Why no algorithm — and no AI model — can fully decide what programs do, and what that means for every static analysis tool you’ve ever shipped.
In 1936, Alan Turing proved something extraordinary: no algorithm can exist that reliably determines whether an arbitrary program will eventually stop running or loop forever. This was not a temporary gap in our knowledge — it was a proof that the gap is permanent. Eighty-nine years later, that result still explains why your linter produces false positives, why your AI code reviewer misses certain bugs, and why formal verification tools ask you to write invariants by hand.
This article is for developers who want the theory behind the tools — not just what these limits are, but why they exist and, critically, what they imply for the static analysis landscape of 2026.
1. The Setup: What Does “Decidable” Actually Mean?
Before we get to the proof itself, it’s worth being precise about what we’re claiming. A problem is decidable if there exists an algorithm that, given any valid input, terminates in finite time and outputs a correct yes or no. A problem is undecidable if no such algorithm can possibly exist — not because we haven’t found one yet, but because it can be proven that one cannot exist.
Notice the strength of that claim. We’re not talking about computational complexity — about problems that are solvable in principle but slow in practice. Undecidability is a categorical wall. Throwing more hardware, more memory, or more model parameters at an undecidable problem doesn’t help. The impossibility is mathematical, not technological.
Turing formalised computation itself in order to make this kind of proof possible. He invented a theoretical device — now called a Turing machine — which is a minimal model of computation powerful enough to simulate any algorithm. Once you have a formal model, you can ask rigorous questions about what that model can and cannot compute.
2. The Halting Problem: Turing’s Original Proof
The Halting Problem asks: given a program P and an input I, does P eventually halt when run on I? Turing proved in his 1936 paper that no algorithm can answer this for all possible (P, I) pairs. The proof is a masterpiece of diagonal reasoning — a technique also used by Cantor to show that the real numbers are uncountable.
The Halting Problem — Proof by Contradiction Assume a decider HALT(P, I) exists that always returns YES if P halts on I, and NO otherwise. Now construct a new program D(P): If HALT(P, P) returns YES → loop forever. If HALT(P, P) returns NO → halt immediately. Ask: what does D(D) do? If D halts when run on itself, HALT(D, D) returns YES, so D loops forever — contradiction. If D loops forever, HALT(D, D) returns NO, so D halts — contradiction. Conclusion: HALT cannot exist. The assumption leads to a logical impossibility regardless of which branch we follow. QED.
The key move is self-reference: we construct a program that takes another program as its own input, then feeds itself to itself. This diagonal argument creates a situation with no consistent answer, proving that no general decider can handle it.
Importantly, the proof says nothing about specific programs. We can absolutely determine that many individual programs halt — compilers do this all the time for simple loops. The undecidability is about the general case: there is no algorithm that works for every possible program.
3. Rice’s Theorem: The Full Generalisation
If the Halting Problem feels like a narrow edge case, Rice’s Theorem removes that comfort entirely. Proved by H. Gordon Rice in 1953, it says something much broader:
Rice’s Theorem (informal): For any non-trivial semantic property of programs — any question about what a program does rather than what it looks like — there is no general algorithm that decides whether an arbitrary program has that property.
A semantic property is one that depends on the program’s behaviour, not its syntax. “Does this program ever output the number 42?” is semantic. “Does this program contain a for-loop?” is syntactic. Rice’s Theorem covers all semantic properties.
“Non-trivial” means the property is true of some programs and false of others. The theorem doesn’t cover the vacuous cases of “true of all programs” or “true of no programs.” Every interesting question you’d want to ask about program behaviour is non-trivial.
Together, the two results form a complete boundary. The Halting Problem is one instance of an undecidable semantic property. Rice’s Theorem tells you that all semantic properties are undecidable — without exception.
| Question about a Program | Type | Decidable? |
|---|---|---|
| “Does it contain a try-catch block?” | Syntactic | Yes — parse the AST |
| “Does it always terminate?” | Semantic | No — Halting Problem |
| “Does it ever throw a NullPointerException?” | Semantic | No — Rice’s Theorem |
| “Does it produce the same output as program Q?” | Semantic | No — Rice’s Theorem |
| “Does it ever access an uninitialised variable?” | Semantic | No — Rice’s Theorem |
| “Is it free of all security vulnerabilities?” | Semantic | No — Rice’s Theorem |
| “Does it conform to this type signature?” | Semantic (restricted) | Sometimes — with language restrictions |
That last row is worth pausing on. Strongly typed functional languages like Haskell and languages with dependent types like Coq or Lean deliberately restrict what programs can express, specifically so that certain semantic properties become decidable. The price is expressiveness; the reward is provability. That trade-off is the entire philosophy behind type theory.
