




 本文汇总了2024年最新的Python面试题,涵盖了算法、数据结构、字符串处理、数据库操作等多个方面。通过实际代码示例,帮助读者理解和掌握面试必备技能。同时,提供了获取系统学习资料的方式,邀请IT从业者加入技术交流圈,共同进步。
本文汇总了2024年最新的Python面试题,涵盖了算法、数据结构、字符串处理、数据库操作等多个方面。通过实际代码示例,帮助读者理解和掌握面试必备技能。同时,提供了获取系统学习资料的方式,邀请IT从业者加入技术交流圈,共同进步。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
def CountAndSay(n): ans = "1" n -= 1 while n > 0: res = "" pre = ans[0] count = 1
for i in range(1, len(ans)): if pre == ans[i]: count += 1 else:
res += str(count) + pre pre = ans[i] count = 1 res += str(count) + pre ans = res
n -= 1 return ans
题14:不使用sqrt
函数,试编写squareRoot()函数,输入一个正数,输出它的平方根的整
数部分
难度:★★★★☆ 【参考答案】
def squareRoot(x): result = 1.0
while abs(result * result - x) > 0.1: result = (result + x / result) / 2
return int(result)
三、 正则表达式(4题)
题15:请写出匹配中国大陆手机号且结尾不是4和7的正则表达式。
难度:★☆☆☆☆ 【参考答案】
import re
tels = [“159\*\*\*\*\*\*\*\*”, “14456781234”, “12345678987”, “11444777”] for tel in tels:
print(“Valid”) if (re.match(r"1\d{9}[0-3,5-6,8-9]", tel) != None) else print(“Invalid”)
题16:请写出以下代码的运行结果。
难度:★★☆☆☆
import re
str = ‘
res = re.findall(r’
结果如下: 【参考答案】
['中国 ']
题17:请写出以下代码的运行结果。
难度:★★★☆☆
import re
match = re.compile('www\....?').match("www.baidu.com") if match:
print(match.group()) else:
print("NO MATCH")
【参考答案】
www.bai
题18:请写出以下代码的运行结果。
难度:★★☆☆☆
import re
example = “
print("Result = %s" % Result.group())
【参考答案】
Result =
test1
test2
四、 列表、字典、元组、数组、矩阵(9题)
题19:使用递推式将矩阵转换为一维向量。
难度:★☆☆☆☆ 使用递推式将 [[ 1, 2 ], [ 3, 4 ], [ 5, 6 ]]
转换为
[1, 2, 3, 4, 5, 6]。 【参考答案】
a = [[1, 2], [3, 4], [5, 6]] print([j for i in a for j in i])
题20:写出以下代码的运行结果。
难度:★★★★☆
def testFun():
temp = [lambda x : i\*x for i in range(5)]
return temp
for everyLambda in testFun(): print (everyLambda(3))
结果如下: 【参考答案】
12 12 12 12 12
题21:编写Python程序,打印星号金字塔。
难度:★★★☆☆
编写尽量短的Python程序,实现打印星号金字塔。例如n=5时输出以下金字塔图形:
*
*** ***** ******* *********
参考代码如下: 【参考答案】
n = 5
for i in range(1,n+1):
print(’ ‘*(n-(i-1))+’*'*(2*i-1))
题22:获取数组的支配点。
难度:★★★☆☆
支配数是指数组中某个元素出现的次数大于数组元素总数的一半时就成为支配数,其所在下标称为支配点。编写Python
函数FindPivot(li),输入数组,输出其中的支配点和支配数,若数组中不存在支配数,输出None。
例如:[3,3,1,2,2,1,2,2,4,2,2,1,2,3,2,2,2,2,2,4,1,3,3]中共有23个元素,其中元素2出现了12次,其支配点和支配数组合是(18, 2)。 【参考答案】
def FindPivot(li): mid = len(li)/2 for l in li: count = 0 i = 0 mark = 0 while True: if l == li[i]: count += 1 temp = i i += 1
if count > mid: mark = temp
return (mark, li[mark]) if i > len(li) - 1: break
题23:将函数按照执行效率高低排序
难度:★★★☆☆
有如下三个函数,请将它们按照执行效率高低排序。
def S1(L_in):
l1 = sorted(L_in)
l2 = [i for i in l1 if i<0.5] return [i*i for i in l2]
def S2(L_in):
l1 = [i for i in L_in if i<0.5] l2 = sorted(l1)
return [i\*i for i in l2]
def S3(L_in):
l1 = [i*i for i in L_in] l2 = sorted(l1)
return [i for i in l2 if i<(0.5*0.5)]
【参考答案】
使用cProfile库即可测试三个函数的执行效率:
import random import cProfile
L_in = [random.random() for i in range(1000000)]
cProfile.run(‘S1(L_in)’) cProfile.run(‘S2(L_in)’) cProfile.run(‘S3(L_in)’)
从结果可知,执行效率从高到低依次是S2、S1、S3。
题24:螺旋式返回矩阵的元素
难度:★★★★★
给定m×n个元素的矩阵(m行,n列),编写Python
函数spiralOrder(matrix),以螺旋顺序返回矩阵的所有元素。
例如,给定以下矩阵: [[ 1, 2, 3 ], [ 4, 5, 6 ], [ 7, 8, 9 ]]
应该返回[1,2,3,6,9,8,7,4,5]
【参考答案】
def spiralOrder(matrix):
if len(matrix) == 0 or len(matrix[0]) == 0: return [] ans = []
left, up, down, right = 0, 0, len(matrix) - 1, len(matrix[0]) - 1 while left <= right and up <= down: for i in range(left, right + 1): ans += matrix[up][i], up += 1
for i in range(up, down + 1): ans += matrix[i][right], right -= 1
for i in reversed(range(left, right + 1)): ans += matrix[down][i], down -= 1
for i in reversed(range(up, down + 1)): ans += matrix[i][left], left += 1
return ans[:(len(matrix) * len(matrix[0]))]
题25:矩阵重整
难度:★★★★☆
