1. Introduction: Java’s Unexpected ML Renaissance
While Python dominates ML research and experimentation, production deployment tells a different story. As of 2025, 68% of applications run on Java or the JVM, and enterprises invested in Java ecosystems face a critical question: retrain teams and rewrite systems, or bring ML capabilities to Java? The answer increasingly favors the latter.
Netflix uses Deep Java Library for distributed deep learning inference in real-time, processing log data through character-level CNNs and Universal Sentence Encoder models with 7ms latency per event. This represents a broader trend—Java’s strengths in production systems, multithreading, stability, and enterprise integration make it compelling for ML deployment despite Python’s training dominance.
This article examines Java’s role in the ML lifecycle, comparing frameworks, exploring integration patterns with Python ecosystems, and identifying scenarios where Java provides distinct advantages.
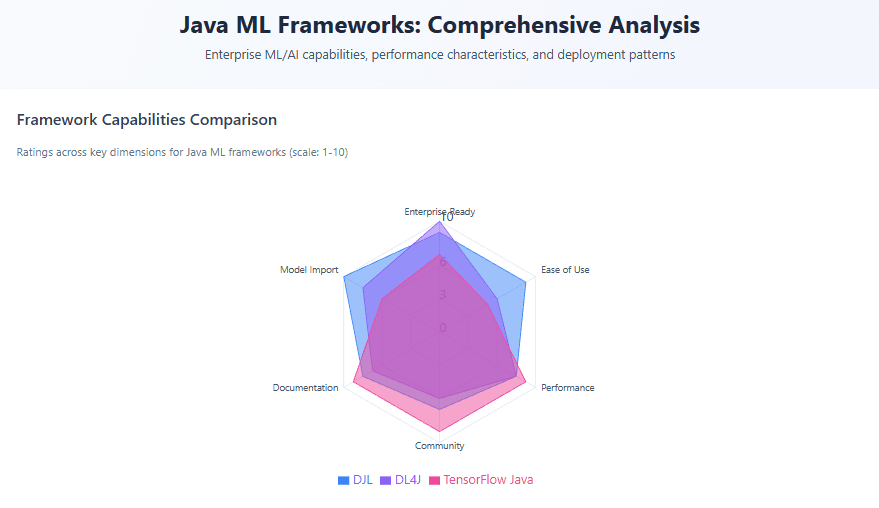
2. Java ML Frameworks Comparison
2.1 Deep Java Library (DJL): The Engine-Agnostic Approach
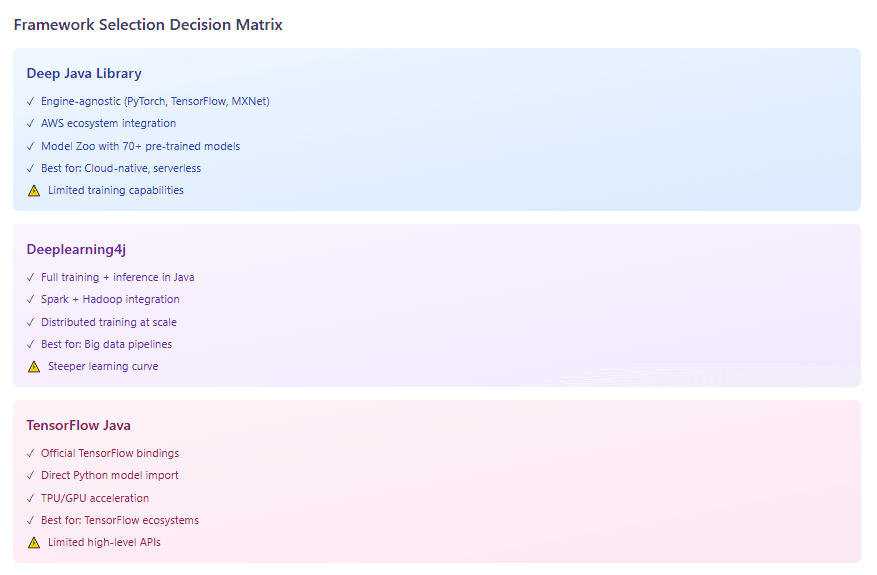
Deep Java Library is an open-source, high-level, engine-agnostic Java framework for deep learning that provides native Java development experience and functions like any other regular Java library. Created by AWS, DJL’s architectural philosophy centers on abstraction—developers write code once and switch between PyTorch, TensorFlow, MXNet, or ONNX Runtime without modification.
