When SOLID and DRY principles stop protecting your codebase and start actively harming it — and the well-evidenced case that orthodox clean-code doctrine has gone too far.
here is a certain kind of codebase that every senior engineer has encountered at least once. It has beautiful folder structure. Every class is short. Every method has a single responsibility. The interfaces are named with care. The dependency injection container is meticulously configured. And yet, when you try to add a new feature — something that should take an afternoon — you spend two days tracing through seven layers of abstraction, hunting the one place where the actual logic lives.
That codebase followed the rules. It passed the linter. It probably got glowing reviews. And it is, nevertheless, a nightmare to change. Somehow, in the pursuit of clean code, it became the opposite of what clean code promises: flexible, maintainable software.
This article is about how that happens. More specifically, it is about how three of the most widely-taught principles in software engineering — SOLID, DRY, and the broader philosophy of Robert Martin’s Clean Code — carry within them the seeds of their own undoing when applied dogmatically. This is not an argument against good design. It is an argument against orthodoxy — against treating principles as laws rather than heuristics, and against the peculiar social dynamic that turns “best practices” into untouchable dogma.
“Duplication is far cheaper than the wrong abstraction.”
— Sandi Metz, RailsConf 2014
The DRY Trap: When Removing Repetition Creates Coupling
The Don’t Repeat Yourself principle, formulated by Andy Hunt and Dave Thomas in The Pragmatic Programmer, is stated with deceptive simplicity: “every piece of knowledge must have a single, unambiguous, authoritative representation within a system.” Note the word knowledge — not code. That distinction matters enormously, and it is the one most frequently lost in translation.
Hunt and Thomas were talking about eliminating duplicated knowledge — business rules, schema definitions, algorithms. They were not prescribing that any two functions with similar syntax must be merged. That misreading is where most DRY damage comes from.
In practice, however, DRY is almost always applied to syntactic similarity. Two functions happen to contain a for loop with similar structure? Extract a helper. Two classes both open a file? Wrap it. Two API endpoints both validate an email? Abstract it. The result, very often, is that code which was coincidentally similar — but which had independent reasons to change — becomes permanently coupled through a shared abstraction.
Sandi Metz described the damage mechanism precisely in her widely-read 2016 post, The Wrong Abstraction. A developer extracts duplication. The abstraction is correct for that moment. Then requirements change, and the next developer — feeling honour-bound not to break the abstraction — adds a parameter. Then a flag. Then a conditional. Over time, the “shared” function accumulates every special case from every caller until it is no longer an abstraction at all: it is just confusion wearing the costume of one. As Metz puts it, the fastest way forward at that point is backwards — re-inlining the code, removing the abstraction entirely, and starting fresh.
Kent C. Dodds formalised an alternative in his concept of AHA Programming — Avoid Hasty Abstractions. The insight is that the deeper the investment in an abstraction, the more developers resist changing it, even when the abstraction has outlived its usefulness. This is a straightforward instance of the sunk cost fallacy. The abstraction was expensive to create; therefore we keep patching it rather than admitting it was wrong. AHA’s prescription — don’t abstract until you are confident the use cases genuinely share the same reason to change — is a more honest account of how good design actually emerges than DRY’s blanket prohibition on repetition.
What makes codebases hardest to change?

SOLID’s Hidden Costs: Interfaces as a Tax on Readability
SOLID is not five principles. It is five principles of varying quality, applied to varying contexts, whose collective effect on a codebase depends almost entirely on whether the developers using them understand why each one exists — not just what it says.
The Single Responsibility Paradox
The Single Responsibility Principle — a class should have one reason to change — sounds unimpeachable. It is also entirely ambiguous. What counts as a “reason”? At the finest granularity, every function has a single responsibility. At the coarsest, an entire service does. The SRP tells you nothing about where to draw the line, and experienced developers drawing that line independently will draw it in radically different places.
The common failure mode is over-fragmentation: classes so small and so numerous that a single user registration flow requires understanding a dozen of them. Baeldung’s analysis captures it well: a simple CRUD application that manages user data does not need a complex set of interfaces. Excessive abstraction increases the learning curve for new developers and makes debugging harder. The irony is that over-fragmented SOLID code often feels cleaner to the person who wrote it — every unit is small — but is actively harder for anyone else to navigate.
The Open/Closed Principle and the Cost of Predicting the Future
The Open/Closed Principle — software entities should be open for extension but closed for modification — is arguably the most dangerous of the five when misapplied. Its purpose is to prevent modification of stable, working code. Its pathological application is the construction of extension hierarchies for features that will never arrive.
