Latency-sensitive APIs, high scale |
| Provisioned Concurrency | ~10ms (warm) | Variable | Continuous charge | Low | Critical paths, strict SLA requirements |
Performance data from AWS documentation, Coveo Engineering, and framework benchmarks
Framework Choices: Quarkus, Micronaut, and Spring Native
The framework you choose for serverless Java dramatically impacts both development experience and runtime performance. The landscape has evolved from Spring Boot’s dominance toward specialized frameworks designed explicitly for serverless and cloud-native deployment.
Spring Boot with Spring Native
Spring Boot remains the most familiar choice for Java developers, and Spring Native brings GraalVM compilation to the Spring ecosystem. For teams with existing Spring expertise and applications, this path offers the smoothest migration to serverless.
Spring Native’s maturity has improved significantly. Spring Boot 3.x includes native compilation support directly, eliminating the need for separate projects or complex configuration. The framework provides hints and configurations for most common Spring modules, handling the reflection requirements that native compilation demands.
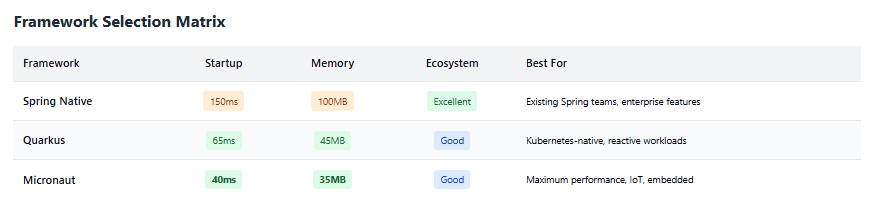
However, Spring Boot’s comprehensive feature set works against it in serverless contexts. A minimal Spring Boot application still carries significant overhead even when compiled to native code. Startup times for Spring Native applications typically land in the 100-200ms range—excellent compared to traditional JVM deployment, but slower than Quarkus or Micronaut’s 50-70ms typical startup.
Memory footprint similarly reflects Spring’s comprehensiveness. Where Micronaut might use 40-60MB, an equivalent Spring Native application might use 80-120MB. For Lambda pricing based on memory allocation, this difference adds up at scale. A function with 1 million invocations per month using 128MB costs significantly more than one using 64MB.
The Spring ecosystem’s breadth provides compensating advantages. Spring Cloud Function abstracts serverless deployments, allowing the same code to run on AWS Lambda, Azure Functions, or Google Cloud Functions with minimal changes. Spring Data, Spring Security, and other Spring modules work in native mode, reducing the learning curve for teams already invested in Spring.
Quarkus: The Kubernetes-Native Framework
Quarkus positions itself as “supersonic subatomic Java,” optimized explicitly for containers, Kubernetes, and serverless deployment. Created by Red Hat, Quarkus embraces both traditional JVM mode and GraalVM native compilation as first-class deployment targets.
Startup performance represents Quarkus’s major strength. Native-compiled Quarkus applications regularly start in 50-70ms, making them competitive with Go for serverless deployment. Memory usage similarly impresses, with minimal applications using 40-50MB. This combination of speed and efficiency translates directly to lower Lambda costs and better user experience.
Developer experience remains strong despite the performance focus. Quarkus provides live coding with instant reload during development—change code and see results immediately without restart. The extension ecosystem covers serverless essentials: REST endpoints, JSON serialization, database access, messaging, and cloud service integration. Extensions use build-time processing to minimize runtime overhead, trading longer build times for faster execution.
The framework particularly excels with reactive programming. While supporting traditional imperative code, Quarkus embraces reactive patterns through integration with Vert.x, Mutiny, and reactive database drivers. For serverless workloads with significant I/O—calling external APIs, querying databases—reactive patterns improve resource efficiency and cost-effectiveness.
Integration with AWS services is comprehensive. Quarkus extensions provide native support for DynamoDB, S3, SQS, SNS, and other AWS services with optimized clients that minimize cold start impact. For Azure and GCP, community extensions offer similar integration, though with less polish than the AWS ecosystem.