对于一个给定的二维数组表示的矩阵,以及两个正整数r和c,分别表示所需重新整形矩阵的行数和列数。reshape函数生成一个新的矩阵,并且将原矩阵的所有元素以与原矩阵相同的行遍历顺序填充进去,将该矩阵重新整形为一个不同大小的矩阵但保留其原始数据。对于给定矩阵和参数的reshape操作是可以完成且合法的,则输出新的矩阵;否则,输出原始矩阵。请使用Python语言实现reshape函数。 例如:
输入
r, c 输出
说明
nums = [[1,2], [3,4]] r = 1,c =
4 [[1,2,3,4]]
行遍历的是[1,2,3,4]。新的重新形状矩阵是1 \* 4矩阵,使用前面的列表逐行填充。
nums = [[1,2], [3,4]]
r = 2,c =
4
[[1,2], [3,4]]
无法将2 \* 2矩阵重新整形为2 \* 4矩阵。所以输出原始矩阵。
注意:给定矩阵的高度和宽度在[1,100]范围内。给定的r和c都是正数。
【参考答案】
def matrixReshape(nums, r, c): “”"
if r * c != len(nums) * len(nums[0]): return nums m = len(nums) n = len(nums[0])
ans = [[0] * c for _ in range®] for i in range(r * c):
ans[i / c][i % c] = nums[i / n][i % n] return ans
题26:查找矩阵中第k个最小元素。
难度:★★★★☆
给定n×n矩阵,其中每行每列元素均按升序排列,试编写Python函数kthSmallest(matrix, k),找到矩阵中的第k个最小元素。
注意:查找的是排序顺序中的第k个最小元素,而不是第k个不同元素。 例如: 矩阵= [[1,5,9], [10,11,13], [12,13,15]] k = 8,应返回13。
【参考答案】
import heapq
def kthSmallest(matrix, k): visited = {(0, 0)}
heap = [(matrix[0][0], (0, 0))]
while heap:
val, (i, j) = heapq.heappop(heap) k -= 1 if k == 0: return val
if i + 1 < len(matrix) and (i + 1, j) not in visited:
heapq.heappush(heap, (matrix[i + 1][j], (i + 1, j))) visited.add((i + 1, j))
if j + 1 < len(matrix) and (i, j + 1) not in visited: heapq.heappush(heap, (matrix[i][j + 1], (i, j + 1))) visited.add((i, j + 1))
题27:试编写函数largestRectangleArea(),求一幅柱状图中包含的最大矩形的面积。
难度:★★★★★ 例如对于下图:
输入:[2,1,5,6,2,3] 输出:10
【参考答案】
def largestRectangleArea(heights): stack=[] i=0 area=0
while i<len(heights):
if stack==[] or heights[i]>heights[stack[len(stack)-1]]: # 递增直接入栈
stack.append(i) else: # 不递增开始弹栈
curr=stack.pop() if stack == []: width = i else:
width = i-stack[len(stack)-1]-1 area=max(area,width\*heights[curr]) i-=1 i+=1
while stack != []: curr = stack.pop() if stack == []: width = i else:
width = len(heights)-stack[len(stack)-1]-1 area = max(area,width*heights[curr]) return area
五、 设计模式(3
题)
题28:使用Python语言实现单例模式。
难度:★★★☆☆
【参考答案】
class Singleton(object):
def __new__(cls, *args, **kw): if not hasattr(cls, ‘_instance’): orig = super(Singleton, cls)
cls._instance = orig.__new__(cls, *args, **kw) return cls._instance
题29:使用Python语言实现工厂模式。
难度:★★★★☆
编写适当的Python程序,完成以下功能: 1. 定义基类Person,含有获取名字,性别的方法。 2. 定义Person类的两个子类Male和Female,含有打招呼的方法。 3. 定义工厂类,含有getPerson方法,接受两个输入参数:名字和性别。 4. 用户通过调用getPerson方法使用工厂类。
【参考答案】
class Person:
def __init__(self): self.name = None self.gender = None
def getName(self): return self.name
def getGender(self): return self.gender
class Male(Person):
def __init__(self, name): print(“Hello Mr.” + name)
class Female(Person):
def __init__(self, name): print(“Hello Miss.” + name)
class Factory:
def getPerson(self, name, gender): if(gender == ‘M’): return Male(name) if(gender == ‘F’): return Female(name)
if name == ‘__main__’: factory = Factory()
person = factory.getPerson(“Huang”, “M”)
题30:使用Python语言实现观察者模式。
难度:★★★★★
给定一个数字,现有的默认格式化显示程序以十进制格式显示此数字。请编写适当的Python程序,实现支持添加(注册)更多的格式化程序(如添加一个十六进制格式化程序和一个二进制格式化程序)。每次数值更新时,已注册的程序就会收到通知,并显示更新后的值。
【参考答案】
import itertools class Publisher: def __init__(self): self.observers = set()
def add(self, observer, *observers):
for observer in itertools.chain((observer, ), observers): self.observers.add(observer)
observer.update(self)
def remove(self, observer): try:
self.observers.discard(observer) except ValueError:
print(‘移除 {} 失败!’.format(observer))
def notify(self):
[observer.update(self) for observer in self.observers]
class DefaultFormatter(Publisher): def __init__(self, name): Publisher.__init__(self) self.name = name self._data = 0
def __str__(self):
return “{}: ‘{}’ 的值 = {}”.format(type(self).name, self.name, self._data)