The framework consists of five architectural layers. The high-level API layer provides Java-idiomatic interfaces developers interact with directly. The engine abstraction layer communicates with underlying frameworks, hiding implementation differences. NDManager manages the lifecycle of NDArray representing tensors, automatically releasing tensor memory after processing to prevent leaks or crashes. The data processing layer provides utilities for preparing data for models. Finally, the native engine layer executes actual computations via JNA calls to C++ implementations.
DJL seamlessly integrates with various deep learning frameworks like TensorFlow, PyTorch, and MXNet, provides a high-level API for easy model building, training, and deployment in Java environments, and has strong ties to AWS services. The Model Zoo offers over 70 pre-trained models from GluonCV, HuggingFace, TorchHub, and Keras, enabling one-line model loading.
Strengths:
- Engine flexibility allows switching backends based on deployment requirements (PyTorch for research models, MXNet for production, ONNX for cross-platform)
- Native multithreading support integrates naturally with Akka, Akka Streams, and concurrent Java applications
- Automatic CPU/GPU detection ensures optimal hardware utilization without configuration
- Spring Boot integration via DJL Spring starters simplifies enterprise adoption
Limitations:
- Training capabilities exist but remain less mature than inference functionality
- Documentation emphasizes inference over training workflows
- Smaller community compared to Python-first frameworks
2.2 Deeplearning4j (DL4J): The JVM-Native Solution
Eclipse Deeplearning4j is a programming library written in Java for the Java virtual machine, a framework with wide support for deep learning algorithms including implementations of restricted Boltzmann machine, deep belief net, deep autoencoder, stacked denoising autoencoder, recursive neural tensor network, word2vec, doc2vec, and GloVe.
DL4J emerged in 2014 targeting enterprises already invested in Java infrastructure. The Eclipse Deeplearning4j project includes Samediff (a TensorFlow/PyTorch-like framework for execution of complex graphs), Python4j (a Python script execution framework for deployment of Python scripts into production), Apache Spark Integration, and Datavec (a data transformation library converting raw input data to tensors).
The framework’s distributed computing capabilities distinguish it from alternatives. Deeplearning4j includes distributed parallel versions that integrate with Apache Hadoop and Spark. For organizations processing large-scale data, DL4J provides native JVM solutions without Python dependencies.
Strengths:
- Complete ML lifecycle support—training, inference, and deployment entirely in Java
- Distributed training scales across clusters using Spark or Hadoop
- ND4J provides NumPy-like n-dimensional arrays with GPU acceleration
- SameDiff offers define-then-run graph execution similar to TensorFlow
- Keras model import supports h5 files including tf.keras models
Limitations:
- Documentation and community resources lag behind TensorFlow and PyTorch
- Steeper learning curve compared to higher-level frameworks
- Niche adoption limited mainly to Java-heavy enterprises
2.3 TensorFlow Java: Official but Limited
TensorFlow Java can run on any JVM for building, training and deploying machine learning models, supports both CPU and GPU execution in graph or eager mode, and presents a rich API for using TensorFlow in a JVM environment. As the official Java binding for TensorFlow, it provides direct access to TensorFlow’s computational graph execution.
The Java language bindings for TensorFlow were moved to their own repository to evolve and be released independently from official TensorFlow releases, with most build tasks migrated from Bazel to Maven. The separation allows Java-specific improvements without waiting for TensorFlow core releases.
