




影刀RPA操作数据库进阶:事务处理与批量写入优化
作者:林焱
基础的数据库增删改查谁都会写,但真正在企业级场景中,数据库操作远不止"写一条SQL执行一下"这么简单。采集了10万条数据要批量写入、多个表之间要保证数据一致性、写入失败要能回滚……这些都是进阶必须掌握的。这篇文章专门讲事务处理和批量写入优化,让你的数据库操作从"能用"变成"好用"。
一、事务处理:保证数据一致性
1.1 为什么需要事务

考虑这个场景:采集一条订单数据,要同时写入订单表和订单明细表。如果订单表写入成功但明细表写入失败,就会出现"有订单但没有商品"的脏数据。
# 错误做法:没有事务,两步操作中间可能失败
cursor.execute("INSERT INTO orders (order_id, customer) VALUES ('ORD001', '张三')")
# 如果这里出错了,orders表有数据但order_items表没有
cursor.execute("INSERT INTO order_items (order_id, product, qty) VALUES ('ORD001', '手机', 1)")
conn.commit() # 只提交了一半的数据
1.2 事务的ACID原则
| 原则 | 含义 | 在影刀RPA中的体现 |
|---|---|---|
| 原子性 | 全部成功或全部失败 | 采集数据要么全写入,要么全不写 |
| 一致性 | 数据从一个正确状态到另一个正确状态 | 订单和明细数量必须匹配 |
| 隔离性 | 并发操作互不影响 | 多个机器人同时写入不冲突 |
| 持久性 | 提交后数据不会丢失 | 数据库崩溃后能恢复 |
1.3 影刀RPA中的事务实现
import sqlite3
def 事务写入示例():
conn = sqlite3.connect("D:/data/订单数据库.db")
cursor = conn.cursor()
try:
# 开启事务(SQLite默认自动开启)
# 1. 写入订单主表
cursor.execute("""
INSERT INTO orders (order_id, customer_name, total_amount, order_date)
VALUES (?, ?, ?, ?)
""", ("ORD001", "张三", 5999.00, "2024-03-15"))
# 2. 写入订单明细表
cursor.execute("""
INSERT INTO order_items (order_id, product_name, quantity, price)
VALUES (?, ?, ?, ?)
""", ("ORD001", "iPhone 15", 1, 5999.00))
# 3. 更新库存
cursor.execute("""
UPDATE inventory SET stock = stock - ? WHERE product_name = ?
""", (1, "iPhone 15"))
# 全部成功,提交事务
conn.commit()
print("订单写入成功")
except Exception as e:
# 任何一步失败,回滚全部操作
conn.rollback()
print(f"订单写入失败,已回滚:{str(e)}")
finally:
conn.close()
1.4 事务嵌套与保存点
有时候一个大事务中的某一步失败了,不想全部回滚,只想回滚到中间某个点:
def 保存点示例():
conn = sqlite3.connect("D:/data/订单数据库.db")
cursor = conn.cursor()
try:
cursor.execute("INSERT INTO orders VALUES ('ORD001', '张三', 5999)")
# 创建保存点
cursor.execute("SAVEPOINT sp1")
try:
cursor.execute("INSERT INTO order_items VALUES ('ORD001', '手机', 1, 5999)")
except Exception as e:
# 明细写入失败,回滚到保存点(订单保留,明细回滚)
cursor.execute("ROLLBACK TO SAVEPOINT sp1")
[video(video-wTdIEqN9-1782023937761)(type-csdn)(url-https://live.csdn.net/v/embed/526818)(image-https://v-blog.csdnimg.cn/asset/582d14c3bd0451c5399cd990b56e2a0d/cover/Cover0.jpg)(title-拼多多店群自动化报活动上架!)]