Micronaut: Compile-Time Dependency Injection
Micronaut takes compile-time optimization to its logical conclusion. Rather than using reflection for dependency injection, Micronaut processes annotations at compilation time, generating the injection code as regular Java classes. This eliminates one of the JVM’s major initialization overheads.
For serverless deployment, Micronaut’s approach pays dividends. Native-compiled Micronaut applications start in 30-50ms—among the fastest startup times achievable for Java applications. Memory usage falls into the 30-40MB range for minimal applications, allowing deployment on Lambda’s smallest memory configurations.
The framework offers particularly smooth Spring compatibility. Micronaut can consume Spring beans, use Spring annotations, and integrate with Spring libraries. This eases migration for teams wanting serverless benefits without completely abandoning Spring investments. While not a drop-in replacement—some Spring features don’t translate directly—the compatibility reduces the migration barrier significantly.
Micronaut’s ecosystem, while smaller than Spring’s, covers serverless essentials comprehensively. HTTP clients and servers, data access, messaging, cloud integration, and serverless-specific features are all available. The Micronaut Launch generator creates fully-configured projects for Lambda, Azure Functions, and Google Cloud Functions, handling the deployment configuration and packaging automatically.
One interesting Micronaut advantage involves its multi-language support. The same compile-time processing approach works for Kotlin and Groovy, allowing polyglot teams to use their preferred JVM language without sacrificing performance. For organizations with mixed language investments, this flexibility proves valuable.
Framework Performance Comparison
| Framework | Native Startup | Native Memory | JVM Startup | Ecosystem | Learning Curve | Best For |
|---|---|---|---|---|---|---|
| Spring Native | 100-200ms | 80-120MB | 3-5s | Largest | Low (if you know Spring) | Existing Spring teams, enterprise features |
| Quarkus | 50-70ms | 40-50MB | 1-2s | Large | Moderate | Kubernetes-native, reactive workloads |
| Micronaut | 30-50ms | 30-40MB | 500ms-1s | Medium | Moderate | Maximum performance, IoT, embedded |
Based on minimal REST API applications; actual performance varies with application complexity
The choice often comes down to team expertise and performance requirements. Teams already invested in Spring should start with Spring Native unless performance proves inadequate. For new projects prioritizing performance, Quarkus and Micronaut both deliver excellent results, with Micronaut edging ahead on raw startup speed and Quarkus offering better reactive programming support and a larger extension ecosystem.
Cost-Performance Trade-offs
Serverless pricing models create unique optimization opportunities for Java applications. Understanding how cold starts, memory allocation, and execution time interact with pricing helps make informed architectural decisions that balance performance and cost.
Lambda’s pricing has three components: requests ($0.20 per 1M requests), duration (charged per GB-second), and in SnapStart’s case, snapshot storage. The memory you allocate determines both the cost per millisecond and the CPU power available—higher memory means faster execution but higher per-millisecond cost. Finding the optimal memory allocation involves balancing execution speed against memory cost.