@property def data(self): return self._data
@data.setter
def data(self, new_value): try:
self._data = int(new_value) except ValueError as e: print(‘错误: {}’.format(e)) else:
self.notify()
class HexFormatter:
def update(self, publisher):
print(“{}: ‘{}’ 的十六进制值 = {}”.format(type(self).name, publisher.name, hex(publisher.data)))
class BinaryFormatter:
def update(self, publisher):
print(“{}: ‘{}’ 的二进制值 = {}”.format(type(self).name, publisher.name, bin(publisher.data)))
def main():
df = DefaultFormatter(‘test1’) print(df)
hf = HexFormatter()
df.add(hf) df.data = 37 print(df)
bf = BinaryFormatter() df.add(bf) df.data = 23 print(df)
df.remove(hf) df.data = 56 print(df)
df.remove(hf) df.add(bf)
df.data = ‘hello’ print(df)
df.data = 7.2 print(df)
if name == ‘__main__’: main()
六、 树、二叉树、图(5题)
题31:使用Python编写实现二叉树前序遍历的函数preorder(root, res=[])。
难度:★★☆☆☆ 【参考答案】
def preorder(root, res=[]): if not root: return
res.append(root.val) preorder(root.left,res) preorder(root.right,res) return res
题32:使用Python实现一个二分查找函数。
难度:★★★☆☆
【参考答案】
def binary_search(num_list, x): num_list = sorted(num_list) left, right = 0, len(num_list) - 1 while left <= right:
mid = (left + right) // 2 if num_list[mid] > x: right = mid - 1 elif num_list[mid] < x: left = mid + 1 else:
return ‘待查元素{0}在排序后列表中的下标为:
{1}’.format(x, mid) return ‘待查找元素%s不存在指定列表中’ %x
题
33:编写Python函数maxDepth(),实现获取二叉树root最大深度。
难度:★★★★☆ 【参考答案】
def maxDepth(self, root): if root == None: return 0
return max(self.maxDepth(root.left),self.maxDepth(root.right))+1
题34:输入两棵二叉树Root1、Root2,判断Root2是否Root1的子结构(子树)。
难度:★★★★☆ 【参考答案】
class TreeNode:
def __init__(self, x): self.val = x self.left = None self.right = None
def istree(pRoot1, pRoot2): if not pRoot2: return True
if not pRoot1 and pRoot2: return False
if pRoot1.val != pRoot2.val: return False
elif pRoot1.val == pRoot2.val:
return istree(pRoot1.left, pRoot2.left) and istree(pRoot1.right, pRoot2.right)
def HasSubtree(pRoot1, pRoot2): if not pRoot1 or not pRoot2: return False
if pRoot1.val == pRoot2.val: return istree(pRoot1, pRoot2) else:
return HasSubtree(pRoot1.left, pRoot2) or HasSubtree(pRoot1.right, pRoot2)
题35:判断数组是否某棵二叉搜索树后序遍历的结果。
难度:★★★★☆
编写函数VerifySquenceOfBST(sequence),实现以下功能:输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历的结果。如果是则输出True,否则输出False。假设输入数组的任意两个数字都互不相同。 【参考答案】
def VerifySquenceOfBST(sequence): if not sequence:
return False i= 0
for i in range(len(sequence)-1):
if sequence[i]>sequence[-1]: break
if i < len(sequence)-2:
for j in range(i+1,len(sequence)-1): if sequence[j]<sequence[-1]: return False left = True right = True if i>0:
left = VerifySquenceOfBST(sequence[:i]) elif i< len(sequence)-2:
right = VerifySquenceOfBST(sequence[i:-1]) return left and right
七、 文件操作(3题)
题36:计算test.txt中的大写字母数。
难度:★☆☆☆☆ 【参考答案】
import os os.chdir(‘D:\’)
with open(‘test.txt’) as test: count = 0
for i in test.read(): if i.isupper(): count+=1
print(count)
题37:补全缺失的代码。
难度:★★☆☆☆
def print\_directory\_contents(sPath): # 补充该函数的实现代码
print\_directory\_contents()函数接受文件夹路径名称作为输入参数,返回其中包含的所有子文件夹和文件的完整路径。
【参考答案】
def print_directory_contents(sPath): import os
for sChild in os.listdir(sPath):
sChildPath = os.path.join(sPath,sChild) if os.path.isdir(sChildPath):
print_directory_contents(sChildPath) else:
print(sChildPath)
题38:设计内存中的文件系统。
难度:★★★★☆
使用Python语言设计内存中的文件系统,实现以下命令。
ls:给定字符串格式的路径。如果是文件路径,则返回仅包含此文件名称的列表。如果是目录路径,则返回此目录中的文件和目录名称列表。输出结果(文件和目录名称)应按字典顺序排列。
mkdir:如果目录路径不存在,则应根据路径创建新目录。如果路径中的中间目录也不存在,则也应该创建它们。此函数具有void返回类型。 注:
可以假设所有文件或目录路径都是以/开头并且不以/结尾的绝对路径,除了路径只是“/”。 可以假设所有操作都将传递有效参数,用户不会尝试检索文件内容或列出不存在的目录或文件。 可以假设所有目录名称和文件名只包含小写字母,并且同一目录中不存在相同的名称。
