I spent four years as a true believer. I gave conference talks. I drew the boxes and arrows on whiteboards. I convinced three different engineering teams to break their monoliths apart. This is my honest account of what actually happened — and what I think we should all say out loud more often.
1. An Honest Confession First
I should tell you what kind of article this is not. It is not a takedown of microservices as a concept. Netflix still runs them. Uber still runs them. Amazon’s main e-commerce platform runs on thousands of them. The architecture is not broken. In the right context, with the right team size and the right organizational structure, microservices are the correct answer.
What this is, instead, is an account of how the industry fell in love with a pattern that solved Amazon’s problems and then applied it to teams that had nothing in common with Amazon. It is about how “microservices” became a career signal, a conference circuit fixture, and an architectural default — used not because the problem called for it, but because it felt modern. It is about the specific, predictable ways that goes wrong. And it is about the architecture I switched to after experiencing three of those failures personally.
The shift is happening everywhere, even if quietly. Industry analysis from late 2025 reveals 42% of organizations are merging microservices back into larger units, with debugging taking 35% longer in distributed systems according to a DZone 2024 study. Most teams will not announce the reversal publicly. Admitting you are consolidating feels like admitting failure. But the GitHub commit histories and cloud billing dashboards tell the story that the conference talks do not.
2. What Microservices Actually Promised
To understand why so many teams adopted microservices in the first place, you have to remember the context of the early 2010s. Martin Fowler and James Lewis published their foundational microservices article in 2014. Netflix had been evangelizing their approach for years. Amazon had gone through their famous API mandate from Jeff Bezos. There was genuine, hard-won evidence that decomposing large monoliths into independent services enabled faster deployment and better team autonomy — at scale.
The promises were specific and, in the original context, real. First, independent deployment: teams could ship their service without coordinating a release with every other team. Second, independent scalability: if your payment service needed ten times more capacity than your user profile service, you could scale them independently rather than scaling the whole application. Third, technology freedom: different services could use different languages, databases, and runtimes. Fourth, fault isolation: a bug in one service would not bring down the entire system.
These are genuinely valuable properties. The problem was not the promises. The problem was the fine print: these benefits only materialize at a specific scale of team and complexity, and they come with a tax that the conference talks consistently understated.
“Microservices are the tools that work at high scale. But whether to use them over a monolith has to be made on a case-by-case basis.”— Amazon Prime Video engineering blog, 2023 — the post that started the industry conversation
3. The Hidden Tax Nobody Told You About
Every architecture has a cost. A monolith’s cost is well understood: as it grows, a poorly structured one becomes a big ball of mud where changes have unexpected ripple effects, where the entire application must be deployed to ship any change, and where no component can scale independently. The industry talked about these costs constantly and correctly.
What got consistently underplayed were the costs of microservices — costs that do not appear on the initial whiteboard diagram but show up in the third month of operation.
The Operational Tax — What Actually Shows Up in Production
- Network latency stacks up. Each service boundary adds milliseconds. A user action that touches five services in sequence — authentication, account, product, inventory, order — might add 40–80ms of pure network overhead per request. This does not appear in any architecture diagram.
- Distributed tracing is a part-time job. When something goes wrong, a stack trace no longer tells you what happened. You need to correlate logs across five repos, five deployment pipelines, and five separate log aggregation streams. Teams spend 35% more time debugging microservices than modular monoliths. That number sounds abstract until it is your incident response at 2am.
- Local development becomes a fiction. Running a single service locally is easy. Running the five services your feature depends on — each with their own environment variables, ports, Docker containers, and mock dependencies — is a project in itself. Junior engineers spend more time in kubectl than in their actual service code.
- Data consistency requires distributed transactions. In a monolith, changing two tables in the same database operation is trivially atomic. In a distributed system, keeping two services’ data consistent requires saga patterns, event sourcing, eventual consistency, or compensation logic. None of these are easy. All of them are expensive to build and reason about.