For Java applications, this trade-off shifts significantly with optimization approach. Consider a function that processes data from S3, with 1 million invocations monthly:
Traditional JVM (512MB allocated):
- Average execution: 800ms (including 5s cold starts)
- Cold start frequency: 10% (100,000 invocations)
- Monthly cost: ~$25 for duration + $0.20 for requests = $25.20
With SnapStart (512MB allocated):
- Average execution: 600ms (300ms cold starts)
- Snapshot storage: $0.50/month
- Monthly cost: ~$19 + $0.20 + $0.50 = $19.70
Native with Quarkus (128MB allocated):
- Average execution: 200ms (70ms cold starts)
- Monthly cost: ~$5 + $0.20 = $5.20
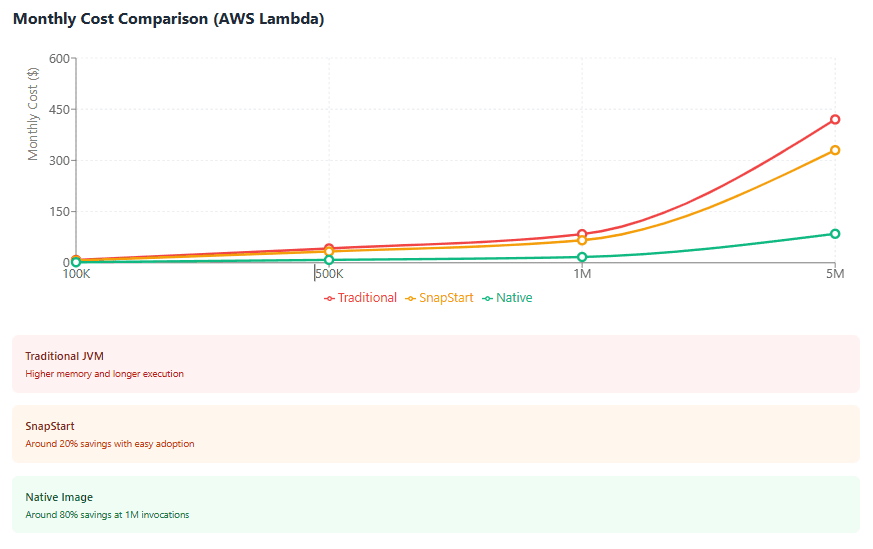
The native approach saves 75% compared to traditional JVM deployment, primarily through lower memory requirements and faster execution. SnapStart provides a middle ground, maintaining compatibility with existing code while improving costs by 20-25%.
These calculations assume straightforward workloads. The picture changes with complexity. Applications requiring large dependencies or extensive initialization might not compile to native images easily, making SnapStart more practical. Conversely, simple functions with minimal dependencies work excellently with native compilation, making that approach optimal despite its development complexity.
Execution patterns also matter significantly. Functions with consistent traffic benefit from execution environment reuse, amortizing cold start costs across many invocations. A function receiving requests every few seconds rarely experiences cold starts, making traditional JVM deployment more viable. Functions with sporadic traffic—maybe processing nightly batch jobs or responding to occasional user actions—experience frequent cold starts, making optimization more valuable.
Provisioned concurrency pricing adds another dimension. Keeping even one execution environment warm costs approximately $13/month for a 1GB function. This makes sense only when cold starts demonstrably harm user experience and optimization techniques don’t suffice. The calculation becomes: is the business impact of cold starts worth more than $13/month? For consumer-facing APIs, probably yes. For internal batch processing, probably no.
Memory allocation deserves careful consideration for Java functions. Many developers over-allocate memory to ensure functions don’t hit OOM errors, but Lambda charges for allocated memory whether used or not. Monitoring actual memory usage—visible in CloudWatch logs—often reveals significant over-allocation. A function allocated 1GB that uses 400MB wastes 60% of its memory budget. For native images with predictable memory usage, precise allocation becomes easier.
Some cost optimizations prove counterproductive. Extremely aggressive memory reductions might save allocation costs but increase execution time enough that duration charges exceed the savings. The break-even point varies by workload, but generally, memory configurations below 256MB for Java functions rarely optimize total cost unless using native images.
State Management in Stateless Functions
Serverless’s stateless execution model creates interesting challenges for Java applications that traditionally rely on in-memory state. Understanding how to manage state—both temporary and persistent—proves crucial for building reliable serverless applications.
The fundamental rule is that execution environments are ephemeral and shared. Lambda might reuse an execution environment for multiple invocations, or it might create fresh ones. Your code can’t depend on previous invocations having run in the same environment. This eliminates patterns like storing request counts in memory, maintaining connection pools with specific configurations, or caching computed values across requests.
For transient state within a request, standard Java patterns work fine. Local variables, method parameters, and single-request scoped objects all function normally. The restriction applies to state that spans invocations.