【参考答案】
class FileNode(object): def __init__(self, name): self.isFolder = True self.childs = {} self.name = name self.data = “”
class FileSystem(object): def __init__(self):
self.root = FileNode(“/”)
def ls(self, path):
fd = self.lookup(path, False) if not fd: return [] if not fd.isFolder: return [fd.name] files = []
for file in fd.childs: files.append(file) files.sort() return files
def lookup(self, path, isAutoCreate): path = path.split(“/”) p = self.root for name in path: if not name: continue
if name not in p.childs: if isAutoCreate:
p.childs[name] = FileNode(name) else:
return None p = p.childs[name] return p
def mkdir(self, path):
self.lookup(path, True) # 测试
obj = FileSystem() obj.mkdir(“/test/path”) obj.ls(“/test”)
八、 网络编程(4题)
题39:请至少说出三条TCP和UDP协议的区别。
难度:★★☆☆☆
【参考答案】
(1) TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连
接。
(2) TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序
到达;UDP尽最大努力交付,即不保证可靠交付。
(3) TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的,UDP没
有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)。
(4) 每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信。 (5) TCP首部开销20字节;UDP的首部开销小,只有8个字节。
(6) TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道。
题40:请简述Cookie和Session的区别。
难度:★☆☆☆☆
【参考答案】
(1) Session在服务器端,Cookie在客户端(浏览器)。
(2) Session可以存放在文件、数据库或内存中,默认以文件方式保存。 (3) Session的运行依赖Session ID,而Session ID保存在Cookie中。因此,如果浏览器禁用了Cookie,
同时Session也会失效。
题41:请简述向服务器端发送请求时的GET方式与POST方式的区别。
难度:★☆☆☆☆
【参考答案】
(1) 在浏览器回退时GET方式没有变化,而POST会再次提交请求。 (2) GET请求会被浏览器主动缓存,而POST不会,除非手动设置。 (3) GET请求只能进行URL编码,而POST支持多种编码方式。
(4) GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。 (5) 对参数的数据类型,GET只接受ASCII字符,而POST没有限制。
(6) GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。
(7) GET参数通过URL传递且传送的参数是有长度限制的,POST放在Request body中且长度没有
限制。
(8) 对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数
据);而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
题42:使用threading组件编写支持多线程的Socket服务端。
难度:★★★★☆
使用Python语言的threading组件编写支持多线程的Socket服务端,支持-x和-p参数,分别表示指定最大连接数和监听端口。
【参考答案】
import socket
import threading,getopt,sys,string
opts, args = getopt.getopt(sys.argv[1:], “hp:l:”,[“help”,“port=”,“list=”]) list=50 port=8001
for op, value in opts:
if op in (“-x”,“–maxconn”): list = int(value) elif op in (“-p”,“–port”): port = int(value)
def Config(client, address): try:
client.settimeout(500) buf = client.recv(2048) client.send(buf) except socket.timeout: print(‘time out’) client.close()
def main():
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sock.bind((‘localhost’, port)) sock.listen(list) while True:
client,address = sock.accept()
thread = threading.Thread(target=Config, args=(client, address)) thread.start()
if name == ‘__main__’: main()
九、 数据库编程(6题)
题43:简述数据库的第一、第二、第三范式的内容。
难度:★★☆☆☆
【参考答案】
范式是“符合某一种级别的关系模式的集合,表示一个关系内部各属性之间的联系的合理化程度”,实际上就是一张数据表的表结构所符合的某种设计标准的级别。
1NF的定义为:符合1NF的关系中的每个属性都不可再分。1NF是所有关系型数据库的最基本要求。 2NF在1NF的基础之上,消除了非主属性对于码的部分函数依赖。判断步骤如下。 第一步:找出数据表中所有的码。
第二步:根据第一步所得到的码,找出所有的主属性。
第三步:数据表中,除去所有的主属性,剩下的就都是非主属性了。 第四步:查看是否存在非主属性对码的部分函数依赖。
3NF在2NF的基础之上,消除了非主属性对于码的传递函数依赖。
题44:根据以下数据表结构和数据,按照要求编写SQL语句。
难度:★★☆☆☆
数据库中现有Course、Score、Student和Teacher四张数据表,其中数据分别如下所示。
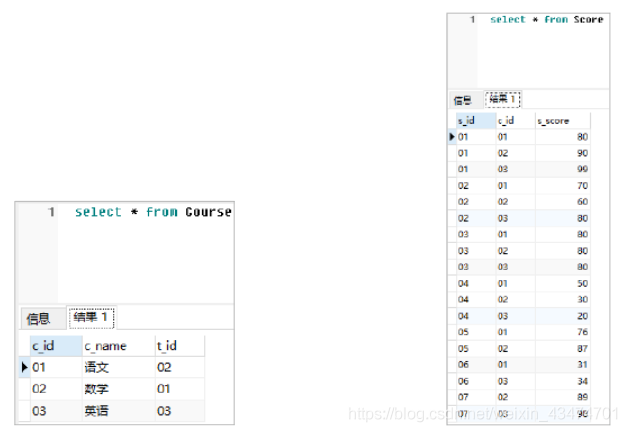
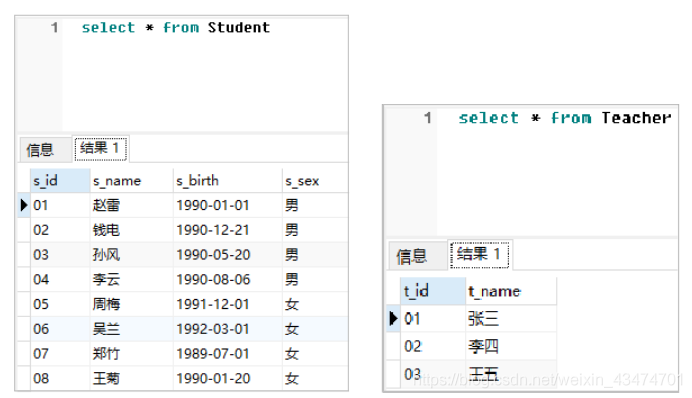
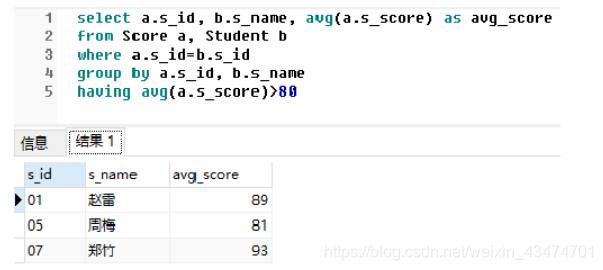
试编写SQL语句,查询平均成绩大于80的所有学生的学号、姓名和平均成绩。
【参考答案(使用SQLServer)】
select a.s_id, b.s_name, avg(a.s_score) as avg_score from Score a, Student b where a.s_id=b.s_id group by a.s_id, b.s_name having avg(a.s_score)>80
查询结果如下:
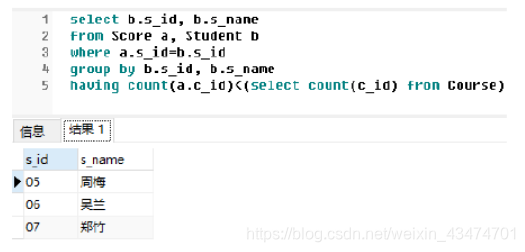
