For two decades, SQLite was the database you used in tests, mobile apps, and quick prototypes — and then swapped out “when things got real.” That assumption is quietly breaking down. In 2026, a wave of tooling, new architectural patterns, and some honest re-evaluation of what most apps actually need has pushed SQLite into production at surprising scale.
This is not a story about SQLite replacing PostgreSQL for every workload. It’s a story about a category of applications — read-heavy services, multi-tenant SaaS products, edge deployments, embedded JVM tools — where SQLite has become, frankly, the better choice. And with platforms like Turso, tools like Litestream, and first-class support in frameworks from Ruby on Rails to Spring Boot, the gap between “embedded database” and “production database” has closed further than most developers realise.

Why We Dismissed SQLite — And Why Those Reasons Are Expiring
The standard knock on SQLite for server-side use has always been the same list: single-writer concurrency, no network access, no user management, limited ALTER TABLE support, and no replication. These criticisms were, and in some cases still are, entirely fair. SQLite was literally designed in 2000 for an environment with no network, no multi-process access, and no need to run 24/7 under load.
However, a key insight has been doing the rounds in engineering blogs since 2024: SQLite is, as Stephen Margheim put it in a well-circulated Rails talk, a database configured for 2004 hardware running on 2025 hardware. SSDs have fundamentally changed the I/O cost model. In WAL (Write-Ahead Logging) mode on NVMe storage, SQLite achieves 10,000–50,000 sustained writes per second on a single node — comparable to a well-tuned PostgreSQL instance on the same machine. Additionally, enabling WAL mode reduces p99 write latency by 30–60% under concurrent load compared to SQLite’s default journal mode. That’s not a toy database number; it’s a number that covers the overwhelming majority of web applications.
Furthermore, the ecosystem has moved. The tooling that used to require a separate database server is now either built into SQLite extensions or handled by a thin wrapper. That changes the calculus entirely.
The honest caveat upfront: SQLite remains a single-writer database. If your application has genuinely high concurrent write throughput from multiple processes — think real-time bidding, a high-frequency event pipeline, or a multi-writer distributed system — PostgreSQL or MySQL is still the right tool. The rest of this article is about the much larger group of applications that are not in that category.
The Ecosystem That Changed Everything
The SQLite renaissance is not one tool going viral. Instead, it’s several independent projects reaching maturity simultaneously and combining to solve SQLite’s real limitations without abandoning its core simplicity.
LibSQL and Turso — SQLite With Network Access
LibSQL is an open-source fork of SQLite created by the Turso team. It maintains 100% SQLite API compatibility while adding the features that were previously impossible: a server mode accessible over HTTP and WebSockets, embedded replicas that sync automatically from a remote primary, multi-writer support via BEGIN CONCURRENT using MVCC, native vector search for AI and RAG workloads, and improved ALTER TABLE support. Crucially, Turso builds a fully managed cloud product on top of LibSQL, offering unlimited databases (no cold starts, since databases are files rather than processes) and a generous free tier of 9 GB storage and 500 million row reads per month.
The architectural pattern this enables is compelling: each user, tenant, or AI agent gets their own SQLite database. Reads execute against a local replica with microsecond latency. Writes sync back to a remote primary. There’s no connection pool to manage, no scale-to-zero penalty, and no shared-state contention between tenants. For multi-tenant SaaS applications, this database-per-tenant model using SQLite is significantly simpler operationally than the equivalent PostgreSQL schema-per-tenant or row-level isolation pattern.