Connection pooling illustrates the challenge. Traditional Java applications establish a database connection pool during startup and reuse connections across many requests. In Lambda, this pattern works but requires adaptation. Initialize the connection pool as a static variable outside your handler method—Lambda reuses the execution environment, your connection pool persists across invocations in that environment. However, include logic to detect stale connections and reconnect, as execution environments might be frozen between invocations.
public class DatabaseHandler implements RequestHandler {
private static final DataSource dataSource;
static {
// Initialized once per execution environment
dataSource = createDataSource();
}
@Override
public APIGatewayProxyResponseEvent handleRequest(APIGatewayProxyRequestEvent event, Context context) {
// Reuses dataSource across invocations in same environment
try (Connection conn = dataSource.getConnection()) {
// Use connection
}
}
}
With SnapStart, connection pooling requires additional care. Connections established during INIT become invalid after snapshot restoration. Use the CRaC hooks to close connections before snapshot and reinitialize them after restoration, or implement lazy initialization that establishes connections on first use after restoration.
For persistent state, serverless Java applications need external storage. DynamoDB provides low-latency key-value storage ideal for session data, user preferences, or application state. S3 works for larger objects like uploaded files or generated reports. RDS or Aurora Serverless v2 suit relational data, though connection management becomes more complex.
DynamoDB’s single-digit millisecond latency makes it particularly suitable for serverless. A function can query DynamoDB, process results, and respond in 50-100ms total, maintaining the responsiveness serverless promises. The pay-per-request pricing model also aligns with serverless’s consumption-based cost structure.
Caching patterns adapt to serverless constraints. Rather than maintaining an in-process cache, use ElastiCache or DynamoDB DAX for distributed caching accessible across function invocations. Alternatively, leverage CloudFront to cache API responses at the edge, reducing function invocations entirely for cacheable requests.
Session management requires external storage. For APIs serving web applications, store session data in DynamoDB or ElastiCache with the session ID in the authentication token. The function retrieves session data, processes the request, and updates session state as needed. This works but adds latency compared to in-memory sessions. For high-traffic APIs, consider whether sessions are necessary—stateless authentication with JWTs might serve better.
State initialization presents another consideration. If your function needs to load configuration, fetch secrets, or retrieve reference data, do this outside the handler in static initializers. Lambda reuses this data across invocations in the same execution environment. With SnapStart, this data becomes part of the snapshot, making it instantly available on invocation.
Event-Driven Design Patterns
Serverless architectures thrive on event-driven patterns where functions react to events rather than waiting for requests. For Java applications, this shift from request-response to event processing requires rethinking application structure, but enables powerful, scalable architectures.
The S3 event pattern demonstrates the simplest form: a function triggers when files are uploaded to S3. The function receives an event describing the upload, processes the file, and completes. This pattern works excellently for document processing, image transformation, data import—any workflow that starts with file upload.
public class S3EventHandler implements RequestHandler<S3Event, String> {
private static final S3Client s3Client = S3Client.create();
@Override
public String handleRequest(S3Event event, Context context) {
event.getRecords().forEach(record -> {
String bucket = record.getS3().getBucket().getName();
String key = record.getS3().getObject().getKey();
// Process file
processFile(bucket, key);
});
return "Processed " + event.getRecords().size() + " files";
}
}
Stream processing with Kinesis or DynamoDB Streams enables real-time data processing. Your function receives batches of events and processes them, often writing results to another service. This pattern scales automatically—as stream throughput increases, Lambda scales your function to keep up. For Java applications, this means building focused, efficient processors that handle batches quickly.
SNS fanout patterns allow one event to trigger multiple functions. An order placement might trigger inventory updates, payment processing, and notification sending—all as independent functions processing the same event. This decoupling enables independent development and scaling of each concern.