题45:按照44题所给条件,编写SQL语句查询没有学全所有课程的学生信息。
难度:★★☆☆☆
【参考答案(使用SQLServer)】
select b.s_id, b.s_name from Score a, Student b where a.s_id=b.s_id
group by b.s_id, b.s_name
having count(a.c_id)<(select count(c_id) from Course)
查询结果如下:
题46:按照44题所给条件,编写SQL语句查询所有课程第2
名和第3名的学生信息及该课
程成绩。
难度:★★★★☆
【参考答案(使用SQLServer)】
select * from (
select a.s_id, b.s_name, b.s_birth, b.s_sex, a.c_id, a.s_score, row_number() over (partition by a.c_id order by a.s_score desc) rno from Score a, Student b where a.s_id=b.s_id
) as a where a.rno in (2, 3) order by c_id, rno
查询结果如下:
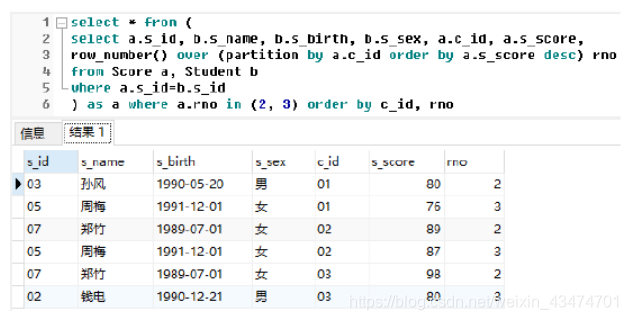
题47:按照44题所给条件,编写SQL语句查询所教课程有2人及以上不及格的教师、课
程、学生信息及该课程成绩。
难度:★★★☆☆
【参考答案(使用SQLServer)】
select a.s_id, d.s_name, a.s_score, a.c_id, b.c_name, b.t_id, c.t_name from Score a, Course b, Teacher c, Student d
where a.c_id=b.c_id and b.t_id=c.t_id and a.s_id=d.s_id and a.s_score<60 and c.t_id in ( SELECT c.t_id
FROM Score a, Course b, Teacher c
where a.c_id=b.c_id and b.t_id=c.t_id and a.s_score<60 group by c.t_id having count(1)>1
)
查询结果如下:
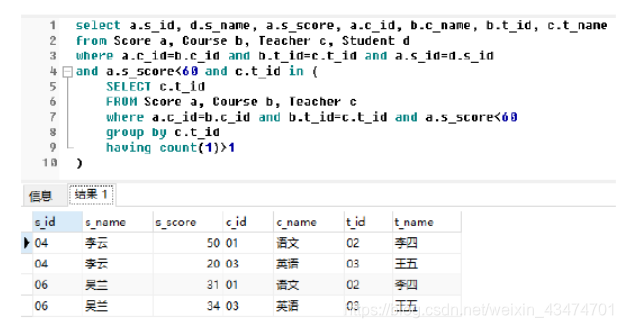
题48:按照44题所给条件,编写SQL语句生成每门课程的一分段表(课程ID、课程名
称、分数、该课程该分数人数、该课程累计人数)。
难度:★★★★☆
【参考答案(使用SQLServer)】
select a.c_id, b.c_name, a.s_score, COUNT(1) 人数,
(select COUNT(1) from Score c where c.c_id=a.c_id and c.s_score>=a.s_score) 累计人数 from Score a, Course b where a.c_id=b.c_id
group by a.c_id, b.c_name, a.s_score order by a.c_id, b.c_name, a.s_score desc;
查询结果如下:
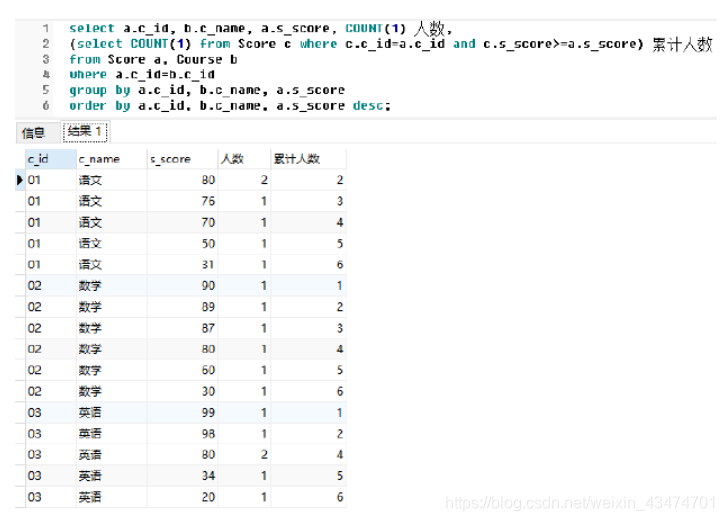
十、 图形图像与可视化(2题)
题49:绘制一个二次函数的图形,并同时画出使用梯形法求积分时的各个梯形。
难度:★★★☆☆
【参考答案】
以𝑓(𝑥)=6𝑥2+7𝑥+13为例,代码如下:
def Quadratic_Function(x):
return 6\*x\*\*2 + 7\*x + 13
import numpy as np
import matplotlib.pyplot as plt from ipywidgets import interact
def plot_ladder(laddernum):
x = np.linspace(-5, 5, num=100) y = Quadratic_Function(x) plt.plot(x, y)
a = np.linspace(-5, 5, num=laddernum) for i in range(laddernum):
plt.plot([a[i], a[i]], [0, Quadratic_Function(a[i])], color=“blue”)
ladders = []
for i in range(laddernum):
ladders.append([a[i], Quadratic_Function(a[i])])
npladders = np.array(ladders)
plt.plot(npladders[:,0], npladders[:,1])
interact(plot_ladder, laddernum=(1, 80, 1))
运行结果如下(使用Jupyter Notebook):
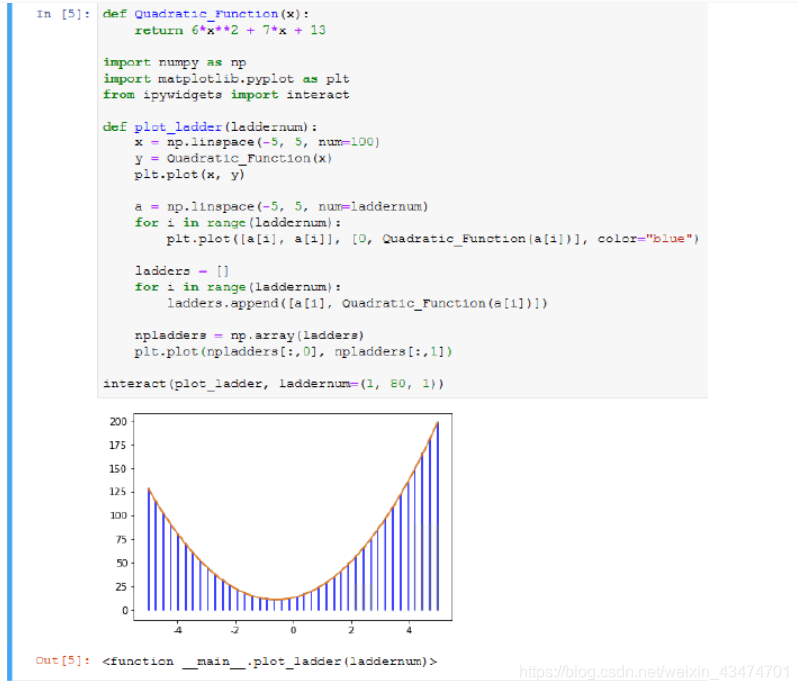
题50:将给定数据可视化并给出分析结论
难度:★★★☆☆
某门店部分顾客的年龄、月收入以及每月平均在本店消费情况如下表所示。

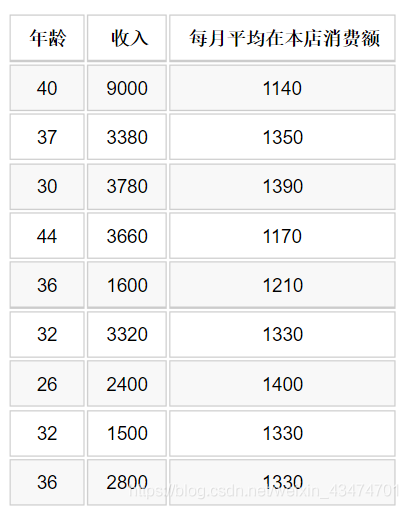
请据此使用Python语言绘制适当的图形并分析得到结论。 【参考答案】
import matplotlib.pyplot as plt plt.figure(figsize=(10, 5)) # 年龄
age = [34, 40, 37, 30, 44, 36, 32, 26, 32, 36] # 收入
income = [7000, 9000, 3380, 3780, 3660, 1600, 3320, 2400, 1500, 2800] # 消费额
expense = [1230, 1140, 1350, 1390, 1170, 1210, 1330, 1400, 1330, 1330] # 年龄,收入 散点图 ax1 = plt.subplot(121) ax1.scatter(age, income)
ax1.set_title(‘年龄,收入 散点图’, family=‘kaiti’, size=16) # 年龄,消费额 散点图 ax2 = plt.subplot(122) ax2.scatter(age, expense)
ax2.set_title(‘年龄,消费额 散点图’, family=‘kaiti’, size=16) plt.show()

从图中可以看到,顾客年龄与消费额几近负相关,收入与消费额也几乎负相关,而年龄与收入之间没有特别明显的关联关系。
**140.对Flask蓝图(Blueprint)的理解?**
蓝图的定义
蓝图 /Blueprint 是Flask应用程序组件化的方法,可以在一个应用内或跨越多个项目共用蓝图。使用蓝图可以极大简化大型应用的开发难度,也为Flask扩展提供了一种在应用中注册服务的集中式机制。 蓝图的应用场景:
把一个应用分解为一个蓝图的集合。这对大型应用是理想的。一个项目可以实例化一个应用对象,初始化几个扩展,并注册一集合的蓝图。
以URL前缀和/或子域名,在应用上注册一个蓝图。URL前缀/子域名中的参数即成为这个蓝图下的所有视图函数的共同的视图参数(默认情况下) 在一个应用中用不同的URL规则多次注册一个蓝图。
通过蓝图提供模板过滤器、静态文件、模板和其他功能。一个蓝图不一定要实现应用或视图函数。
初始化一个Flask扩展时,在这些情况中注册一个蓝图。 蓝图的缺点:
不能在应用创建后撤销注册一个蓝图而不销毁整个应用对象。 使用蓝图的三个步骤 1.创建一个蓝图对象
blue = Blueprint(“blue”,**name**)
2.在这个蓝图对象上进行操作,例如注册路由、指定静态文件夹、注册模板过滤器…
@blue.route(‘/’) def blue\_index():
return “Welcome to my blueprint”
3.在应用对象上注册这个蓝图对象
app.register_blueprint(blue,url_prefix="/blue")
141.Flask 和 Django 路由映射的区别?
