A frank comparison from an engineering standpoint — architecture trade-offs, honest benchmarks, real pricing math, and Java client examples for both.
The “which vector database should I use?” question gets thousands of monthly searches. Every vendor blog post answers it the same way: with benchmarks that happen to favour them, diagrams that make their architecture look elegant, and a pricing table where their tier conveniently wins. This article tries to do the opposite — give you the architectural intuition and honest trade-offs you need to make the decision for your workload.
The two contenders here are pgvector, an open-source PostgreSQL extension that adds vector similarity search to a database you probably already run, and Pinecone, a purpose-built managed vector database. Both solve the same underlying problem. The difference is entirely in how they solve it — and which side of that trade-off matters to you.

First, Understand What You Are Actually Asking
Vector databases store embeddings — high-dimensional float arrays that encode semantic meaning. When you ask a vector database for the “five most similar items to this query,” it performs an approximate nearest-neighbour (ANN) search across potentially millions of vectors. The challenge is doing that in milliseconds without loading every vector into memory for comparison.
Both pgvector and Pinecone solve this with some form of HNSW indexing (Hierarchical Navigable Small World), which organises vectors into a layered graph structure for fast traversal. The difference is in who controls that graph — you, with tunable parameters, or the managed service, with automatic configuration.
The one thing most comparisons miss
Raw query latency is rarely the bottleneck. In a typical RAG pipeline, vector search accounts for less than 20% of total response time. The real questions are operational: how many services do you want to maintain, what does “consistency” mean across your dataset and your vectors, and how does your cost grow with data volume?
Architecture: Where the Real Differences Live
pgvector extends PostgreSQL with a vector data type and index support. This means your embeddings live in the same database as your application data. A query that finds “products semantically similar to this description, uploaded in the last 7 days, by a verified seller” is a single SQL statement with a vector distance operator — no application-level join, no round trip to a separate service. That is the central architectural advantage, and it is genuinely significant for teams with complex filter requirements.
Pinecone, on the other hand, is a separate service optimised entirely for vector workloads. It uses its own proprietary index, handles replication and scaling transparently, and exposes a simple HTTP API. You send vectors in, you query them out. There is no concept of joins, transactions, or relational consistency — nor is there meant to be. Pinecone’s serverless architecture scales the index automatically as your data grows, which is its headline advantage. The trade-off is that your vectors live in a black box you cannot inspect, tune, or self-host.
| Dimension | pgvector | Pinecone |
|---|---|---|
| Hosting model | Self-hosted (or managed via Neon, Supabase, etc.) | Fully managed, no self-hosted option |
| Index algorithm | HNSW or IVFFlat, fully tunable via SQL | Proprietary, no parameter tuning exposed |
| Data co-location | ✓ Vectors sit next to relational data | ✗ Separate service, requires sync |
| Hybrid queries (vector + SQL filter) | ✓ Native SQL — one query | ~ Metadata filters, but no relational joins |
| Recall tuning | ✓ Control m, ef_construction, ef_search | ✗ Not exposed — their docs confirm this |
| Transactional consistency | ✓ ACID — vectors and rows in one transaction | ✗ Eventual consistency within the index |
| Operational burden | Medium — index tuning, memory sizing, backups | Very low — zero infrastructure to manage |
| Vendor lock-in | ✓ Open standard, portable | ✗ Proprietary format, no export path |
Performance: A Realistic Picture at Different Scales
This is where most comparisons go wrong by treating latency as absolute. The honest answer is: it depends heavily on scale, and the crossover point is around 10–50 million vectors.
Below 10 million vectors, pgvector with a properly configured HNSW index queries in 5–20 ms at 95%+ recall — performance that is entirely comparable to Pinecone’s serverless tier. At this scale, pgvector often wins on latency because your queries stay within a single service with no network hop to an external API. Encore’s engineering team, for instance, reported 5–8 ms p95 latency at their scale using pgvector with HNSW.
Above 50 million vectors, the picture shifts. Maintaining pgvector’s performance requires careful tuning of PostgreSQL’s shared_buffers, work_mem, and HNSW parameters — and your instance’s available RAM becomes a hard ceiling for how much of the index stays hot. Pinecone’s architecture is specifically designed to scale past this point without operator intervention. Its latency stays consistent from 1 million to billions of vectors, while pgvector’s degrades unless you continuously right-size the instance.