- Cloud costs scale with architecture, not just traffic. Every service needs compute, logging, monitoring, and a deployment pipeline. The per-service infrastructure overhead accumulates. A fifteen-service system might cost three times as much to run as an equivalent modular monolith, before you have a single user.
- Shared logic becomes a versioning nightmare. Code you used to call as a function becomes a versioned API endpoint. Changing that shared logic now requires coordinated releases across every consumer. Or you run multiple versions simultaneously. Neither is free.
Operational Overhead: Microservices vs. Modular Monolith at Different Team Sizes
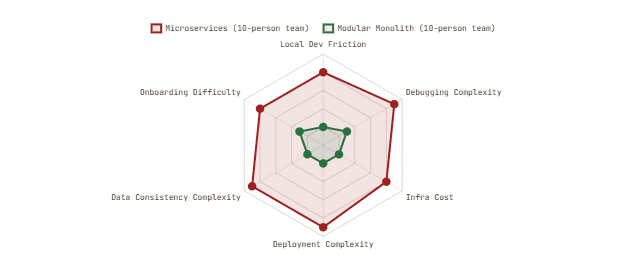
Individually, each of these costs is manageable. Collectively, at a team that has ten developers and one DevOps engineer, they consume most of the engineering capacity. Experts have reached consensus in 2025: below 10 developers, monoliths perform better and Docker adds complexity without clear benefits. That consensus arrived, unfortunately, after most of those ten-developer teams had already built their service mesh.
4. The Case Studies That Changed My Mind
The theoretical costs were always visible if you looked for them. What shifted the broader conversation was a series of high-profile cases where teams who had gone all-in on microservices publicly described reversing course. The one that got the most attention was Amazon’s own — and its details are worth being precise about.
Case Study- Amazon Prime Video Monitoring Service — 90% Cost Reduction by Consolidating
In May 2023, Prime Video’s engineering team published a blog post describing how they rebuilt their video quality analysis service. The original architecture used AWS Step Functions for orchestration and Lambda for individual processing steps — a classic serverless microservices approach. It had a critical flaw: Step Functions was a bottleneck because the service performed multiple state transitions for every second of the stream, quickly reaching account limits. It also hit a hard scaling ceiling at around 5% of expected load.
The team realized the distributed approach wasn’t bringing a lot of benefits in their specific use case, so they packed all the components into a single process, eliminating the need for S3 as intermediate storage for video frames.
The resulting “monolith” is technically still a microservice in the broader Prime Video architecture — it is one independently deployable, independently scalable service within a much larger distributed system. Adrian Cockcroft, former AWS VP, described it as “clearly a microservice refactoring step,” not a return to monolith. The lesson is not “monoliths over microservices.” The lesson is that serverless-function-per-step granularity was the wrong decomposition for this specific workload.

Case Study- 47 Services Consolidated — 63% Cloud Cost Reduction
A team presenting at SpringOne 2024 described migrating 47 microservices back into a modular monolith. Their deployment time went from 40 minutes to 6 minutes. Their cloud costs dropped 63%. Their team reported being happier. The 47-service architecture had been built over three years and made sense on paper — each service had a clear bounded context. But the inter-service call graph had become so dense that no service could be deployed without checking whether the change broke three others. The team was running microservices but experiencing the worst property of a monolith: tight coupling. They had built what the industry calls a distributed monolith.
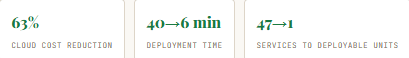
Case Studies- Segment, InVision, and the Istio Control Plane
Peer-reviewed academic literature identified four documented cases of switching back from microservice to monolith: the Istio control plane, the Amazon Prime Video monitoring service, Segment, and InVision. Cost was the most common reason across all four cases. Segment’s migration was particularly instructive: they had built a message routing platform as a set of separate services and found that the deployment complexity and operational overhead of maintaining dozens of services was consuming more engineering time than the actual product features those services delivered. InVision similarly consolidated after finding that their microservices had created more coordination overhead than team-size-adjusted autonomy gains.