在django中,路由是浏览器访问服务器时,先访问的项目中的url,再由项目中的url找到应用中url,这些url是放在一个列表里,遵从从前往后匹配的规则。在flask中,路由是通过装饰器给每个视图函数提供的,而且根据请求方式的不同可以一个url用于不同的作用。
Django
142.什么是wsgi,uwsgi,uWSGI?
WSGI:
web服务器网关接口,是一套协议。用于接收用户请求并将请求进行初次封装,然后将请求交给web框架。
实现wsgi协议的模块:wsgiref,本质上就是编写一socket服务端,用于接收用户请求(django)
werkzeug,本质上就是编写一个socket服务端,用于接收用户请求(flask) uwsgi:
与WSGI一样是一种通信协议,它是uWSGI服务器的独占协议,用于定义传输信息的类型。 uWSGI:
是一个web服务器,实现了WSGI的协议,uWSGI协议,http协议
143.Django、Flask、Tornado的对比?
1、 Django走的大而全的方向,开发效率高。它的MTV框架,自带的
ORM,admin后台管理,自带的sqlite数据库和开发测试用的服务器,给开发者提高了超高的开发效率。 重量级web框架,功能齐全,提供一站式解决的思路,能让开发者不用在选择上花费大量时间。
自带ORM和模板引擎,支持jinja等非官方模板引擎。
自带ORM使Django和关系型数据库耦合度高,如果要使用非关系型数据库,需要使用第三方库 自带数据库管理app 成熟,稳定,开发效率高,相对于Flask,Django的整体封闭性比较好,适合做企业级网站的开发。python web框架的先驱,第三方库丰富
2、 Flask 是轻量级的框架,自由,灵活,可扩展性强,核心基于Werkzeug WSGI工具 和jinja2 模板引擎
适用于做小网站以及web服务的API,开发大型网站无压力,但架构需要自己设计
与关系型数据库的结合不弱于Django,而与非关系型数据库的结合远远优于Django
3、 Tornado走的是少而精的方向,性能优越,它最出名的异步非阻塞的设计方式
Tornado的两大核心模块:
iostraem:对非阻塞的socket进行简单的封装 ioloop: 对I/O 多路复用的封装,它实现一个单例
144.CORS 和 CSRF的区别?
什么是CORS?
CORS是一个W3C标准,全称是“跨域资源共享"(Cross-origin resoure sharing). 它允许浏览器向跨源服务器,发出XMLHttpRequest请求,从而客服了AJAX只能同源使用的限制。 什么是CSRF?
CSRF主流防御方式是在后端生成表单的时候生成一串随机token,内置到表单里成为一个字段,同时,将此串token置入session中。每次表单提交到后端时都会检查这两个值是否一致,以此来判断此次表单提交是否是可信的,提交过一次之后,如果这个页面没有生成CSRF token,那么token将会被清空,如果有新的需求,那么token会被更新。 攻击者可以伪造POST表单提交,但是他没有后端生成的内置于表单的token,session中没有token都无济于事。
145.Session,Cookie,JWT的理解
为什么要使用会话管理
众所周知,HTTP协议是一个无状态的协议,也就是说每个请求都是一个独立的请求,请求与请求之间并无关系。但在实际的应用场景,这种方式并不能满足我们的需求。举个大家都喜欢用的例子,把商品加入购物车,单独考虑这个请求,服务端并不知道这个商品是谁的,应该加入谁的购物车?因此这个请求的上下文环境实际上应该包含用户的相关信息,在每次用户发出请求时把这一 小部分额外信息,也做为请求的一部分,这样服务端就可以根据上下文中的信息,针对具体的用户进行操作。所以这几种技术的出现都是对HTTP协议的一个补充,使得我们可以用HTTP协议+状态管理构建一个的面向用户的WEB应用。
Session 和Cookie的区别
这里我想先谈谈session与cookies,因为这两个技术是做为开发最为常见的。那么session与cookies的区别是什么?个人认为session与cookies最核心区别在于额外信息由谁来维护。利用cookies来实现会话管理时,用户的相关信息或者其他我们想要保持在每个请求中的信息,都是放在cookies中,而
cookies是由客户端来保存,每当客户端发出新请求时,就会稍带上cookies,服务端会根据其中的信息进行操作。 当利用session来进行会话管理时,客户端实际上只存了一个由服务端发送的session\_id,而由这个session\_id,可以在服务端还原出所需要的所有状态信息,从这里可以看出这部分信息是由服务端来维护的。
除此以外,session与cookies都有一些自己的缺点: cookies的安全性不好,攻击者可以通过获取本地cookies进行欺骗或者利用cookies进行CSRF攻击。使用cookies时,在多个域名下,会存在跨域问题。 session 在一定的时间里,需要存放在服务端,因此当拥有大量用户时,也会大幅度降低服务端的性能,当有多台机器时,如何共享session也会是一个问题.(redis集群)也就是说,用户第一个访问的时候是服务器A,而第二个请求被转发给了服务器B,那服务器B如何得知其状态。实际上,session与cookies是有联系的,比如我们可以把session\_id存放在cookies中的。 JWT是如何工作的
首先用户发出登录请求,服务端根据用户的登录请求进行匹配,如果匹配成功,将相关的信息放入payload中,利用算法,加上服务端的密钥生成
token,这里需要注意的是secret\_key很重要,如果这个泄露的话,客户端就可以随机篡改发送的额外信息,它是信息完整性的保证。生成token后服务端将其返回给客户端,客户端可以在下次请求时,将token一起交给服务端,一般是说我们可以将其放在Authorization首部中,这样也就可以避免跨域问题。
146.简述Django请求生命周期
一般是用户通过浏览器向我们的服务器发起一个请求(request),这个请求会去访问视图函数,如果不涉及到数据调用,那么这个时候视图函数返回一个模板也就是一个网页给用户) 视图函数调用模型毛模型去数据库查找数据,然后逐级返回,视图函数把返回的数据填充到模板中空格中,最后返回网页给用户。 1.wsgi ,请求封装后交给web框架(Flask,Django)
2.中间件,对请求进行校验或在请求对象中添加其他相关数据,例如:csrf,request.session
3.路由匹配 根据浏览器发送的不同url去匹配不同的视图函数 4.视图函数,在视图函数中进行业务逻辑的处理,可能涉及到:orm,templates
5.中间件,对响应的数据进行处理 6.wsgi,将响应的内容发送给浏览器
147.用的restframework完成api发送时间时区
当前的问题是用django的rest framework模块做一个get请求的发送时间以及时区信息的api
class getCurrenttime(APIView): def get(self,request):
local_time = time.localtime()
time_zone =settings.TIME_ZONE
temp = {‘localtime’:local_time,‘timezone’:time_zone} return Response(temp)
148.nginx,tomcat,apach到都是什么?