Litestream — Continuous Backup Without a Server
Litestream, created by Ben Johnson, is perhaps the most underrated tool in the SQLite ecosystem. It runs as a sidecar process that continuously tails SQLite’s Write-Ahead Log and streams changes to S3-compatible object storage. Recovery means restoring from the stream — point-in-time recovery, low RPO, multi-environment replication — all without running a database server. For teams that want the operational simplicity of SQLite but needed a credible disaster-recovery story, Litestream closes that gap cleanly. A minimal Litestream config looks like this:
# litestream.yml — continuous WAL streaming to S3
dbs:
- path: /data/app.db
replicas:
- url: s3://your-bucket/app.db
That’s it. Litestream handles WAL tailing, S3 uploads, compression, and retention automatically. Restoring is a single command. Combined with SQLite’s ACID compliance and WAL mode’s durability guarantees, this is a production-grade backup story that many Postgres setups don’t match in simplicity.
Cloudflare D1 — SQLite at the Global Edge
Cloudflare D1 reached general availability in April 2024 with automatic read replication across Cloudflare’s global network. SQLite is embedded directly in the Workers runtime; the developer interacts with a binding, not a file or connection string. Benchmarks show D1 delivering 3.2× faster query performance than a popular serverless PostgreSQL provider on a 500,000-row table. For Cloudflare Workers users, D1 is the natural default — the database lives co-located with the compute, removing the cross-region round-trip that makes serverless database performance frustrating.
Read Latency Comparison — p50, SELECT by Primary Key
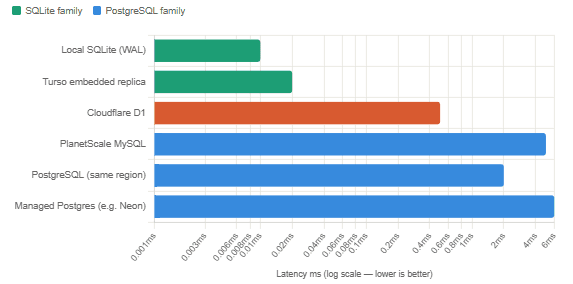
The JVM Angle: SQLite in Spring Boot and Beyond
One area where the SQLite renaissance is almost entirely underdiscussed is the JVM. Java and Kotlin developers reaching for an embedded database have historically turned to H2 or HSQLDB for development and then swapped to PostgreSQL for production. But SQLite is a compelling alternative to both — and it works in production, not just in tests.
The xerial sqlite-jdbc driver (3,000+ GitHub stars, last release November 2025 at version 3.50.x) provides a standard JDBC interface. From Hibernate 6 onwards, SQLite dialect support is built into hibernate-community-dialects, meaning the Spring Boot + JPA setup is genuinely straightforward. Since SQLite runs in-process, there is no socket, no service, and no authentication layer — reads and writes go directly to the file on disk through the JVM.
A working Spring Boot + SQLite configuration in application.properties looks like this:
# application.properties — Spring Boot + SQLite + Hibernate 6 spring.datasource.url=jdbc:sqlite:./data/app.db spring.datasource.driver-class-name=org.sqlite.JDBC spring.jpa.database-platform=org.hibernate.community.dialect.SQLiteDialect spring.jpa.hibernate.ddl-auto=update spring.sql.init.mode=always # Enable WAL mode for better concurrent read performance spring.datasource.hikari.connection-init-sql=PRAGMA journal_mode=WAL; PRAGMA synchronous=NORMAL;
The Maven dependency for sqlite-jdbc is:
<dependency> <groupId>org.xerial</groupId> <artifactId>sqlite-jdbc</artifactId> <version>3.50.3.0</version> </dependency> <dependency> <groupId>org.hibernate.orm</groupId> <artifactId>hibernate-community-dialects</artifactId> </dependency>
JVM sweet spots for SQLite: CLI tools and desktop Java apps that need a local data store; Spring Boot microservices with single-instance deployments and low write concurrency; test suites that benefit from an in-memory SQLite (
jdbc:sqlite::memory:) instead of a running Postgres container; Android applications (SQLite is the native Android database); and read-heavy services where the database sits on the same machine as the application.