Strengths:
- Direct integration with TensorFlow ecosystem and tooling
- SavedModel format compatibility enables seamless Python-to-Java model handoff
- TensorFlow Lite support targets mobile and edge deployments
- GPU and TPU acceleration through native TensorFlow runtime
Limitations:
- The TensorFlow Java API is not covered by TensorFlow API stability guarantees
- Little to no official support for Keras on Java, forcing developers to define and train complex models in Python for subsequent Java import
- Lower-level APIs require more code compared to DJL or even DL4J
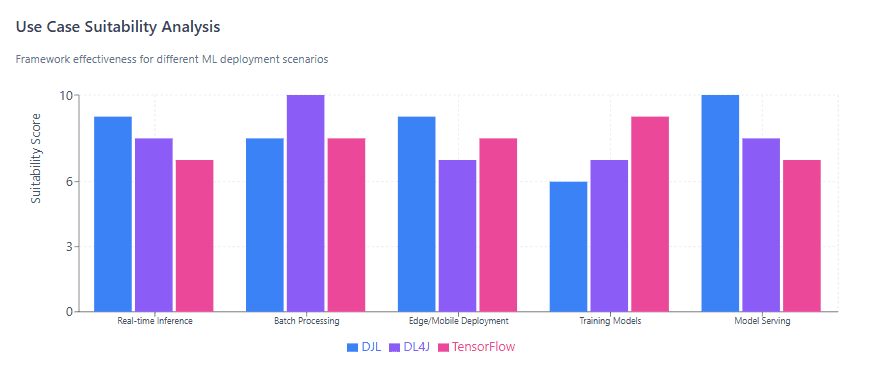
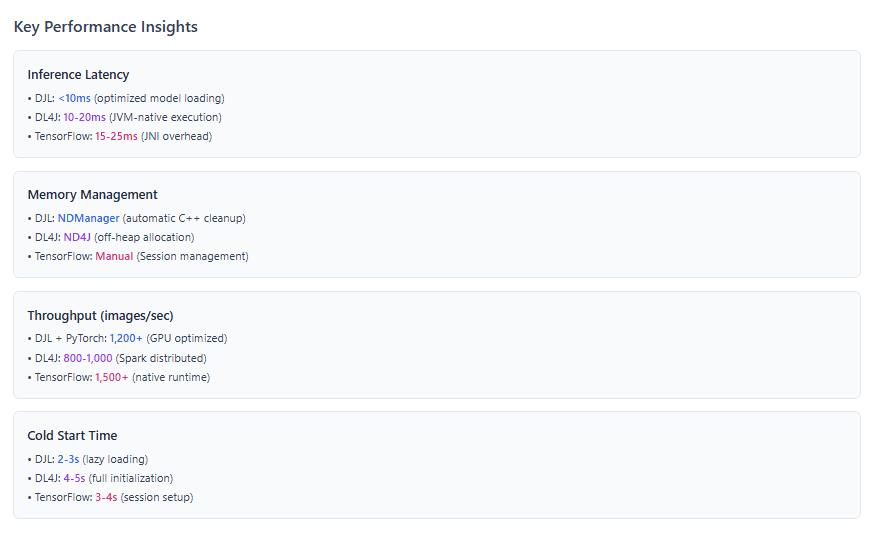
3. Framework Comparison Table
| Criteria | Deep Java Library | Deeplearning4j | TensorFlow Java |
|---|---|---|---|
| Primary Use Case | Inference & model serving | Full ML lifecycle | Model serving |
| Engine Support | PyTorch, TensorFlow, MXNet, ONNX | Native JVM | TensorFlow only |
| Training Capability | Limited | Full support | Limited |
| Distributed Computing | Via engine (Spark on MXNet) | Native Spark/Hadoop | Via TensorFlow |
| Model Import | PyTorch, TensorFlow, Keras, ONNX | Keras, TensorFlow, ONNX | TensorFlow only |
| Pre-trained Models | 70+ in Model Zoo | Community models | TensorFlow Hub |
| Spring Boot Integration | Native starters | Manual | Manual |
| Learning Curve | Low | Medium-High | Medium |
| Memory Management | NDManager (automatic) | ND4J (off-heap) | Manual session |
| Enterprise Readiness | High | Very High | Medium |
| Community Size | Growing | Niche | Large (Python) |
| Best For | Cloud-native inference | Big data ML pipelines | TensorFlow ecosystems |
Decision Matrix:
- Choose DJL for: Microservices, serverless functions, Spring Boot applications, engine flexibility, AWS ecosystem
- Choose DL4J for: Distributed training, Spark/Hadoop integration, complete Java-only stack, enterprise data pipelines
- Choose TensorFlow Java for: Existing TensorFlow investments, TPU deployment, direct Python model compatibility
4. Integration with Python ML Ecosystems
4.1 The Polyglot Production Pattern
The optimal enterprise ML workflow often combines Python’s research capabilities with Java’s production strengths. Data scientists train models in familiar Python environments using TensorFlow, PyTorch, or scikit-learn. Engineers then deploy these models in Java applications serving millions of requests daily.