5. The Worst of Both Worlds: The Distributed Monolith
The failure mode that appears most consistently in migration post-mortems is not microservices per se — it is the distributed monolith. This is the architecture that results when you decompose a system into separate deployable services, but fail to achieve loose coupling between them. You end up with all the operational overhead of distributed systems — separate deployments, network calls, distributed tracing, eventual consistency — and none of the benefits: the services still need to be deployed in a specific order, still share database tables, and still break each other when APIs change.
The distributed monolith is surprisingly easy to build and surprisingly hard to recognize from the inside. The team believes they have microservices. They have separate repos and separate CI pipelines. But if you draw the dependency graph and it looks like a bowl of spaghetti rather than a clean tree, you have a distributed monolith.
In complex real-world systems, defining domain boundaries can be challenging, especially when data has traditionally been conceptualized in a specific way. When models are deeply linked, this leads to data and functions split between services, causing multiple inter-service calls and data integrity issues. Many migrations stop at the data stage because of the complexity, but successful data migration is key to realizing the benefits of microservices. Most teams do not stop at the data stage — they proceed with the service decomposition and leave the data coupling in place. The result is the distributed monolith.
Martin Fowler, who wrote the most-cited documentation on microservices patterns, was also explicit about the downside — a fact that gets less attention than his architecture diagrams. He coined the phrase “Microservice Premium” — the substantial cost and complexity that microservices add — and warned clearly: “Don’t start with microservices, unless you have a very good reason. Most organizations that benefit from microservices got there by first building a monolith and then breaking it up.”
Architecture Complexity vs. Team Size — The Sweet Spot Shifts

6. What I Actually Replaced Them With
When I say I stopped using microservices, I do not mean I went back to unstructured monoliths. The problem with the ball-of-mud monolith was real. The answer is the modular monolith — a single deployable unit that is internally structured into clearly-bounded, loosely-coupled modules, each with well-defined interfaces, and each potentially extractable into an independent service later if the business case justifies it.
The modular monolith is not a new idea. It is, in fact, what good object-oriented design always looked like — the application of the same domain-driven design principles that microservices use, applied at the package/module level rather than the service level. What changed is that frameworks now explicitly support this pattern. In the Java ecosystem, Spring Modulith provides structural enforcement of module boundaries: it can detect and fail tests when module boundaries are violated, document module interactions, and generate architecture diagrams automatically.
| Property | Big Ball of Mud Monolith | Microservices | Modular Monolith |
|---|---|---|---|
| Deployment complexity | One unit | N units, N pipelines | One unit |
| Internal coupling | Everything touches everything | Services independent | Enforced module boundaries |
| Network overhead | None — in-process | Every call crosses network | None — in-process |
| Data consistency | ACID transactions trivial | Distributed transactions required | ACID transactions trivial |
| Local dev experience | Clone and run | Complex: need all deps running | Clone and run |
| Debug experience | Single stack trace | Distributed trace across repos | Single stack trace |
| Independent scalability | Scale the whole thing | Scale services independently | Scale the whole thing (for now) |
| Extractable to services later | Very difficult — entangled | Already services | Yes — modules become services cleanly |
| Team autonomy | Everyone blocked by everyone | Teams truly independent | Module ownership, shared deployment |
The trade-off is honest: a modular monolith does not give you independent scalability or full team deployment independence. If you genuinely need those properties — because you have teams of 30+ engineers, or because one part of the system has radically different scaling characteristics from another — then microservices earn their cost. But for the majority of systems, the modular monolith gives you clean architecture, fast local development, simple debugging, cheap infrastructure, and a clear extraction path when you eventually outgrow it.
Spring Modulith, part of the Spring ecosystem since 2023, lets you enforce module boundaries in a Spring Boot application. It provides structural verification tests that fail if one module imports non-public code from another, built-in event publication for async inter-module communication, documentation generation that shows module dependencies, and a clear path to extracting a module as an independent service when the business case arrives. It is the Java-native answer to the modular monolith pattern.
7. When Microservices Are Actually the Right Answer
Being credible about the downsides requires being equally honest about when microservices are genuinely the right choice. There are specific, identifiable conditions under which the benefits outweigh the costs — and teams in those conditions should use them.