Nginx(engine x)是一个高性能的HTTP和反向代理服务器,也是 一个IMAP/POP3/SMTP服务器,工作在OSI七层,负载的实现方式:轮询,
IP\_HASH,fair,session\_sticky. Apache HTTP Server是一个模块化的服务器,源于NCSAhttpd服务器 Tomcat 服务器是一个免费的开放源代码的Web应用服务器,属于轻量级应用服务器,是开发和调试JSP程序的首选。
149.请给出你熟悉关系数据库范式有哪些,有什么作用?
在进行数据库的设计时,所遵循的一些规范,只要按照设计规范进行设计,就能设计出没有数据冗余和数据维护异常的数据库结构。
数据库的设计的规范有很多,通常来说我们在设是数据库时只要达到其中一些规范就可以了,这些规范又称之为数据库的三范式,一共有三条,也存在着其他范式,我们只要做到满足前三个范式的要求,就能设陈出符合我们的数据库了,我们也不能全部来按照范式的要求来做,还要考虑实际的业务使用情况,所以有时候也需要做一些违反范式的要求。 1.数据库设计的第一范式(最基本),基本上所有数据库的范式都是符合第一范式的,符合第一范式的表具有以下几个特点:
数据库表中的所有字段都只具有单一属性,单一属性的列是由基本的数据类型(整型,浮点型,字符型等)所构成的设计出来的表都是简单的二比表 2.数据库设计的第二范式(是在第一范式的基础上设计的),要求一个表中只具有一个业务主键,也就是说符合第二范式的表中不能存在非主键列对只对部分主键的依赖关系
3.数据库设计的第三范式,指每一个非主属性既不部分依赖与也不传递依赖于业务主键,也就是第二范式的基础上消除了非主属性对主键的传递依赖
150.简述QQ登陆过程
qq登录,在我们的项目中分为了三个接口,
第一个接口是请求qq服务器返回一个qq登录的界面;
第二个接口是通过扫码或账号登陆进行验证,qq服务器返回给浏览器一个code和state,利用这个code通过本地服务器去向qq服务器获取
access\_token覆返回给本地服务器,凭借access\_token再向qq服务器获取用户的openid(openid用户的唯一标识)
第三个接口是判断用户是否是第一次qq登录,如果不是的话直接登录返回的jwt-token给用户,对没有绑定过本网站的用户,对openid进行加密生成token进行绑定
151.post 和 get的区别?
1.GET是从服务器上获取数据,POST是向服务器传送数据
2.在客户端,GET方式在通过URL提交数据,数据在URL中可以看到,POST方式,数据放置在HTML——HEADER内提交
3.对于GET方式,服务器端用Request.QueryString获取变量的值,对于POST方式,服务器端用Request.Form获取提交的数据
152.项目中日志的作用
一、日志相关概念
1.日志是一种可以追踪某些软件运行时所发生事件的方法
2.软件开发人员可以向他们的代码中调用日志记录相关的方法来表明发生了某些事情
3.一个事件可以用一个包含可选变量数据的消息来描述
4.此外,事件也有重要性的概念,这个重要性也可以被成为严重性级别(level) 二、日志的作用
1.通过log的分析,可以方便用户了解系统或软件、应用的运行情况; 2.如果你的应用log足够丰富,可以分析以往用户的操作行为、类型喜好,地域分布或其他更多信息;
3.如果一个应用的log同时也分了多个级别,那么可以很轻易地分析得到该应用的健康状况,及时发现问题并快速定位、解决问题,补救损失。
4.简单来讲就是我们通过记录和分析日志可以了解一个系统或软件程序运行情况是否正常,也可以在应用程序出现故障时快速定位问题。不仅在开发中,在运维中日志也很重要,日志的作用也可以简单。总结为以下几点: 1.程序调试
2.了解软件程序运行情况,是否正常 3,软件程序运行故障分析与问题定位
4,如果应用的日志信息足够详细和丰富,还可以用来做用户行为分析
153.django中间件的使用?
Django在中间件中预置了六个方法,这六个方法的区别在于不同的阶段执行,对输入或输出进行干预,方法如下:
1.初始化:无需任何参数,服务器响应第一个请求的时候调用一次,用于确定是否启用当前中间件
def **init**(): pass
2.处理请求前:在每个请求上调用,返回None或HttpResponse对象。
def process\_request(request): pass
3.处理视图前:在每个请求上调用,返回None或HttpResponse对象。
def process\_view(request,view\_func,view\_args,view\_kwargs): pass
4.处理模板响应前:在每个请求上调用,返回实现了render方法的响应对象。
def process\_template\_response(request,response): pass
5.处理响应后:所有响应返回浏览器之前被调用,在每个请求上调用,返回HttpResponse对象。 def process\_response(request,response): pass
6.异常处理:当视图抛出异常时调用,在每个请求上调用,返回一个HttpResponse对象。
def process\_exception(request,exception): pass
154.谈一下你对uWSGI和nginx的理解?
1.uWSGI是一个Web服务器,它实现了WSGI协议、uwsgi、http等协议。Nginx中HttpUwsgiModule的作用是与uWSGI服务器进行交换。WSGI是一种Web服务器网关接口。它是一个Web服务器(如nginx,uWSGI等服务器)与web应用(如用Flask框架写的程序)通信的一种规范。 要注意WSGI/uwsgi/uWSGI这三个概念的区分。 WSGI是一种通信协议。
uwsgi是一种线路协议而不是通信协议,在此常用于在uWSGI服务器与其他网络服务器的数据通信。
uWSGI是实现了uwsgi和WSGI两种协议的Web服务器。 nginx 是一个开源的高性能的HTTP服务器和反向代理: 1.作为web服务器,它处理静态文件和索引文件效果非常高
2.它的设计非常注重效率,最大支持5万个并发连接,但只占用很少的内存空间
3.稳定性高,配置简洁。
4.强大的反向代理和负载均衡功能,平衡集群中各个服务器的负载压力应用
155.Python中三大框架各自的应用场景?