Model Export Formats:
ONNX (Open Neural Network Exchange): The universal interchange format supports most frameworks. Train in PyTorch, export to ONNX, import via DJL or DL4J. This approach enables framework-agnostic deployment pipelines.
TensorFlow SavedModel: For long-term production services, export to a neutral format like ONNX or a framework-specific production format (SavedModel, TorchScript) that is optimized for serving. SavedModel bundles the computational graph, variable values, and metadata into a single directory structure.
TorchScript: PyTorch models serialize to TorchScript via scripting or tracing. DJL’s PyTorch engine loads these directly, maintaining the complete computational graph.
Keras H5: DL4J imports Keras models including tf.keras variants, preserving layer configurations and trained weights.
4.2 Python4j: Embedding Python in Java
DL4J’s Python4j module addresses scenarios requiring Python libraries unavailable in Java. Python4j is a Python script execution framework easing deployment of Python scripts into production. The approach embeds CPython interpreters in JVM processes, enabling bidirectional calls.
Use cases include:
- Preprocessing with scikit-learn pipelines before Java inference
- Calling specialized Python libraries (NumPy, SciPy) from Java data pipelines
- Running Python-based feature engineering alongside Java model serving
The trade-off involves managing Python runtime dependencies and potential GIL limitations. For high-throughput scenarios, model export remains preferable to runtime Python execution.
5. Model Serving and Deployment Patterns
5.1 Real-Time Inference Architecture
Production ML systems require sub-100ms latency for user-facing applications. Java’s threading model and JVM optimizations excel in this context. Serve TensorFlow models without Python in production achieving less than 10ms latency per prediction and scale horizontally like any Spring Boot service.
Synchronous REST APIs:
@RestController
public class PredictionController {
private final Predictor<Image, Classifications> predictor;
@PostMapping("/predict")
public Classifications predict(@RequestBody Image image) {
return predictor.predict(image); // <10ms typical latency
}
}
Spring Boot’s autoconfiguration, health checks, and metrics integrate seamlessly with DJL or DL4J predictor instances. Horizontal scaling follows standard microservice patterns—deploy multiple instances behind load balancers.
Asynchronous Processing:
For non-critical predictions, asynchronous processing increases throughput. Java’s CompletableFuture, Reactor, or Kotlin coroutines enable concurrent prediction batching:
// Batch predictions asynchronously
List<CompletableFuture<Result>> futures = images.stream()
.map(img -> CompletableFuture.supplyAsync(
() -> predictor.predict(img), executor))
.collect(Collectors.toList());
5.2 Batch Inference Patterns
Batch jobs might be containerized and deployed to a job scheduler or pipeline (like Airflow/Prefect, Kubeflow Pipelines, cloud Data Pipeline services), whereas online models are deployed to serving infrastructure (web servers, Kubernetes).
DL4J’s Spark integration processes massive datasets:
// Distributed batch scoring on Spark
JavaRDD<DataSet> testData = loadTestData();
JavaRDD<INDArray> predictions = SparkDl4jMultiLayer
.predict(model, testData);
The pattern distributes inference across cluster nodes, processing millions of records efficiently. For organizations with Hadoop or Spark infrastructure, this native integration eliminates Python bridge overhead.
5.3 Edge and Mobile Deployment
DJL supports deployment to edge devices and mobile platforms. For Android, DJL provides TensorFlow Lite and ONNX Runtime engines optimized for ARM processors. The automatic CPU/GPU detection adapts to available hardware.
Use cases include:
- On-device image classification in mobile apps
- IoT sensor anomaly detection without cloud connectivity
- Edge computing scenarios requiring local inference
The approach reduces latency, improves privacy (data stays local), and eliminates network dependencies.