Query latency vs. dataset size (p95, cosine similarity, 1536-dim)
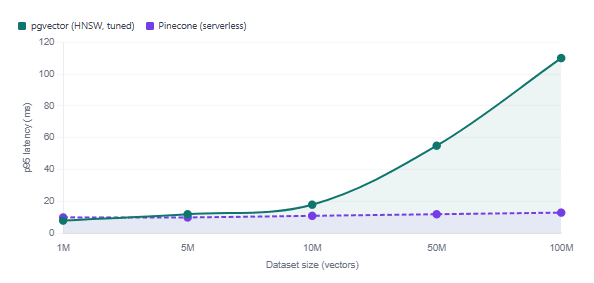
One frequently overlooked detail: Pinecone does not expose HNSW tuning parameters. Their documentation explicitly states that the accuracy/performance trade-off is not user-configurable. With pgvector, you can push recall as high as 0.99 by tuning ef_search — at the cost of slower queries. With Pinecone, you get whatever configuration they chose.
The Pricing Reality
This is the section vendor marketing works hardest to obscure. Here is the clearest way to think about it.
At small scale (<10M vectors): Pinecone’s serverless tier often wins on total cost. You pay only for what you use, there is no instance to provision, and you avoid the DevOps time required to tune and monitor a PostgreSQL deployment. For teams without dedicated database engineers, that hidden labour cost easily flips the equation.
At medium scale (10–100M vectors): Pinecone’s pricing scales roughly linearly with vector count, while pgvector’s cost stays fixed once you have the right instance size. Teams that have migrated workloads from Pinecone to pgvector at this scale have reported 40–60% cost reductions, particularly when using managed PostgreSQL services like Neon or Supabase that eliminate self-hosting overhead.
At large scale (>100M vectors): Self-hosted pgvector becomes cost-competitive but requires significant infrastructure expertise. pgvectorscale (Timescale’s extension built on top of pgvector) is worth evaluating here — it uses a different index type called StreamingDiskANN that is more memory-efficient at very high vector counts.
Estimated monthly cost comparison by vector count
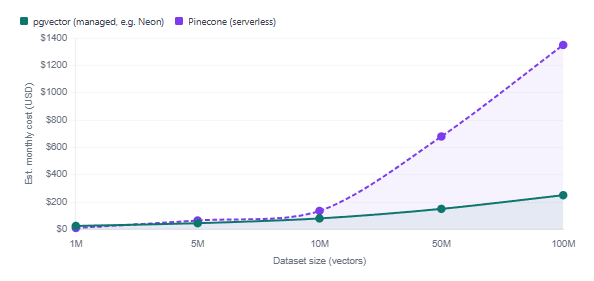
Pinecone’s serverless pricing charges per read unit, and costs scale non-linearly as index size grows — larger indexes require more read units per query. Run a load test at your expected query volume before committing to the platform at production scale.
What This Looks Like in Java
Both options have solid Java integration paths. The code tells the story of the architectural difference better than any diagram.
