Most systems start simple: one database, one model, straightforward CRUD operations. Then scale hits. Read queries slow down writes. Complex joins bog down simple updates. The team considers sharding, read replicas, caching—band-aids on a fundamentally mismatched architecture. This is where CQRS enters the conversation, not as a silver bullet but as a surgical tool for specific problems.
Command Query Responsibility Segregation separates read operations from write operations into distinct models, each optimized for its purpose. But here’s what the tutorials won’t tell you: for most systems CQRS adds risky complexity, and Netflix recently moved away from CQRS for their Tudum platform because it wasn’t the optimal approach for their use case. Understanding when CQRS helps versus when it hurts is the difference between architectural elegance and maintenance nightmares.
1. Understanding CQRS: Beyond the Textbook Definition
CQRS stands for Command Query Responsibility Segregation, first described by Greg Young. At its core: use different models for updating information than for reading information. Commands change state. Queries return data. They never intersect.
Traditional CRUD systems use a single model for both operations. As systems grow, this creates friction. Read and write operations often have different performance and scaling requirements, yet CRUD architectures force them to share the same infrastructure. That’s the asymmetry CQRS addresses.
The Command Side
Commands represent business intentions, not database operations. Instead of “Update User Table,” think “PromoteUserToAdmin” or “CancelSubscription.” Each command:
- Validates business rules
- Updates the write model
- Emits domain events
- Never returns data (except success/failure)
Commands flow through handlers that encapsulate domain logic. This isn’t just semantic—task-based commands make audit logs meaningful and enable sophisticated authorization controls.
The Query Side
Queries never alter data. Instead, they return data transfer objects (DTOs) that present the required data in a convenient format, without any domain logic. The read model is denormalized, optimized for specific views. No joins across aggregates. No complex filtering logic. Just fast data retrieval.
This is where CQRS shines: your read model can be completely different from your write model. MongoDB for writes, Elasticsearch for searches. PostgreSQL for transactions, Redis for user sessions. The query side doesn’t care how data is stored—only how it’s accessed.
2. When CQRS Actually Makes Sense
The pattern isn’t universal. Many systems do fit a CRUD mental model, and so should be done in that style. Here are the scenarios where CQRS delivers real value:
High Read-to-Write Ratios
If your system handles 1,000 reads for every write, optimizing them independently makes sense. E-commerce product catalogs, social media feeds, news sites—these benefit from read-optimized data stores that can cache aggressively without worrying about write consistency.
Complex Domain Logic on Writes
When writes involve sophisticated business rules, validation across multiple aggregates, or complex workflows, isolating this logic from read concerns simplifies both. The write model can enforce invariants without worrying about query performance.
Different Scaling Requirements
By separating the command and query responsibilities enables developers to optimize each aspect based on its unique demands. Need to scale reads to millions of requests per second but only handle thousands of writes? CQRS lets you do this without over-provisioning your write infrastructure.
Multiple Read Representations
Some systems need the same data in multiple formats: full-text search, analytics aggregations, relational queries, document retrieval. CQRS with Materialized View Pattern creates specialized read models for each use case.
Event-Driven Architectures
CQRS naturally pairs with Event Sourcing and event-driven systems. Commands produce events. Events update read models. This synchronization mechanism handles distributed state consistently.
3. Real-World Trade-offs Nobody Mentions
Eventual Consistency Isn’t Optional
The moment you separate write and read databases, you accept eventual consistency. A user clicks “Purchase,” the command succeeds, but the order might not appear in their order history for milliseconds—or seconds during high load.
This delay creates tangible UX problems. Users refresh frantically. Support tickets flood in. Your team builds complex synchronization status indicators. The architectural elegance of CQRS doesn’t eliminate these challenges—it creates them.