6. Scalability Considerations
6.1 Containerization and Orchestration
Containerization using Docker allows packaging the model and its code along with all required libraries and dependencies into a self-contained unit that can run anywhere (on your laptop, on a cloud VM, in a Kubernetes cluster).
Java ML services containerize identically to traditional Spring Boot applications:
Dockerfile pattern:
FROM eclipse-temurin:21-jre-alpine COPY target/ml-service.jar app.jar ENTRYPOINT ["java", "-jar", "app.jar"]
Kubernetes orchestration handles scaling, health checks, and rolling updates. The uniformity means existing DevOps pipelines extend to ML services without special treatment.
6.2 Performance Optimization Strategies
Model Quantization: Reduce model size and inference time by converting float32 weights to int8. TensorFlow Lite and ONNX Runtime support quantization with minimal accuracy loss. Typical gains: 4x smaller models, 2-3x faster inference.
Batch Processing: Group predictions to amortize overhead. DJL and DL4J support batched inputs, leveraging SIMD instructions and reducing per-prediction latency from 10ms to 2-3ms per item in a batch of 32.
Model Compilation: ONNX Runtime and TensorFlow XLA compile models to optimized execution graphs. Pre-compilation during container build eliminates runtime compilation overhead.
Memory Management: DJL addresses the memory-leaking problem through its special memory collector NDManager, which collects stale objects inside the C++ application in a timely manner, providing stability in production environments after testing of 100 hours of continuous inference without crashing.
Connection Pooling: For services calling external model servers (TensorFlow Serving, Triton), maintain connection pools to reduce TCP handshake overhead.
6.3 Horizontal Scaling Patterns
Java ML services scale identically to stateless web services:
- Deploy multiple instances behind load balancers
- Use Kubernetes HorizontalPodAutoscaler based on CPU, memory, or custom metrics (inference queue depth)
- Implement circuit breakers to handle downstream failures gracefully
- Cache frequent predictions using Redis or Caffeine
The stateless nature of inference (given a model version) enables elastic scaling without coordination overhead.
7. MLOps for Java Applications
7.1 Continuous Training and Deployment
The objective of an MLOps team is to automate the deployment of ML models into the core software system or as a service component, automating the complete ML-workflow steps without any manual intervention.
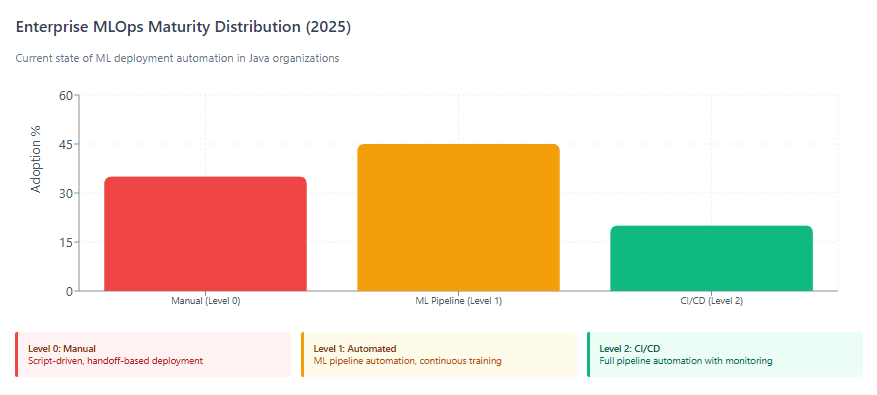
Level 0 (Manual): Many teams have data scientists and ML researchers who can build state-of-the-art models, but their process for building and deploying ML models is entirely manual, with every step requiring manual execution and manual transition. This represents 35% of Java ML deployments in 2025.
Level 1 (ML Pipeline Automation): Automated training pipelines retrain models on new data. Jenkins, GitHub Actions, or GitLab CI trigger training jobs, export models to artifact repositories (Nexus, Artifactory), and notify deployment systems. Versioned models deploy automatically to staging environments.