Consider the classic example: a PaymentProcessor that is designed, on day one, with interfaces for every conceivable future payment method — BNPL, crypto, bank transfer, gift cards — because the OCP tells you to make it extensible. The resulting hierarchy is complex, the anticipated payment methods may never materialise, and when a truly novel method appears, the hierarchy is in the wrong shape anyway. As noted on Medium, it is often simpler to refactor the processor when a new method is truly required, rather than preemptively designing for every possibility. YAGNI — You Aren’t Gonna Need It — is in direct tension with OCP, and in fast-moving codebases, YAGNI usually wins for good reason.
“SOLID codebases have low coupling. They are testable. But they are unintelligible. And often not as adaptable as the developers had hoped.”
— NDepend Blog, on common SOLID criticism
Dependency Inversion: When Everything Depends on Everything Else
The Dependency Inversion Principle — depend on abstractions, not concretions — is the one that most reliably produces the “seven layers of indirection” problem. In its correct application, it makes high-level policy independent of low-level detail. In its common misapplication, it produces a codebase where every class depends on an interface that has exactly one implementation, where IoC containers are required just to wire together components that were never going to be swapped out, and where understanding a single database call requires traversing a chain: controller → service interface → service implementation → repository interface → repository implementation → query builder.
As noted on Devopedia, SOLID “encourages use of abstractions resulting in codebase littered with interfaces. To manage this problem, we end up introducing IoC containers and mocking frameworks, making the code more difficult to understand.” The DIP was designed to enable substitution where substitution is genuinely needed. When applied to every class in a system as a matter of policy, it creates the structural complexity of a pluggable system without any of the flexibility, because nothing is ever actually plugged in differently.
| Principle | Correct application | Common misapplication | Damage |
|---|---|---|---|
| SRP | Split classes with genuinely different change drivers | Fragment every class until each has one method | Unintelligible |
| OCP | Protect stable abstractions from modification | Build extension hierarchies for hypothetical features | Dead code |
| LSP | Ensure subtypes honour contracts of supertypes | Inherit to reuse code, break the contract quietly | Silent bugs |
| ISP | Avoid forcing clients to depend on unused interfaces | Split every interface into micro-interfaces of one method | Moderate |
| DIP | Decouple high-level policy from low-level detail | Add interface + IoC container for every class | Deep indirection |
| DRY | Eliminate duplicated knowledge (business rules) | Merge any two functions that look syntactically similar | Wrong abstraction |
The Performance Argument: Clean Code’s Unpaid Bill
In early 2023, Seattle-based programmer Casey Muratori published a video titled “Clean Code, Horrible Performance” that sparked one of the most widely-discussed debates the software engineering community had seen in years. His finding was specific and empirical: by replacing the polymorphic, OCP-compliant design that Clean Code advocates use as a canonical example with a direct, switch-based computation, he achieved a 15× performance improvement. The same hardware. The same logic. Different structure.
Muratori’s argument, as reported by The New Stack, was that clean code advocates simply do not understand how CPUs work — specifically, that virtual dispatch through interfaces defeats branch prediction and CPU caches in ways that accumulate painfully at scale. The comparison he drew was stark: over-abstracted code effectively ages your hardware by fifteen years. For server-side code, where monthly cloud bills are directly proportional to compute efficiency, this is not an academic point.
Robert Martin’s response — that clean code is for teams, not CPUs, and that its value is in human productivity rather than raw performance — is fair as far as it goes. However, it concedes the core point: the principles do trade performance for structure, and that trade is worth interrogating on a context-by-context basis rather than accepting unconditionally. A data pipeline processing billions of events is not the same context as a CRUD web service. Applying the same structural doctrine to both is a mistake.
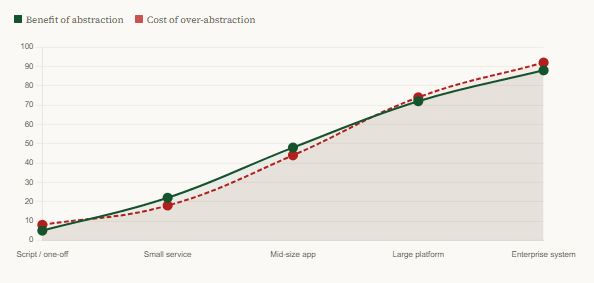
Cost of abstraction at different scales
The Real Problem Is Social, Not Technical
Here is the uncomfortable truth that sits underneath all of this: the damage caused by over-applied clean code principles is not primarily a technical failure. It is a social one. The principles themselves are not harmful; the institutional authority they accrue over time is.
Once a team has committed to a particular architectural style — once the IoC container is in, once every class has its interface, once the abstraction hierarchy is three levels deep — that structure has inertia. New developers inherit it and assume it is correct because it was there before them. The original architect has moved on. Nobody remembers why the UserValidationServiceFactoryImpl exists, but nobody dares remove it because it might break something, and also because removing it would imply that the people who wrote it were wrong, and code review culture punishes that kind of boldness.