print(f"明细写入失败,已回滚到保存点:{str(e)}")
# 释放保存点
cursor.execute("RELEASE SAVEPOINT sp1")
conn.commit()
except Exception as e:
conn.rollback()
print(f"事务失败:{str(e)}")
finally:
conn.close()
二、批量写入优化
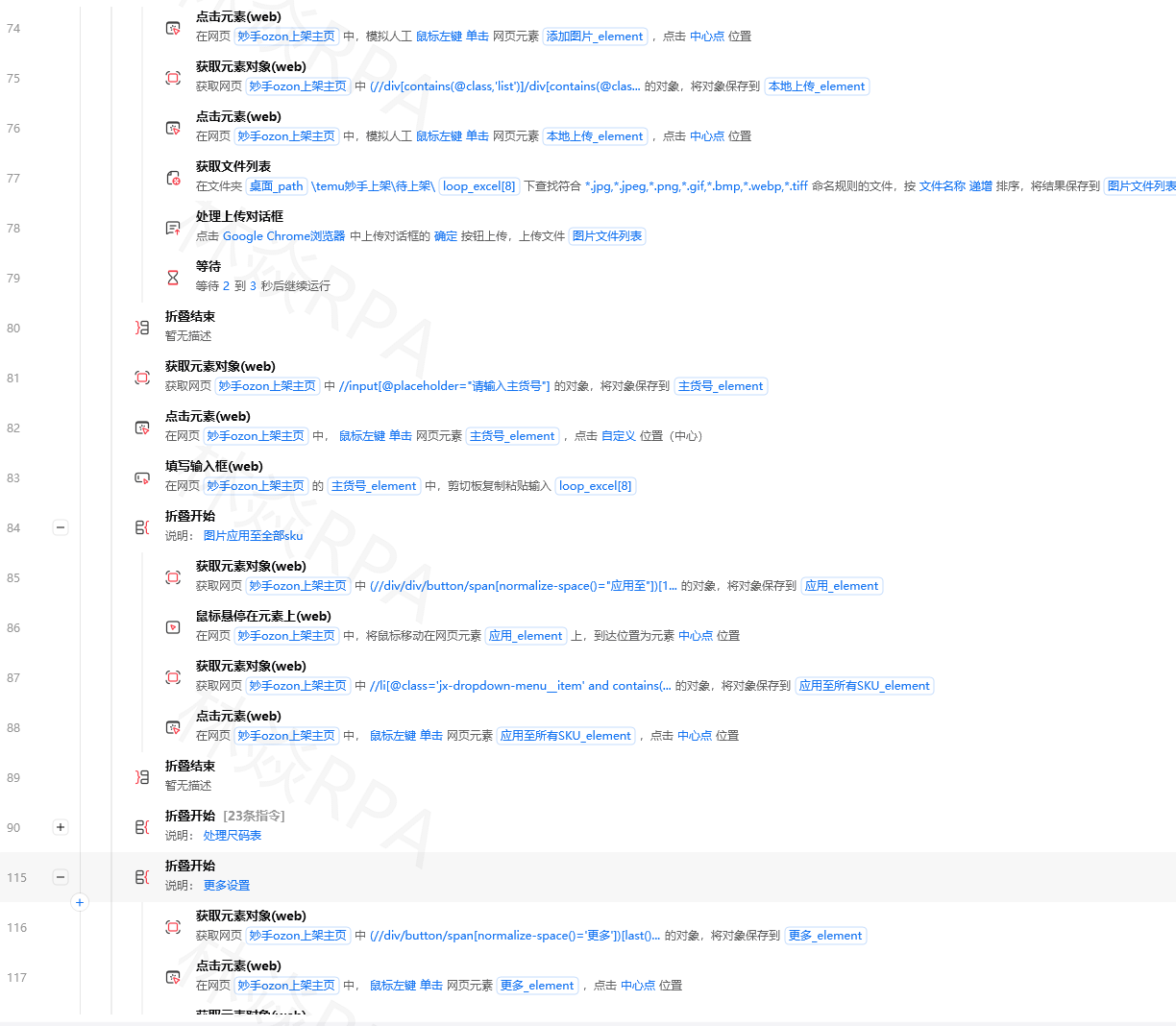
2.1 逐条写入 vs 批量写入
import sqlite3
import time
# 准备1万条测试数据
test_data = [(f"商品{i}", round(100 + i * 0.5, 2), i % 100) for i in range(10000)]
# 方式1:逐条写入(慢!)
def 逐条写入(data):
conn = sqlite3.connect("D:/data/test.db")
cursor = conn.cursor()
cursor.execute("CREATE TABLE IF NOT EXISTS products (name TEXT, price REAL, stock INTEGER)")
start = time.time()
for item in data:
cursor.execute("INSERT INTO products VALUES (?, ?, ?)", item)
conn.commit()
elapsed = time.time() - start
conn.close()
print(f"逐条写入{len(data)}条,耗时:{elapsed:.2f}秒")
# 1万条约8-12秒
# 方式2:executemany批量写入(快!)
def 批量写入(data):
conn = sqlite3.connect("D:/data/test.db")
cursor = conn.cursor()
cursor.execute("CREATE TABLE IF NOT EXISTS products (name TEXT, price REAL, stock INTEGER)")
start = time.time()
cursor.executemany("INSERT INTO products VALUES (?, ?, ?)", data)
conn.commit()
elapsed = time.time() - start
conn.close()
print(f"批量写入{len(data)}条,耗时:{elapsed:.2f}秒")