django:主要是用来搞快速开发的,他的亮点就是快速开发,节约成本,,如果要实现高并发的话,就要对django进行二次开发,比如把整个笨重的框架给拆掉自己写socket实现http的通信,底层用纯c,c++写提升效率,ORM框架给干掉,自己编写封装与数据库交互的框架,ORM虽然面向对象来操作数据库,但是它的效率很低,使用外键来联系表与表之间的查询; flask: 轻量级,主要是用来写接口的一个框架,实现前后端分离,提考开发效率,Flask本身相当于一个内核,其他几乎所有的功能都要用到扩展(邮件扩展Flask-Mail,用户认证Flask-Login),都需要用第三方的扩展来实现。比如可以用Flask-extension加入ORM、文件上传、身份验证等。Flask没有默认使用的数据库,你可以选择MySQL,也可以用NoSQL。
其WSGI工具箱用Werkzeug(路由模块),模板引擎则使用Jinja2,这两个也是Flask框架的核心。
Tornado: Tornado是一种Web服务器软件的开源版本。Tornado和现在的主流Web服务器框架(包括大多数Python的框架)有着明显的区别:它是非阻塞式服务器,而且速度相当快。得利于其非阻塞的方式和对epoll的运用,Tornado每秒可以处理数以千计的连接因此Tornado是实时Web服务的一个理想框架
156.Django中哪里用到了线程?哪里用到了协程?哪里用到了进程?
1.Django中耗时的任务用一个进程或者线程来执行,比如发邮件,使用celery. 2.部署django项目是时候,配置文件中设置了进程和协程的相关配置。
157.有用过Django REST framework吗?
Django REST framework是一个强大而灵活的Web API工具。使用RESTframework的理由有:
Web browsable API对开发者有极大的好处 包括OAuth1a和OAuth2的认证策略 支持ORM和非ORM数据资源的序列化
全程自定义开发–如果不想使用更加强大的功能,可仅仅使用常规的function-based views额外的文档和强大的社区支持
158.对cookies与session的了解?他们能单独用吗?
Session采用的是在服务器端保持状态的方案,而Cookie采用的是在客户端保持状态的方案。但是禁用Cookie就不能得到Session。因为Session是用Session ID来确定当前对话所对应的服务器Session,而Session ID是通过Cookie来传递的,禁用Cookie相当于SessionID,也就得不到Session。
爬虫
159.试列出至少三种目前流行的大型数据库 160.列举您使用过的Python网络爬虫所用到的网络数据包?
requests, urllib,urllib2, httplib2
161.爬取数据后使用哪个数据库存储数据的,为什么? 162.你用过的爬虫框架或者模块有哪些?优缺点?
Python自带:urllib,urllib2 第三方:requests 框架: Scrapy
urllib 和urllib2模块都做与请求URL相关的操作,但他们提供不同的功能。 urllib2: urllib2.urlopen可以接受一个Request对象或者url,(在接受Request对象时,并以此可以来设置一个URL的headers),urllib.urlopen只接收一个url。 urllib 有urlencode,urllib2没有,因此总是urllib, urllib2常会一起使用的原因 scrapy是封装起来的框架,他包含了下载器,解析器,日志及异常处理,基于多线程,twisted的方式处理,对于固定单个网站的爬取开发,有优势,但是对于多网站爬取100个网站,并发及分布式处理不够灵活,不便调整与扩展 requests是一个HTTP库,它只是用来请求,它是一个强大的库,下载,解析全部自己处理,灵活性高
Scrapy优点:异步,xpath,强大的统计和log系统,支持不同url。shell方便独立调试。写middleware方便过滤。通过管道存入数据库 163.写爬虫是用多进程好?还是多线程好? 164.常见的反爬虫和应对方法?
165.解析网页的解析器使用最多的是哪几个? 166.需要登录的网页,如何解决同时限制ip,cookie,session 167.验证码的解决?
168.使用最多的数据库,对他们的理解? 169.编写过哪些爬虫中间件? 170.“极验”滑动验证码如何破解?
171.爬虫多久爬一次,爬下来的数据是怎么存储? 172.cookie过期的处理问题?
173.动态加载又对及时性要求很高怎么处理? 174.HTTPS有什么优点和缺点?
175.HTTPS是如何实现安全传输数据的? 176.TTL,MSL,RTT各是什么?
177.谈一谈你对Selenium和PhantomJS了解
178.平常怎么使用代理的 ?
179.存放在数据库(redis、mysql等)。 180.怎么监控爬虫的状态?
181.描述下scrapy框架运行的机制? 182.谈谈你对Scrapy的理解?
183.怎么样让 scrapy 框架发送一个 post 请求(具体写出来)
184.怎么监控爬虫的状态 ? 185.怎么判断网站是否更新?
186.图片、视频爬取怎么绕过防盗连接
187.你爬出来的数据量大概有多大?大概多长时间爬一次?
188.用什么数据库存爬下来的数据?部署是你做的吗?怎么部署? 189.增量爬取
190.爬取下来的数据如何去重,说一下scrapy的具体的算法依据。
191.Scrapy的优缺点?
192.怎么设置爬取深度?
193.scrapy和scrapy-redis有什么区别?为什么选择redis数据库?
194.分布式爬虫主要解决什么问题?
195.什么是分布式存储?
196.你所知道的分布式爬虫方案有哪些?
197.scrapy-redis,有做过其他的分布式爬虫吗?
做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。
别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。
我先来介绍一下这些东西怎么用,文末抱走。
* * *
**(1)Python所有方向的学习路线(新版)**
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

**(2)Python学习视频**
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

**(3)100多个练手项目**
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

**(4)200多本电子书**
这些年我也收藏了很多电子书,大概200多本,有时候带实体书不方便的话,我就会去打开电子书看看,书籍可不一定比视频教程差,尤其是权威的技术书籍。
基本上主流的和经典的都有,这里我就不放图了,版权问题,个人看看是没有问题的。
**(5)Python知识点汇总**
知识点汇总有点像学习路线,但与学习路线不同的点就在于,知识点汇总更为细致,里面包含了对具体知识点的简单说明,而我们的学习路线则更为抽象和简单,只是为了方便大家只是某个领域你应该学习哪些技术栈。

**(6)其他资料**
还有其他的一些东西,比如说我自己出的Python入门图文类教程,没有电脑的时候用手机也可以学习知识,学会了理论之后再去敲代码实践验证,还有Python中文版的库资料、MySQL和HTML标签大全等等,这些都是可以送给粉丝们的东西。

**这些都不是什么非常值钱的东西,但对于没有资源或者资源不是很好的学习者来说确实很不错,你要是用得到的话都可以直接抱走,关注过我的人都知道,这些都是可以拿到的。**
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化学习资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618317507)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**

















,2024年最新程序员去大公司面试&spm=1001.2101.3001.5002&articleId=138455173&d=1&t=3&u=c5e9eb15c2494806b489fe38a641839d)
 7783
7783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