Operational Complexity Multiplies
Running one database is straightforward. Running two means:
- Duplicate monitoring and alerting
- Separate backup and disaster recovery procedures
- Multiple failure modes to troubleshoot
- Synchronization lag to track and debug
- Higher cloud infrastructure costs
Using a large number of databases means more points of failure, thus companies need to have comprehensive monitoring and fail-safety mechanisms in place.
Development Velocity Takes a Hit
Scaffolding tools like object-relational mapping frameworks can’t automatically generate CQRS code from a database schema, so you need custom logic to bridge the gap. Every feature now touches two systems. Schema migrations become coordination exercises. New developers face a steeper learning curve.
4. Synchronization Strategies That Actually Work
The hardest part of CQRS isn’t separation—it’s keeping read and write models in sync. Here are battle-tested approaches:
Change Data Capture (CDC)
Tools like Debezium monitor database transaction logs and stream changes to read models. This provides near-real-time sync without modifying application code. Uber uses Kafka for event streaming between write and read models, while Netflix combines CDC for database changes with Kafka for business events.
Pros: Reliable, low-latency, doesn’t require application changes
Cons: Additional infrastructure, database-specific, can’t filter business logic
Event-Driven Messaging
The command side publishes domain events like “OrderPlaced” or “UserRegistered” to message brokers (Kafka, RabbitMQ, AWS SNS). Query services subscribe and update their models.
Pros: Loose coupling, supports multiple read models, enables audit trails
Cons: Message ordering challenges, duplicate event handling, eventual consistency
Transactional Outbox Pattern
Write to an outbox table in the same transaction as the command. A separate process polls the outbox and publishes events. This guarantees events are never lost even if the message broker is temporarily unavailable.
Pros: Reliable, preserves transaction semantics
Cons: Polling overhead, slightly higher latency
Periodic Batch Synchronization
Schedule jobs that rebuild read models from the source of truth. Simple but inelegant.
Pros: Easy to implement, handles edge cases through full rebuilds
Cons: High latency, inefficient, doesn’t scale well
5. Team Size Considerations
CQRS demands expertise and coordination. The pattern’s viability depends heavily on team size and structure.
Small Teams (2-5 Developers)
Recommendation: Avoid CQRS unless absolutely necessary. The operational burden will consume your velocity. If read-heavy workloads are killing you, investigate read replicas and caching first.
Exception: If your domain naturally separates (e.g., a write-heavy admin panel and a read-heavy public API), consider lightweight CQRS with a shared database.
Mid-Size Teams (6-20 Developers)
Sweet spot for CQRS. You have enough people to specialize: some focus on command handlers and domain logic, others optimize query performance and read models. The pattern’s complexity is manageable with proper documentation and team coordination.
Key success factor: Establish clear ownership. Command side and query side should have designated maintainers who understand the synchronization mechanisms.
Large Teams (20+ Developers)
CQRS becomes easier with scale—separate teams can own different bounded contexts, each making independent CQRS decisions. CQRS should only be used on specific portions of a system, a BoundedContext in DDD lingo, and not the system as a whole.
Pitfall: Don’t mandate CQRS everywhere. Let each team choose based on their subdomain’s characteristics. Some bounded contexts benefit from CQRS. Others don’t.
6. Migration Strategies
Starting Fresh: The Greenfield Approach
If building from scratch and confident CQRS fits:
- Start with Shared Database CQRS – Separate command and query logic but use one database. This is the foundational level of CQRS, where both the read and write models share a single underlying database but maintain distinct logic for their operations. Test the pattern without operational complexity.
- Implement Event Publishing – Commands emit events. Even if query side doesn’t use them yet, this establishes the foundation.
- Add Read-Optimized Views – Create materialized views or denormalized tables specifically for queries. Monitor performance improvements.
- Separate Databases Last – Only split databases when a single one becomes a bottleneck. This is the expensive, irreversible step.