SQS integration provides reliable asynchronous processing with built-in retry logic. Functions poll SQS queues, process messages, and delete them on success. Failed messages automatically retry with configurable backoff, and ultimately move to dead letter queues for investigation. For Java applications processing background jobs, SQS provides production-grade reliability without custom retry logic.
EventBridge enables complex event routing based on event content. Rules filter and route events to appropriate functions, allowing sophisticated workflows. A payment event might route to different functions based on payment amount, customer tier, or payment method. This pattern works particularly well for Java applications where different payment types require different processing logic.
The saga pattern manages distributed transactions across multiple functions. When a business process spans multiple services—booking a flight, hotel, and car rental—each step becomes a function. Success events trigger the next step; failure events trigger compensating transactions that undo previous steps. While more complex than traditional transactions, sagas provide eventual consistency in distributed, event-driven architectures.
For Java specifically, these patterns benefit from strong typing and serialization libraries. Events from S3, SNS, SQS arrive as JSON that needs parsing. Jackson or Gson handle this, but frameworks like Quarkus and Micronaut provide integrated JSON binding that maps events to Java objects automatically. This reduces boilerplate and errors from manual parsing.
Error handling in event-driven architectures requires thought. Unlike synchronous APIs where you return error responses, failed event processing often means the event needs reprocessing. Lambda’s retry behavior varies by event source: S3 events don’t retry (the object remains), Kinesis retries until successful or the record expires, SQS retries based on queue configuration. Understanding these behaviors helps design robust error handling.
Idempotency becomes critical. Since events might be delivered multiple times, your function must handle duplicate processing gracefully. For Java applications, this typically means checking DynamoDB for a processing record before handling an event, and writing that record atomically with the business logic. This prevents duplicate processing even if events arrive multiple times.
Integration with Cloud-Native Services
Modern cloud platforms provide managed services that integrate seamlessly with serverless functions, enabling Java applications to leverage capabilities that would be complex to build and maintain. Understanding these integrations helps design effective serverless architectures.
API Gateway fronts Lambda functions as REST or WebSocket APIs, handling authentication, rate limiting, request validation, and response transformation. For Java functions, API Gateway integration removes the need for web frameworks—you receive an event object containing request details and return a response object. This simplification suits serverless’s single-purpose function model.
API Gateway’s request validation prevents invalid requests from invoking your function, reducing wasted invocations and costs. JSON schema validation ensures requests match expected structure before Lambda even starts. For Java applications that would otherwise spend CPU cycles on input validation, this provides value.
Custom authorizers enable sophisticated authentication. A Lambda authorizer function validates tokens, queries user databases, and returns authorization context. Subsequent function invocations receive this context, eliminating repeated authentication logic. This pattern works well for Java applications with complex authorization rules or multiple authentication providers.
DynamoDB streams enable change data capture. When items in a DynamoDB table change, streams deliver events to Lambda functions describing the changes. For Java applications, this enables reactive architectures where mutations in one table trigger processing in other systems. An order table update might trigger inventory adjustment, analytics updates, and notification sending—all through stream processing.
Step Functions orchestrate complex workflows involving multiple Lambda functions. Rather than encoding workflow logic in function code, Step Functions provide declarative workflow definitions with branching, parallel execution, and error handling. For Java applications with multi-step business processes, this separation of workflow logic from business logic simplifies both.
Step Functions particularly help with long-running processes. A document processing workflow might take minutes or hours depending on document size. Breaking this into steps—upload validation, text extraction, classification, storage—allows each step to complete within Lambda’s execution time limits while Step Functions manages the overall workflow.
SQS and SNS provide messaging infrastructure. SQS offers reliable queue-based messaging with visibility timeout, dead letter queues, and FIFO guarantees when needed. SNS provides pub-sub messaging where multiple subscribers receive each message. For Java applications, these services eliminate the need to run message brokers, reducing operational complexity while maintaining reliability.
Parameter Store and Secrets Manager handle configuration and secrets. Functions retrieve configuration at runtime, allowing environment-specific settings without code changes. For Java applications, this pattern enables deployment of the same artifact across dev, staging, and production with environment-appropriate configuration.