Dan Abramov captured this dynamic in his talk The Wet Codebase: the question is not just whether you make bad abstractions, but whether your technology and your team make it easy to undo them. An abstraction that can be cheaply reversed when it proves wrong is low risk. An abstraction that becomes load-bearing — that every other module depends on — is a bet that only pays off if you guessed the future correctly.
This is why context is everything. A startup iterating toward product-market fit needs code that is easy to delete and rewrite. Premature SOLID compliance in that environment, as Baeldung notes, leads to constant refactoring of abstractions that were created before the business direction was clear. A large, stable enterprise system with dozens of contributors and multi-year maintenance horizon is the environment the principles were actually designed for. Applying them identically to both contexts is like prescribing the same medication regardless of diagnosis.
What to Do Instead: Pragmatic Design Principles
None of this means you should write spaghetti code. It means you should treat design principles as tools rather than rules, and evaluate each application on its actual tradeoffs. Concretely, that looks like the following.
Prefer duplication until the abstraction is obvious. Sandi Metz’s advice is sound: if you have two pieces of similar code and you are not yet sure whether they share the same reason to change, leave them separate. The cost of duplication is much lower than the cost of the wrong abstraction. When the pattern demands to be extracted — when you find yourself maintaining the same business rule in five places — that is the moment to abstract, because by then you understand what the abstraction should be.
# Prefer this (two simple, clear methods) over a "shared" helper
# that accumulates parameters every time requirements diverge.
# NOT THIS — premature abstraction:
def process_entity(entity, mode, skip_validation=False, legacy_format=False):
# 40 lines of conditionals trying to serve two callers
# THIS — honest duplication until the pattern is clear:
def process_order(order):
# 15 lines, directly readable, single purpose
def process_refund(refund):
# 12 lines, directly readable, single purpose
Add interfaces only when you have two implementations. The Dependency Inversion Principle earns its keep when you genuinely need to swap implementations — typically in testing, or when supporting multiple backends. If you have a PostgresUserRepository and no other implementation exists or is planned, the UserRepository interface is tax, not architecture. Start without it. Add it when the second implementation appears.
Measure before you optimise structure. Before extracting a shared abstraction, ask: do these two things have the same reason to change? Before splitting a class, ask: will these two parts ever need to evolve independently? Before adding an interface, ask: will this ever have a second implementation? If the honest answer is “probably not,” you are adding structural complexity for theoretical, speculative benefit.
Apply principles proportionally to the lifespan of the code. A data migration script that runs once needs none of SOLID. An MVP that might pivot in six months needs minimal abstraction and maximum changeability. A payment processing engine that handles billions of transactions over a decade, maintained by a rotating team of engineers, is exactly the context these principles were designed for.

The Orthodoxy Problem
The deepest issue with clean code culture is not any individual principle but the way it hardens into orthodoxy. Principles become interview questions. Interview questions become hiring filters. Hiring filters become team norms. Team norms become institutional religion. And suddenly, you are in a code review defending a flat, readable function because it violates the SRP — not because the reviewer can explain what harm it causes, but because the principle says so.
Robert Martin himself never claimed his principles were universal laws. The title Clean Code was a provocation, not a promise. The principles were observations about code that aged well in large, long-lived codebases — useful heuristics derived from experience, not theorems derived from first principles. They deserve the treatment we give all useful heuristics: apply them when the context supports them, ignore them when it does not, and always be willing to explain why in plain language.
The best codebases are not the ones that followed the most rules. They are the ones where every decision was made by someone who understood the tradeoff they were accepting — and felt free to say so out loud.
What We’ve Learned
In this article, we examined the ways that SOLID and DRY — two of the most widely-taught principles in software engineering — can actively harm codebases when applied without context. We traced how DRY’s prohibition on repetition leads to the wrong abstraction: shared code that accumulates flags and conditionals until it is harder to understand than the duplication it replaced, a pattern described with precision by Sandi Metz and countered by Kent C. Dodds’ AHA Programming. We looked at how SOLID’s most frequently misapplied principles — SRP, OCP, and DIP — produce code that is formally correct but practically unintelligible, fragmenting logic across dozens of tiny classes and burying computation behind layers of interface indirection that nobody ever intended to swap out.
We reviewed Casey Muratori’s 2023 empirical demonstration that clean code polymorphism carries a measurable performance cost — up to 15× in tight loops — and what that means for server-side work where compute cost is real money. Finally, we argued that the deepest problem is social: principles harden into orthodoxy, and orthodoxy removes the space for contextual judgment that good engineering requires. The goal has always been software that is easy to change — not software that obeys the most rules.