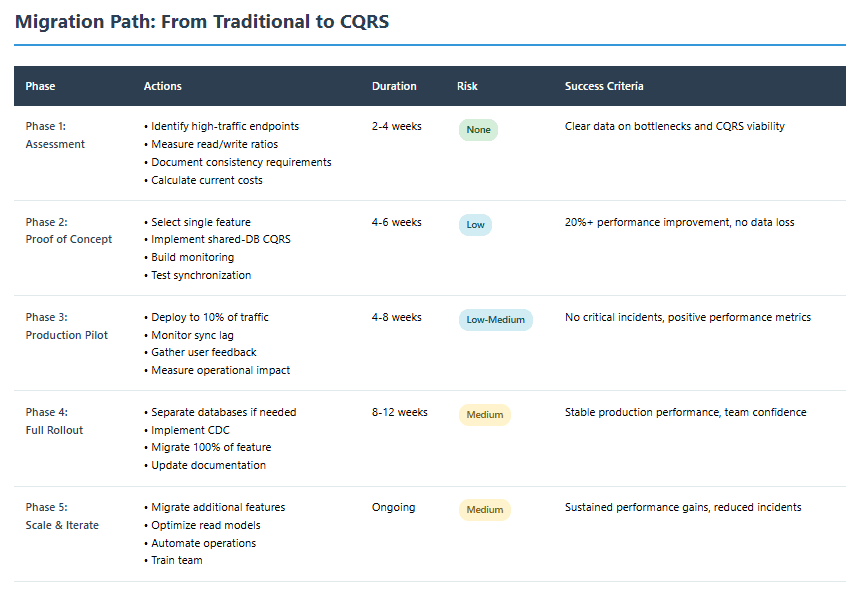
Migrating Existing Systems: The Strangler Fig Pattern
Rewriting everything into CQRS is risky. Use incremental migration:
Phase 1: Identify High-Value Candidates
Look for features with heavy read traffic, complex queries, or frequent performance complaints. These are your test cases.
Phase 2: Extract Read Model
Build a separate read-optimized model for the selected feature. Keep writes going to the existing database but redirect reads to the new model. Synchronize using CDC or events.
Phase 3: Validate and Monitor
Run in parallel. Compare results between old and new systems. Monitor synchronization lag, query performance, and error rates.
Phase 4: Extract Command Model
Once reads are stable, extract the write side. Now commands and queries are fully separated for this feature.
Phase 5: Expand Gradually
Migrate additional features only after the first proves successful. Don’t rush.
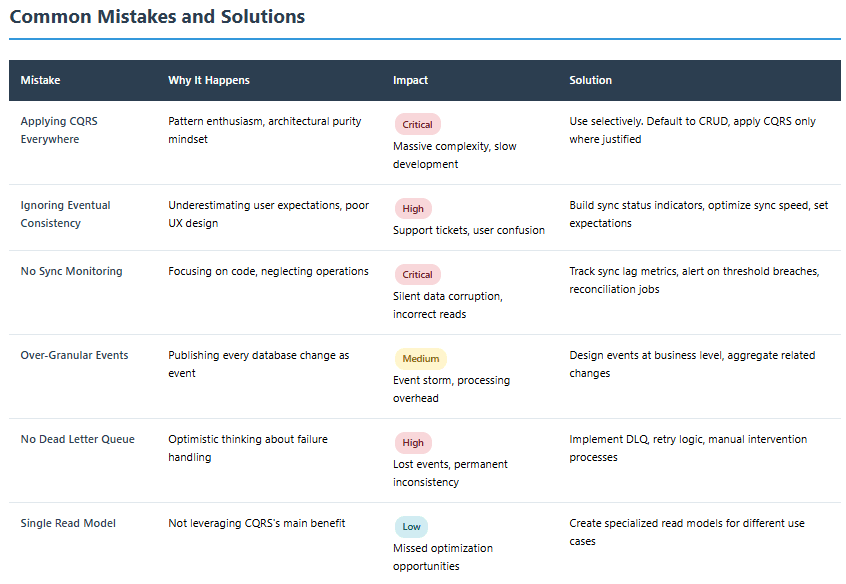
7. Common Pitfalls and How to Avoid Them
Pitfall 1: CQRS Everywhere
The biggest mistake teams make is applying CQRS universally. In instances involving simple applications or those predominantly centered around CRUD operations, the adoption of CQRS might be deemed excessive.