CloudWatch Logs and X-Ray provide observability. Every Lambda invocation logs to CloudWatch automatically, and X-Ray traces requests across multiple services. For Java applications, instrumentation is straightforward—the AWS SDK includes automatic tracing, and frameworks like Quarkus and Spring Cloud provide X-Ray integration.
Aurora Serverless v2 offers on-demand relational database capacity. Unlike traditional RDS instances that run continuously, Aurora Serverless scales capacity based on load, even scaling to zero during inactivity. For Java applications with variable database load, this provides cost savings while maintaining PostgreSQL or MySQL compatibility.
What We’ve Learned
Serverless Java has transformed from impractical to competitive. The combination of AWS Lambda SnapStart, GraalVM native compilation, and frameworks designed for serverless deployment enables Java applications to achieve startup times of 50-400ms depending on optimization approach. This makes Java viable for latency-sensitive serverless workloads while preserving Java’s type safety, tooling, and ecosystem advantages.
Cold start mitigation strategies each serve different needs. SnapStart provides 10x improvement with minimal code changes, ideal for existing Spring Boot applications or teams wanting to adopt serverless with familiar tools. GraalVM native images deliver the best performance—under 100ms startup—but require development workflow adjustments and framework support. Provisioned concurrency eliminates cold starts entirely but introduces ongoing costs, making it suitable only for critical paths with strict SLA requirements.
Framework choice significantly impacts both development experience and runtime performance. Spring Native offers the smoothest path for existing Spring teams, though with moderate performance. Quarkus and Micronaut deliver superior startup times and memory efficiency, with Micronaut achieving the fastest startups (30-50ms) and Quarkus providing the richest reactive programming support. The choice depends on team expertise, performance requirements, and architectural patterns.
Cost optimization in serverless Java extends beyond code efficiency. Memory allocation, execution duration, and cold start frequency all impact costs. Native-compiled functions can reduce costs by 70-80% compared to traditional JVM deployment through lower memory requirements and faster execution. However, development complexity and build times increase, creating a trade-off between operational costs and development velocity.
Event-driven architecture patterns prove particularly well-suited to serverless Java. Processing S3 uploads, consuming from streams, reacting to database changes—these patterns scale automatically and align with serverless’s strengths. The challenge lies in managing state across stateless invocations, which Java applications address through external storage in DynamoDB, S3, or managed databases.
Integration with cloud-native services enables Java functions to leverage capabilities like API Gateway, Step Functions, and managed databases without operating infrastructure. For organizations with Java investments, this removes the barrier between existing Java applications and modern cloud-native architectures. You can build new functionality in serverless Java while maintaining existing applications, gradually evolving toward cloud-native patterns.
The serverless computing market’s growth to $90.94 billion by 2033 reflects real value—reduced operational overhead, automatic scaling, and pay-per-use pricing. Java’s participation in this growth, once doubtful, now seems assured. Organizations can leverage Java’s enterprise readiness, extensive libraries, and developer expertise in serverless architectures that previously required different languages.
The remaining challenges involve tooling maturity and operational practices. Native compilation workflows need refinement, framework support for various AWS services continues evolving, and observability tools must adapt to serverless’s distributed nature. But the fundamental question—can Java work effectively in serverless?—has been definitively answered. The focus now shifts to how to do it well, which frameworks to choose, and when native compilation justifies its complexity.
For teams considering serverless Java in 2026, the path forward is clear: start with SnapStart for existing applications or when rapid adoption matters, evaluate Quarkus or Micronaut for new development prioritizing performance, and consider native compilation when startup time or memory efficiency directly impacts costs or user experience. The tools exist, the frameworks have matured, and the cloud providers have invested in making Java viable. What remains is applying these capabilities to business problems where serverless’s benefits—automatic scaling, operational simplicity, consumption-based pricing—provide genuine value.