4. What This Means for Static Analysis Tools
Static analysis is the practice of examining code without running it, in order to find bugs, enforce style, or verify correctness. Every major IDE ships with static analysis. So does every CI pipeline worth its salt. But given Rice’s Theorem, what are these tools actually doing?
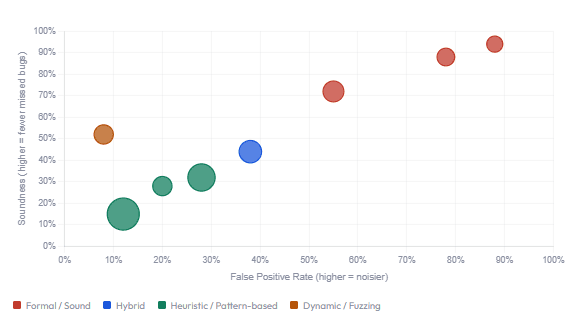
The answer is that they operate by restricting the problem. Since the general case is undecidable, all sound static analysis tools approximate — and every approximation has one of two failure modes:
| Analysis Strategy | What It Does | False Positives? | False Negatives? | Example Tools |
|---|---|---|---|---|
| Over-approximation (Sound) | Reports all possible errors, including impossible ones | Yes | Never | Astree, Polyspace, Infer |
| Under-approximation (Complete) | Only reports confirmed real errors | Never | Yes | Fuzzing, bounded model checking |
| Heuristic (Neither) | Balances usability against both error types | Yes | Yes | ESLint, SonarQube, Semgrep, CodeQL |
Facebook’s Infer, for example, uses a technique called bi-abduction derived from separation logic to reason about heap memory. It is sound for the properties it checks — it won’t miss a null dereference it has committed to checking — but it produces false positives and doesn’t cover all possible properties. That’s not a bug in Infer; it’s the only mathematically coherent choice available.
Meanwhile, tools like ESLint operate with heuristics: pattern-matching on ASTs, dataflow through a bounded number of steps, known-bad code signatures. These are neither sound nor complete, but they are useful — and usefulness, not completeness, is the engineering goal.
Static Analysis Tools: Soundness vs. False Positive Rate
5. The AI Problem: Why Larger Models Don’t Change the Math
In 2026, the most discussed static analysis tools are increasingly AI-powered: GitHub Copilot’s review suggestions, Amazon CodeGuru, Cursor’s inline diagnostics, and a growing constellation of LLM-backed linters. A natural question follows: do these tools escape the limits imposed by Rice’s Theorem?
The answer is no — and understanding why clarifies what AI code analysis can and cannot do.
Rice’s Theorem applies to any computational procedure, not just traditional algorithms. A transformer model is a fixed function mapping inputs to outputs. Running it constitutes a computation. Therefore, if it claimed to decide an arbitrary semantic property of programs — with no false positives and no false negatives — it would constitute a decider for that property, which Rice’s Theorem proves cannot exist.
What this means practically: An AI model that claimed to reliably detect all possible null dereferences in all possible programs would be claiming to solve an undecidable problem. Either it misses some (false negatives), flags non-issues (false positives), or both. This is not a current limitation of AI capability — it is a permanent mathematical boundary.
What AI does change is the nature of the approximation. Traditional static analysis tools use handcrafted rules and formal abstractions. AI tools use patterns learned from billions of lines of code. Neither approach is complete, but they have very different failure profiles:
| Dimension | Traditional Static Analysis | AI-Powered Analysis (2026) |
|---|---|---|
| Theoretical basis | Formal semantics, abstract interpretation, dataflow | Statistical patterns from training data |
| Error type bias | Predictable (over- or under-approximation by design) | Unpredictable — depends on training distribution |
| Novel bug classes | Misses bugs not in its rule set | May generalise; may hallucinate new patterns |
| Auditability | High — rules are inspectable | Low — weights are not human-readable |
| Rice’s Theorem status | Subject to it; acknowledged explicitly | Subject to it; rarely acknowledged |
The practical implication is that AI analysis tools are best understood as extremely sophisticated heuristics. They can catch bugs that pattern-matching rules miss. They can suggest fixes with context sensitivity that no rule system achieves. But they cannot, even in principle, achieve completeness. Every benchmark that evaluates them — including SWE-bench and emerging security benchmarks — captures an approximation of capability, not a proof of coverage.
Furthermore, AI models introduce a subtly different failure mode: confident incorrectness. A formal sound analyser that flags a false positive at least knows it’s making a conservative approximation. An LLM that hallucinates a security vulnerability explanation may do so with high fluency and apparent certainty. For safety-critical applications, this distinction matters enormously.