Solution: Default to CRUD. Use CQRS only where the benefits clearly outweigh the complexity. Most applications have a few hot paths that need optimization—not every endpoint.
Pitfall 2: Ignoring Consistency Requirements
Applications characterized by stringent consistency requirements, especially those necessitating immediate and strong consistency across read and write operations, may encounter challenges with CQRS.
Solution: For strong consistency needs (financial transactions, inventory management), either stick with traditional architectures or implement synchronous read-after-write patterns that wait for sync completion.
Pitfall 3: Underestimating Operational Costs
Teams focus on code architecture and forget infrastructure costs double. Separate databases, message brokers, synchronization services—each requires provisioning, monitoring, and maintenance.
Solution: Calculate total cost of ownership before committing. Include engineering time for operational work, not just infrastructure bills.
Pitfall 4: Poor Event Design
Commands produce events, but poorly designed events create nightmares. Too granular, and systems drown in event streams. Too coarse, and read models can’t be built efficiently.
Solution: Design events from the read model backward. What do queries need? What granularity makes rebuilding efficient? Don’t just emit every database change.
Pitfall 5: No Compensation Logic
Eventual consistency means commands can succeed even if read model updates fail. Without compensation logic, systems fall into inconsistent states permanently.
Solution: Implement dead letter queues, retry mechanisms, and reconciliation jobs that detect and fix sync failures. This isn’t optional—it’s critical infrastructure.
8. Netflix’s Lesson: When to Abandon CQRS
Netflix’s Tudum platform provides a fascinating case study in CQRS limitations. Initially built with CQRS using Kafka and Cassandra, the team concluded that, for the use case at hand, the CQRS design pattern wasn’t the optimal approach, and using a distributed, in-memory object store suited the situation better.