Level 2 (CI/CD for ML): Continuous Integration extends testing and validating code and components by adding testing and validating data and models, Continuous Delivery concerns with delivery of an ML training pipeline that automatically deploys another ML model prediction service, and Continuous Training automatically retrains ML models for re-deployment.
In Java contexts, this means:
- Automated unit tests for data pipelines and preprocessing
- Integration tests ensuring model predictions match expected outputs
- Canary deployments (5% traffic to new model versions)
- Automated rollback on performance degradation
7.2 Model Versioning and Registry
Treat models as first-class artifacts:
models/
fraud-detection/
v1.0.0/
model.onnx
metadata.json
v1.1.0/
model.onnx
metadata.json
Metadata includes training date, dataset version, performance metrics (accuracy, F1 score), and dependency versions. Maven coordinates reference model versions:
<dependency>
<groupId>com.company.ml</groupId>
<artifactId>fraud-detection-model</artifactId>
<version>1.1.0</version>
<classifier>onnx</classifier>
</dependency>
This approach applies standard dependency management practices to ML models, enabling reproducible builds and auditable deployments.
7.3 Monitoring and Observability
Once the ML model has been deployed, it needs to be monitored to assure that the ML model performs as expected. Java’s observability ecosystem extends naturally to ML services:
Metrics to Track:
- Inference Latency: p50, p95, p99 percentiles via Micrometer
- Throughput: Predictions per second, requests per second
- Error Rates: Failed predictions, model loading failures
- Data Drift: Input distribution changes detected via statistical tests
- Model Performance: Accuracy, precision, recall on production data (when labels become available)
Integration with Existing Tools:
Spring Boot Actuator exposes ML-specific metrics:
@Component
public class PredictionMetrics {
private final MeterRegistry registry;
public void recordPrediction(long latencyMs, String modelVersion) {
registry.timer("prediction.latency",
"model", modelVersion)
.record(Duration.ofMillis(latencyMs));
}
}
Prometheus scrapes these metrics, Grafana visualizes trends, and alerting triggers on anomalies (latency spikes, accuracy drops).
7.4 Testing ML Systems
Unit Tests: Verify data preprocessing, feature engineering, and post-processing logic. Standard JUnit tests suffice.
Integration Tests: Testing that an ML model successfully loads into production serving and the prediction on real-life data is generated as expected, and testing that the model in the training environment gives the same score as the model in the serving environment.
Performance Tests: JMeter or Gatling simulate load, measuring throughput and latency under realistic traffic patterns. Establish baselines and detect regressions.
Shadow Deployments: Run new model versions alongside existing ones, logging predictions without affecting users. Compare results to identify unexpected behavior before full deployment.
8. Use Cases Where Java Excels for ML
8.1 Enterprise Integration Scenarios
Fraud Detection in Financial Services: Enterprises with mature Java ecosystems are increasingly looking for ways to integrate ML/AI models directly into their backend systems without needing to spin up separate Python-based microservices. Banks process millions of transactions daily through Java systems. Embedding DJL predictors directly in transaction processing pipelines achieves sub-10ms fraud scoring without external service calls.
Real-Time Recommendations: E-commerce platforms built on Spring Boot integrate DJL for product recommendations. Session data flows through existing Java services, predictions occur in-process, and results render without network latency.
Log Analysis and Clustering: Netflix’s observability team uses DJL to deploy transfer learning models in production to perform real-time clustering and analysis of applications’ log data, processing log lines through character-level CNNs and Universal Sentence Encoder models in about 7ms each. The DJL-based pipeline assigns cluster IDs preserving similarity, enabling alert volume reduction and improved storage efficiency.
8.2 Big Data ML Workflows
Organizations processing terabytes daily with Spark or Hadoop benefit from DL4J’s native integration. Training models on historical data, scoring new records, and updating models—all within Spark pipelines without Python bridges.
Example workflow:
- Read data from HDFS or S3 into Spark DataFrames
- Perform feature engineering using Spark SQL
- Train DL4J model distributed across cluster
- Score new data using trained model
- Write results back to data warehouse
The end-to-end process remains in JVM, avoiding serialization overhead and Python interop complexity.