The one JVM footgun worth flagging: SQLite’s connection-level locking means that with a HikariCP connection pool and multiple threads writing simultaneously, you will hit SQLITE_BUSY errors without careful configuration. Setting PRAGMA busy_timeout=5000 and keeping write concurrency low (or routing writes through a single connection) solves this in practice. However, if your JVM service has many concurrent writers, Postgres remains the more natural fit.
Sustained Write Throughput — Single Database (writes/second)

The Per-Tenant Architecture Shift
Beyond raw performance, arguably the most interesting architectural shift SQLite enables in 2026 is the database-per-tenant pattern. Traditional multi-tenant PostgreSQL apps use either a shared schema with a tenant_id column or a separate schema per tenant. Both approaches require careful query isolation, row-level security policies, and connection pooling that accounts for tenant load.
With SQLite and Turso, each tenant simply gets their own database file. Isolation is structural, not logical. There’s no risk of a slow tenant query affecting another tenant’s reads. Backups, migrations, and even deletions (GDPR, anyone?) become trivially simple — you operate on a single file. Turso’s free tier supports unlimited databases, making this pattern cost-effective even at tens of thousands of tenants.
This is particularly relevant for SaaS products in their early growth phase, where the operational overhead of a properly isolated multi-tenant Postgres setup is disproportionate to the actual workload. As Turso notes, teams are building the pattern not just for SaaS but for AI agent architectures — each agent gets its own database to track state, store memory, and coordinate tasks without shared contention.
SQLite vs. PostgreSQL: A Practical Decision Guide
Rather than declaring a winner, it’s more useful to lay out exactly when each tool is the better choice. The following table is opinionated but grounded in the architectural realities of 2026.
| Scenario | SQLite / LibSQL | PostgreSQL |
|---|---|---|
| Read-heavy web app, single region | ✓ Excellent fit | Workable but slower reads |
| Edge / global low-latency reads | ✓ Ideal (D1, Turso) | ✗ Cross-region latency penalty |
| Multi-tenant SaaS (DB-per-tenant) | ✓ Native fit | Complex schema isolation |
| High concurrent writes (>5K/s, multi-process) | ✗ Single-writer bottleneck | ✓ Row-level locks, scales well |
| Spring Boot / JVM embedded tool | ✓ In-process, no server | Requires separate Postgres service |
| Complex analytics / window functions | Supported but limited optimizer | ✓ Best-in-class query planner |
| Full-text search | FTS5 built in (capable but basic) | ✓ Better with pg_trgm / external |
| AI / vector search (RAG workloads) | ✓ sqlite-vec extension, LibSQL native | ✓ pgvector (more mature) |
| Disaster recovery / backup simplicity | ✓ Litestream + single file | pg_dump / WAL archiving, more setup |
| Ops-free development (zero infrastructure) | ✓ No server, no Docker | ✗ Requires a running Postgres instance |
The Tuning You Actually Need
Out of the box, SQLite ships with settings optimised for 2004 hardware and a very conservative durability model. Fortunately, tuning it for modern production use takes about five lines of SQL. These PRAGMAs should be applied on every new connection via your connection pool’s initialisation SQL:
-- Apply these PRAGMAs on connection open (e.g., HikariCP connectionInitSql) PRAGMA journal_mode = WAL; -- Enables concurrent reads + single writer PRAGMA synchronous = NORMAL; -- Safe on SSD; full fsync only at WAL checkpoints PRAGMA busy_timeout = 5000; -- Wait up to 5s before SQLITE_BUSY error PRAGMA cache_size = -64000; -- 64 MB page cache in memory PRAGMA foreign_keys = ON; -- Foreign key enforcement (off by default)
These settings are safe, well-documented, and represent the consensus tuning from the Rails, Django, and Go communities that have been running SQLite in production. The synchronous = NORMAL setting deserves a note: it means data is durable after WAL checkpoints but not necessarily after every individual transaction commit. On SSDs, this is an excellent trade-off — crashes leave the database consistent, though you may lose the last few seconds of transactions in a catastrophic power failure. For applications using Litestream for continuous WAL streaming, even this edge case is mitigated.