6. Formal Verification: Escaping Undecidability Through Proof
If undecidability prevents algorithms from automatically deciding semantic properties, how do formal verification tools like Coq, Lean, and Isabelle actually work? The answer is that they shift the burden — they don’t decide properties automatically, they help humans construct machine-checked proofs of those properties.
The key distinction is between verification and decision. Deciding whether a property holds requires an algorithm that works on any program. Verifying a specific property of a specific program, with a human-written proof, is a different task — one that can succeed even for undecidable properties, as long as a proof exists and someone writes it.
Real-world example: The seL4 microkernel is a formally verified OS kernel whose correctness — including memory safety, absence of deadlocks, and adherence to its security policy — has been mechanically checked in Isabelle. The verification took approximately 11 person-years of proof engineering. Undecidability didn’t prevent this; it just meant a human had to specify and prove the invariants, rather than a tool discovering them automatically.
This is precisely why formal verification requires human-specified invariants, loop contracts, and pre/post conditions. These annotations are the human’s contribution to the proof. Without them, the tool has no way to know what you intend the program to do — and by Rice’s Theorem, it cannot infer that from the code alone.
Assurance Level vs. Engineering Effort Across Verification Approaches

7. Code Coverage and the Completeness Illusion
One final implication is worth spelling out directly, because it catches even experienced engineers off guard. 100% code coverage does not mean your test suite covers all program behaviours.
Code coverage measures whether a line or branch was executed during a test. It says nothing about whether the execution explored all reachable paths, encountered all possible inputs, or triggered all observable behaviours. A function can have 100% branch coverage and still behave incorrectly on inputs your tests never considered.
Rice’s Theorem provides the theoretical underpinning for why this gap is irreducible. Deciding whether a test suite covers all semantically distinct behaviours of a program is itself an undecidable problem. No coverage tool, however sophisticated, can close that gap in general — which is exactly why coverage is a proxy metric, not a correctness certificate.
Practical takeaway: Use coverage as a floor, not a ceiling. 80% line coverage is a meaningful minimum signal. But “we have 100% branch coverage” should not be read as “we have verified correctness.” The two claims belong to entirely different theoretical categories.
Demonstrating the limits: a halting program a simple checker gets wrong
The following Python snippet is self-contained, requires Python 3.x, and illustrates why even straightforward-looking termination is hard to determine statically. It implements the Collatz sequence — a computation no one has yet proven always halts, despite being expressible in four lines of code:
# Python 3.x required — no external packages needed
# Run with: python collatz.py
def collatz(n):
"""
Collatz conjecture: for any positive integer n,
this sequence is conjectured to always reach 1.
No general proof exists. A static analyser cannot
decide termination for this function — neither can
any human, as of 2026.
"""
steps = 0
while n != 1:
n = n // 2 if n % 2 == 0 else 3 * n + 1
steps += 1
return steps
# These all terminate quickly
for start in [6, 27, 871]:
print(f"collatz({start}) → {collatz(start)} steps")
# Output:
# collatz(6) → 8 steps
# collatz(27) → 111 steps
# collatz(871) → 178 steps
No static analysis tool, no AI model, and no existing mathematical proof can tell you that collatz(n) terminates for every positive integer n. This is not a gap in tooling maturity — it is an open problem in mathematics that Rice’s Theorem tells us cannot, in general, be mechanically decided.
8. What We’ve Learned
- The Halting Problem proves — by contradiction, via Turing’s diagonal argument — that no algorithm can decide whether an arbitrary program halts for all possible inputs. This is a permanent mathematical boundary, not a temporary engineering gap.
- Rice’s Theorem generalises this completely: every non-trivial semantic property of programs — anything about what a program does — is undecidable. Security, termination, output correctness, null safety: all of them, without exception.
- Static analysis tools escape undecidability by restricting the problem: sound tools over-approximate (false positives, no false negatives), complete tools under-approximate (false negatives, no false positives), and heuristic tools like ESLint and SonarQube trade formal guarantees for practical usefulness.
- AI-powered code analysis is subject to exactly the same theoretical limits. Larger models change the shape of the approximation — and can be dramatically better heuristics — but cannot achieve completeness for any non-trivial semantic property.
- Formal verification (Coq, Lean, Isabelle, seL4) sidesteps undecidability by having humans write proofs rather than asking tools to discover them automatically. Human-specified invariants are not a workaround — they are a necessary contribution to the proof.
- Code coverage is a proxy for testing effort, not a correctness certificate. 100% coverage cannot, in principle, guarantee all semantic behaviours are tested — Rice’s Theorem explains precisely why.