pgvector with Spring AI
The recommended path for Spring Boot applications is the Spring AI pgvector starter, which wires everything automatically. Add the dependency, configure your application.properties, and the VectorStore bean is ready for injection:
<!-- pom.xml --> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-starter-vector-store-pgvector</artifactId> </dependency>
# application.properties spring.datasource.url=jdbc:postgresql://localhost:5432/mydb spring.ai.vectorstore.pgvector.index-type=HNSW spring.ai.vectorstore.pgvector.distance-type=COSINE_DISTANCE spring.ai.vectorstore.pgvector.dimensions=1536 spring.ai.vectorstore.pgvector.initialize-schema=true
With that in place, storing and querying documents is straightforward Spring code — no SQL required, though you can drop into raw JDBC any time you need a complex hybrid query:
@Service
public class KnowledgeService {
@Autowired
private VectorStore vectorStore;
public void store(List<Document> docs) {
vectorStore.add(docs);
}
public List<Document> search(String query) {
return vectorStore.similaritySearch(
SearchRequest.query(query).withTopK(5)
);
}
}
When you need that SQL superpower — combining vector similarity with relational filters — Spring Data JPA’s vector search support (shipped in Spring Data 4.0, May 2025) lets you write it directly in a repository interface:
// Spring Data JPA vector search — requires Hibernate 6.x + pgvector
interface ArticleRepository extends Repository<Article, Long> {
@Query("""
SELECT a, cosine_distance(a.embedding, :embedding) AS distance
FROM Article a
WHERE a.category = :category
ORDER BY cosine_distance(a.embedding, :embedding)
""")
SearchResults<Article> findSimilarByCategory(
String category,
Vector embedding
);
}
Pinecone with the official Java SDK
Pinecone’s official Java client is available on Maven Central and follows a clean builder pattern. The operational footprint is genuinely minimal — connect, upsert, query:
<!-- pom.xml --> <dependency> <groupId>io.pinecone</groupId> <artifactId>pinecone-client</artifactId> <version>6.0.0</version> </dependency>
import io.pinecone.clients.Pinecone;
import io.pinecone.clients.Index;
Pinecone pinecone = new Pinecone
.Builder(System.getenv("PINECONE_API_KEY"))
.build();
Index index = pinecone.getIndexConnection("my-index");
// Upsert a vector
index.upsert("doc-1", Arrays.asList(0.1f, 0.2f, 0.3f /*, ... */));
// Query top-5 nearest neighbours
var results = index.query(5, Arrays.asList(0.1f, 0.2f, 0.3f /*, ... */));
results.getMatchesList()
.forEach(m -> System.out.println(m.getId() + " : " + m.getScore()));
The two code paths are strikingly different in character. pgvector feels like regular database work — familiar SQL, Spring abstractions, JPA entities. Pinecone feels like an API client — connect, push, pull, done. Neither is intrinsically better. They reflect the different operational worlds the two tools inhabit.
The Decision Framework
After all the above, the honest answer is that the scale breakpoint matters less than most teams think. The majority of applications — documentation search, support ticket classification, product recommendations — operate well under 10 million vectors. At that scale, both tools are fast enough, and the decision comes down to operational preference.
Choose pgvector when
- You already run PostgreSQL in production
- Your dataset stays under 10–50M vectors
- You need vectors and relational data in the same query
- ACID consistency between vectors and rows matters
- You want to own your data with no export risk
- Your team has SQL expertise and infrastructure capacity
- You want to minimise technology sprawl
Choose Pinecone when
- You need production vector search running today
- Your team has no appetite for database operations
- You are scaling past 100M+ vectors and need automatic sharding
- Predictable performance without tuning is a priority
- You are building a prototype and want to move fast
- Your budget is higher but your DevOps headcount is lower
Teams frequently start on Pinecone (fast to prototype) and move to pgvector once their scale and cost trajectory is clear. The reverse — outgrowing pgvector and moving to a dedicated vector store — also happens, though less commonly below 50M vectors. Neither choice is permanent, but plan for the migration cost before you need it.
A Word on pgvectorscale and the Middle Ground
If you like the pgvector model but worry about scaling past a few tens of millions of vectors, it is worth knowing that Timescale’s pgvectorscale extension was built precisely for that gap. It introduces a new index type called StreamingDiskANN that is more memory-efficient than HNSW at very high vector counts, achieved 28x lower p95 latency than Pinecone at 99% recall on a 50M-vector benchmark, and sits entirely within the PostgreSQL ecosystem. It is not a replacement for pgvector — it layers on top of it. For teams sitting in the 10–100M vector range who want to stay on PostgreSQL, it closes most of the performance gap with dedicated vector databases.
What We Have Learned
pgvector wins when simplicity, data co-location, and SQL expressiveness matter more than scale. It is the right default for most backend teams already running PostgreSQL — particularly once you factor in the hidden cost of maintaining a second database service in sync with your primary data. Pinecone wins when you need managed infrastructure with automatic scaling and have no interest in database operations. The real crossover is not a latency benchmark. It is the number of services you want to operate, the scale of your dataset, and how tightly your vector queries are coupled to your relational data. For Java teams, both paths have solid, production-ready clients. Start with pgvector unless you have a specific reason not to — you can always migrate later.