Use microservices when…
- You have 10+ engineers per service, with true team autonomy and ownership
- Different components have genuinely divergent scaling requirements (e.g., video encoding vs. user profile lookup)
- You need different technology stacks for different workloads (ML inference in Python, core services in Java)
- Regulatory or compliance reasons require hard data isolation between system components
- You have a mature platform team that can absorb the infrastructure overhead without it touching product teams
- You are at Netflix/Uber scale and team coordination is the real bottleneck
Use a modular monolith when…
- Your team is under 30–50 engineers total
- You are validating product-market fit and need to iterate fast
- Your domain boundaries are not yet stable — they are still evolving with the product
- You do not have a dedicated platform/DevOps team to own distributed infrastructure
- Your scaling requirements are uniform across components
- You are starting a greenfield project and want to keep the option to extract services later
The red flags that mean you probably should not have split yet
- Services frequently need to be deployed together because they share logical changes
- A change to one service requires changes to three others before it goes live
- You have a “shared services” team that is a bottleneck for multiple product teams
- Engineers dread debugging because it always involves reading logs across five systems
- Your services share a database (you have a distributed monolith, not microservices)
- New engineers take months to understand the system because of the distributed complexity
8. What Changed My Mind: Conway’s Law Revisited
The intellectual case for microservices is inseparable from Conway’s Law — the observation by computer scientist Melvin Conway that organizations tend to produce systems that mirror their communication structures. If you have five teams, you tend to build five components. The microservices playbook argued that you should design your team structure and your service boundaries together, so that each team owns a service and can ship independently.
That reasoning is sound — when the team structure and service boundaries are stable. What I underestimated was the cost of the mismatch phase: the period between “we decided to split” and “the teams are actually operating independently.” In my experience, that phase routinely lasted twelve to eighteen months, during which the team was paying the full operational cost of microservices without yet receiving the team autonomy benefits. And in fast-moving product companies, the domain boundaries frequently shifted during that window anyway, making the service decomposition wrong by the time it was complete.
Microservices solve a specific problem: enabling many autonomous teams to work independently on large, stable domains. Most startups and mid-sized companies don’t operate at that scale. For smaller teams, microservices introduce coordination overhead without delivering proportional benefits.
The honest summary of my experience: I used microservices to solve an organizational problem that my organization did not actually have. I had a small, cohesive team that communicated well. The problem I needed to solve was product complexity and code quality — both of which a well-structured modular monolith addresses directly, without the distributed systems tax.
Microservices became a resume checkbox, a signal of “modern” engineering, regardless of actual need. Conference talks pushed distributed systems as inevitable evolution. Blog posts dismissed monoliths as “legacy” without nuance. Consultants sold expensive transformation roadmaps. Developers chose architectures that looked impressive on LinkedIn over what served their product’s needs. This is uncomfortable to read because most of us — myself included — have been guilty of it at some point.
9. What We Have All Learned
The microservices backlash that is quietly happening across the industry in 2025 and 2026 is not a repudiation of the architecture. It is a recalibration of when and why to use it. Microservices are a solution to a specific problem — scaling team autonomy across many independent teams working on large, stable domains. They were never intended as a default starting point, even if a decade of conference talks made them feel like one.
The modular monolith is not a step backward. It is a mature response to years of over-distribution. It gives you clean architecture, enforceable module boundaries, fast feedback loops, simple infrastructure, and a genuine extraction path when you actually need the independence that microservices provide. For greenfield Java projects today, Spring Modulith makes it the technically superior starting point for any team under 50 engineers. The option to extract services later is always available. The option to un-extract them is much harder.
The most important lesson from the case studies — Amazon, Segment, InVision, the 47-service consolidation at SpringOne — is consistent: the cost of the wrong granularity is enormous, and the granularity question is harder than it looks. Martin Fowler’s advice has always been to start with a monolith and extract services when the boundaries are proven. The industry ignored that advice for a decade. The billing dashboards are now making the argument he could not.