The problems they encountered:
- Kafka consumer logic became overly complex
- Different services duplicated logic to rebuild current state
- Events arrived out of order, causing state inconsistencies
- Schema evolution became difficult as the system matured
Their solution: Replace Kafka and Cassandra with RAW Hollow, an in-memory object store, which eliminated cache invalidation problems as the entire dataset could fit into application memory. The result was dramatically reduced data propagation times and simpler code.
The lesson: Sometimes the latest state is all that matters. If you don’t need event history, event replay, or complex event processing, CQRS might be overengineering.
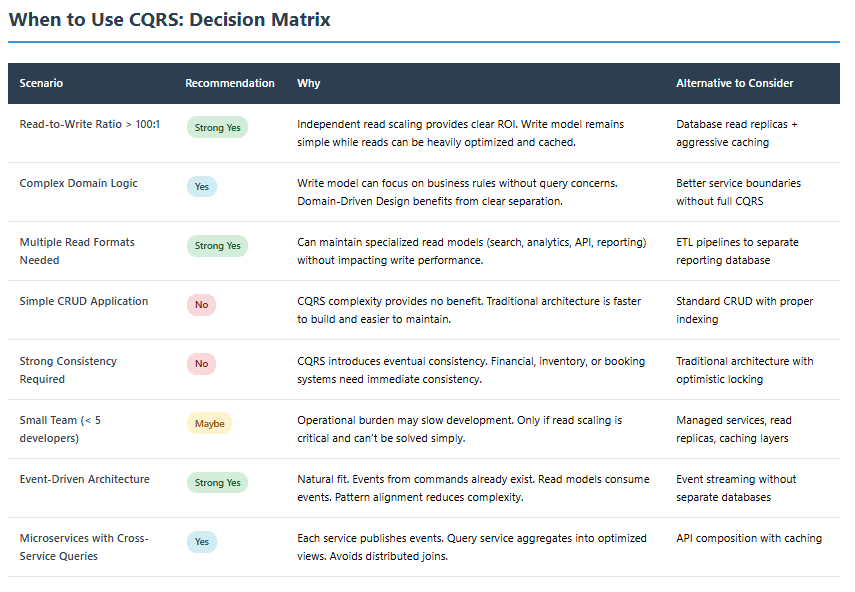
9. The Decision Framework
Use this framework to decide if CQRS is right for your system:
Consider CQRS if:
- Read-to-write ratio exceeds 10:1
- Queries require complex aggregations or multiple data formats
- Write operations involve sophisticated business logic
- You’re already using event-driven architecture
- Team size supports the operational complexity (6+ developers)
- You can accept eventual consistency for most queries
Avoid CQRS if:
- Application is primarily CRUD operations
- Strong consistency is mandatory for all operations
- Team lacks experience with distributed systems
- Operational budget is constrained
- You haven’t exhausted simpler alternatives (caching, read replicas)
Alternatives to consider first:
- Database read replicas for scaling reads
- Aggressive caching with Redis or Memcached
- Materialized views within a single database
- Vertical scaling of existing infrastructure
- Query optimization and indexing improvements
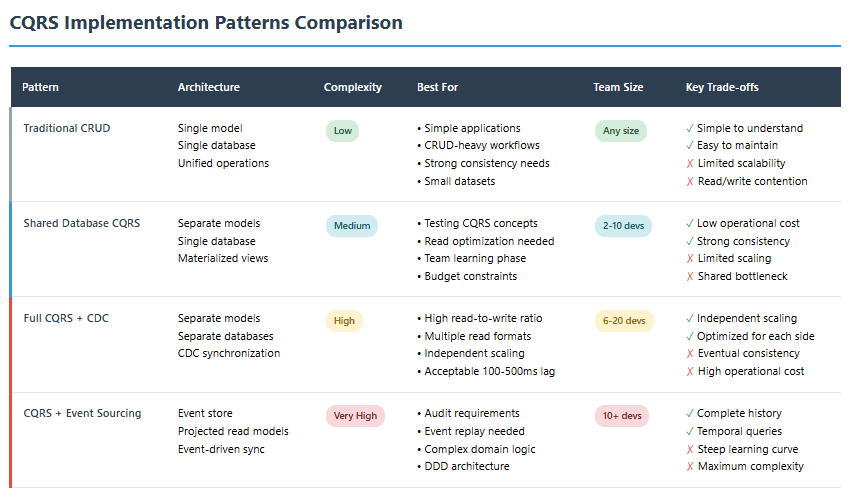
10. Implementation Patterns
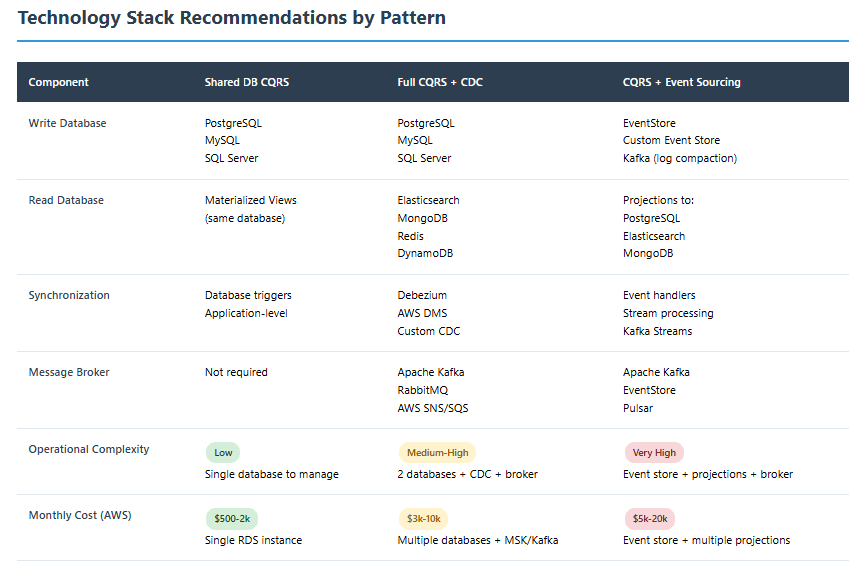
Pattern 1: Shared Database CQRS
The simplest implementation: separate command and query logic but use one database.