8.3 Microservices and Cloud-Native Applications
Spring Boot applications dominate enterprise microservice architectures. Adding ML capabilities via DJL starters integrates seamlessly:
- Circuit Breakers: Resilience4j patterns protect ML services from cascading failures
- Service Discovery: Eureka or Consul register ML prediction services
- Configuration: Spring Cloud Config manages model endpoints and parameters
- Tracing: Zipkin or Jaeger trace requests through ML pipelines
The uniformity simplifies operations—ML services deploy, scale, and monitor identically to business logic services.
8.4 Edge Computing and IoT
Java’s “write once, run anywhere” philosophy extends to edge devices. DJL models compiled for ARM processors run on Raspberry Pi, NVIDIA Jetson, and industrial IoT gateways. Use cases include:
- Predictive Maintenance: Analyze sensor data locally, trigger alerts on anomalies
- Video Analytics: Process security camera feeds at the edge, reducing bandwidth
- Smart Home Devices: On-device voice recognition and natural language understanding
GraalVM native image compilation produces standalone executables with minimal memory footprint (< 50MB) and fast startup (< 100ms), ideal for resource-constrained environments.
8.5 Regulatory and Compliance Requirements
With regulations like EU AI Act tightening, integration focuses on shift-left security for models—scanning for bias, explainability, and compliance in pipelines. Java’s strong typing, explicit exception handling, and mature logging frameworks facilitate audit trails and explainability requirements.
Financial and healthcare sectors often mandate that all code, including ML models, deploy through validated pipelines with approval workflows. Java ML services integrate with existing governance processes more naturally than introducing Python runtime dependencies.
9. Conclusion: What We’ve Learned
Java’s role in machine learning represents pragmatic production engineering rather than research innovation. The key insights from our analysis:
1. Framework Selection Depends on Context: DJL excels at inference and model serving with engine flexibility, making it ideal for cloud-native microservices. DL4J provides complete ML lifecycle capabilities integrated with big data frameworks, suitable for organizations requiring distributed training. TensorFlow Java serves teams deeply invested in TensorFlow ecosystems needing direct model compatibility.
2. The Polyglot Pattern Works: Training in Python and deploying in Java leverages each language’s strengths. ONNX and SavedModel formats enable seamless handoffs. Python4j bridges gaps when necessary, though model export remains preferable for performance.
3. Production Performance Matters: Netflix’s 7ms inference latency demonstrates that Java ML services achieve real-time performance requirements. Proper memory management (NDManager, ND4J), model optimization (quantization, compilation), and horizontal scaling deliver production-grade systems.
4. MLOps Maturity Varies: Only 20% of Java ML deployments achieve Level 2 CI/CD maturity with automated retraining and monitoring. The opportunity lies in applying established DevOps practices—containers, orchestration, observability—to ML workflows.
5. Java Excels in Specific Scenarios: Enterprise integration (fraud detection, recommendations), big data ML pipelines (Spark/Hadoop), microservices architectures, edge computing, and regulatory compliance represent areas where Java’s characteristics—stability, threading, ecosystem maturity—provide advantages over Python-centric approaches.
6. Memory Management Distinguishes Frameworks: DJL’s NDManager addresses the critical challenge of managing native memory in JVM applications, enabling 100+ hour production runs without memory leaks. This production readiness separates enterprise-viable frameworks from experimental bindings.
7. The Gap Is Closing: While Java won’t replace Python for ML research, frameworks like DJL and DL4J have matured sufficiently for production deployment. The ecosystem now supports the complete inference lifecycle with performance comparable to Python solutions.
The future likely involves deeper integration—Spring AI bringing LLM capabilities to Java, GraalVM native image enabling instant startup for serverless ML, and continued convergence between MLOps and DevOps practices. For organizations with substantial Java investments, the question shifts from “Can we do ML in Java?” to “How do we optimize Java ML deployments?”
As ML becomes ubiquitous in enterprise systems, Java’s production strengths—stability, performance, tooling maturity, and operational familiarity—position it as a pragmatic choice for the inference layer, even as Python retains dominance in training and experimentation. The polyglot approach—train in Python, deploy in Java—represents not compromise but optimization of each platform’s distinct advantages.