Worth knowing: SQLite also has official documentation showing it can be 35% faster than direct filesystem writes for blob storage, and the entire SQLite library fits in under 600KB. For embedded tools, CLI applications, and resource-constrained environments, there simply is no competition.
The Tools That Round Out the Ecosystem
sqlite-vec
A lightweight SQLite extension for vector similarity search using virtual tables. Written in C with no dependencies, it works anywhere SQLite does — including WASM. For teams building AI features or RAG pipelines that don’t want to run a separate vector database, this is worth evaluating.
github.com/asg017/sqlite-vec →
LiteFS (Fly.io)
A FUSE-based replication layer for SQLite designed for Fly.io deployments. Replication is transparent to the application. Suitable for read-heavy apps on Fly.io where write throughput doesn’t exceed ~100 writes/second. Open source, self-hosted.
Turso (Rust rewrite)
Beyond LibSQL (C-based, production today), Turso is also building a clean-room Rust rewrite of SQLite codenamed “Limbo” — currently in beta. It adds MVCC concurrent writes, async-first architecture, and WASM support from the ground up. Not production-ready yet, but it signals the long-term direction of the ecosystem.
github.com/tursodatabase/turso →
rqlite / dqlite
For teams that specifically need multi-primary distributed SQLite with Raft consensus, rqlite and dqlite are the canonical options. They trade SQLite’s simplicity for multi-writer semantics. Worth evaluating when you’ve genuinely outgrown single-primary SQLite but don’t want to switch to a different database entirely.
When to Move On From SQLite
Knowing when SQLite is the wrong tool is just as important as knowing when it’s the right one. The clearest signals that you’ve outgrown it are: multiple processes writing concurrently and hitting SQLITE_BUSY despite tuning; a need for row-level or table-level locks across concurrent transactions; complex analytical queries that benefit from PostgreSQL’s cost-based query planner; or a requirement for advanced Postgres extensions (PostGIS, TimescaleDB, and so on). Additionally, if your team already has mature Postgres operations expertise, the switching cost may not be worth it for a modest performance gain.
In short, reach for SQLite first for single-process services, embedded tools, edge deployments, and multi-tenant applications where isolation by file is cleaner than isolation by row. Reach for PostgreSQL when you need multi-writer concurrency, complex analytical workloads, or a rich extension ecosystem. And critically — don’t confuse “it’s just SQLite” with “it’s not production-grade.” At this point, that’s no longer an accurate statement.
What We Have Learned
- SQLite’s old limitations — no networking, no replication, single writer — are being solved at the ecosystem level by LibSQL, Turso, Litestream, Cloudflare D1, and LiteFS, not by changing SQLite itself.
- On modern NVMe hardware with WAL mode enabled, local SQLite delivers read latency 100–1000× lower than any networked database, and write throughput comparable to PostgreSQL on the same machine.
- Cloudflare D1 and Turso bring SQLite to the edge with automatic read replication, enabling sub-10ms reads globally — something a centralised Postgres instance fundamentally cannot match.
- The database-per-tenant architecture pattern, enabled by SQLite’s file-per-database model, is far simpler operationally than PostgreSQL row-level isolation for multi-tenant SaaS and AI agent workloads.
- In the JVM ecosystem, SQLite is production-ready via the xerial sqlite-jdbc driver and Hibernate 6’s community dialect. WAL mode plus a carefully configured HikariCP pool handles most single-instance Spring Boot or Kotlin services cleanly.
- Litestream turns SQLite’s single-file simplicity into a production backup story: continuous WAL streaming to S3, point-in-time recovery, no database server required.
- The right question in 2026 is not “is SQLite serious enough for this?” but “does my workload have the concurrent write volume that requires PostgreSQL?” For most read-heavy web applications, the honest answer is no.