When to use: Testing CQRS concepts without operational complexity
Technology fit: Any relational database with view support
Team size: 2-10 developers
Pattern 2: Separate Databases with CDC
Write to a transactional database, sync to read-optimized stores via Change Data Capture.
When to use: High read volume, acceptable 100-500ms sync delay
Technology fit: PostgreSQL + Debezium + Elasticsearch/MongoDB
Team size: 6-20 developers
Pattern 3: Event Sourcing + CQRS
Store all state changes as events, project into read models.
When to use: Audit requirements, need to replay history, complex domain
Technology fit: EventStore, Kafka, custom event stores
Team size: 10+ developers with domain-driven design experience
Pattern 4: Hybrid Approach
Use CQRS for specific hot paths, traditional architecture elsewhere.
When to use: Most practical approach for real-world applications
Technology fit: Mix of patterns based on subdomain needs
Team size: Any, but easier with 6+ developers
11. Monitoring and Observability
CQRS systems have unique monitoring needs:
- Synchronization Lag Metrics
Track time between command execution and query model update. Alert when lag exceeds thresholds. This is your primary health indicator. - Event Processing Rates
Monitor event publication and consumption rates. Backlogs indicate sync problems. - Command Success Rates
Track command validation failures separately from infrastructure failures. High validation failures suggest UX or business logic issues. - Query Performance
Read models should be fast. If queries slow down, your read optimization isn’t working. - Consistency Checks
Periodically compare write and read models to detect sync failures. Automated reconciliation is crucial.
12. Tools and Technologies
Message Brokers
- Apache Kafka: Industry standard for event streaming
- RabbitMQ: Simpler alternative with good performance
- AWS SNS/SQS: Managed options for AWS environments
Databases for Read Models
- Elasticsearch: Full-text search and analytics
- MongoDB: Document-based flexible schemas
- Redis: Ultra-fast in-memory storage
Change Data Capture
- Debezium: Open-source CDC platform
- AWS DMS: Managed database migration service
- Azure Data Factory: Cloud-native ETL
CQRS Frameworks
- MediatR: .NET command/query mediator
- Axon Framework: Java CQRS and Event Sourcing framework
- NestJS CQRS: TypeScript/Node.js implementation
13. What We’ve Seen
CQRS is a powerful pattern for specific problems—not a universal architecture mandate. The separation of read and write concerns enables independent scaling, optimized data models, and clearer domain logic. But these benefits come at substantial cost: operational complexity, eventual consistency challenges, and increased development overhead.
The key insights: Use CQRS surgically, not universally. Most systems have a few high-traffic areas that benefit from optimization—not every feature needs architectural sophistication. Team size matters more than tutorials acknowledge. Small teams drown in CQRS complexity; mid-size teams hit the sweet spot; large teams can afford specialized ownership.
Real-world examples teach humility. Netflix abandoned CQRS when simpler architectures solved the same problems better. Uber uses event streaming selectively, not everywhere. The pattern works brilliantly in bounded contexts with clear read-write asymmetries but becomes an expensive liability when applied blindly.
Before choosing CQRS, exhaust simpler alternatives. Database read replicas handle many scaling challenges. Caching solves most read performance problems. Query optimization and better indexes cost nothing but time. Only when these fail—and when your team can support the operational complexity—does CQRS become the right choice.
Start simple. Migrate incrementally. Monitor religiously. And remember: the best architecture is the one your team can actually maintain.