# 1万条约0.1-0.3秒,快30-50倍!
2.2 分批提交策略
数据量特别大时(10万+),一次性提交可能导致内存溢出。应该分批提交:
def 分批批量写入(data, batch_size=5000):
"""分批写入,每batch_size条提交一次"""
conn = sqlite3.connect("D:/data/test.db")
cursor = conn.cursor()
cursor.execute("CREATE TABLE IF NOT EXISTS products (name TEXT, price REAL, stock INTEGER)")
total = len(data)
start = time.time()
for i in range(0, total, batch_size):
batch = data[i:i + batch_size]
cursor.executemany("INSERT INTO products VALUES (?, ?, ?)", batch)
conn.commit()
progress = min(i + batch_size, total)
print(f"已写入{progress}/{total}条")
elapsed = time.time() - start
conn.close()
print(f"分批写入完成,总耗时:{elapsed:.2f}秒")
# 10万条数据,每5000条提交一次
big_data = [(f"商品{i}", round(100 + i * 0.5, 2), i % 100) for i in range(100000)]
分批批量写入(big_data, batch_size=5000)
2.3 SQLite性能优化配置
def 获取优化连接(db_path):
"""创建优化配置的SQLite连接"""
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
# 1. WAL模式:读写不互相阻塞
cursor.execute("PRAGMA journal_mode=WAL")
# 2. 同步模式设为NORMAL:兼顾安全与性能
cursor.execute("PRAGMA synchronous=NORMAL")
# 3. 增大缓存:减少磁盘IO
cursor.execute("PRAGMA cache_size=-64000") # 64MB缓存
# 4. 临时文件放内存:加快排序和聚合
cursor.execute("PRAGMA temp_store=MEMORY")
return conn
2.4 MySQL批量写入
import pymysql
def mysql批量写入(data, batch_size=5000):
"""MySQL批量写入"""
conn = pymysql.connect(
host="localhost",
port=3306,
user="root",
password="your_password",
database="rpa_data",
charset="utf8mb4"
)
cursor = conn.cursor()
# 创建表
cursor.execute("""
CREATE TABLE IF NOT EXISTS products (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(200),
price DECIMAL(10, 2),
stock INT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
""")
total = len(data)
start = time.time()
# MySQL的executemany
for i in range(0, total, batch_size):
batch = data[i:i + batch_size]
cursor.executemany(
"INSERT INTO products (name, price, stock) VALUES (%s, %s, %s)",
batch
)
conn.commit()
print(f"已写入{min(i + batch_size, total)}/{total}条")
elapsed = time.time() - start
conn.close()
print(f"MySQL批量写入完成,总耗时:{elapsed:.2f}秒")
三、UPSERT:不存在则插入,存在则更新
这是采集场景最常用的操作——同一商品的数据要更新而不是重复插入:
3.1 SQLite的UPSERT
def sqlite_upsert(conn, data):
"""SQLite的INSERT OR REPLACE"""
cursor = conn.cursor()
# 方式1:INSERT OR REPLACE(整行替换)
cursor.executemany("""
INSERT OR REPLACE INTO products (name, price, stock, updated_at)
VALUES (?, ?, ?, datetime('now'))
""", data)
# 方式2:INSERT ... ON CONFLICT(更精细的控制,SQLite 3.24+)
cursor.executemany("""
INSERT INTO products (name, price, stock, updated_at)
VALUES (?, ?, ?, datetime('now'))
ON CONFLICT(name) DO UPDATE SET
price = excluded.price,
stock = excluded.stock,
updated_at = datetime('now')
""", data)
conn.commit()
3.2 MySQL的UPSERT
def mysql_upsert(cursor, data):
"""MySQL的INSERT ... ON DUPLICATE KEY UPDATE"""
cursor.executemany("""
INSERT INTO products (name, price, stock)
VALUES (%s, %s, %s)
ON DUPLICATE KEY UPDATE

price = VALUES(price),
stock = VALUES(stock),
updated_at = NOW()
""", data)
四、实战案例:电商数据采集存储系统
4.1 数据库设计
-- 商品主表
CREATE TABLE IF NOT EXISTS products (
id INTEGER PRIMARY KEY AUTOINCREMENT,
product_id TEXT UNIQUE NOT NULL, -- 商品唯一ID
name TEXT NOT NULL, -- 商品名称
category TEXT, -- 分类
url TEXT, -- 商品链接
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 价格历史表
CREATE TABLE IF NOT EXISTS price_history (
id INTEGER PRIMARY KEY AUTOINCREMENT,
product_id TEXT NOT NULL, -- 关联商品ID
price DECIMAL(10, 2), -- 价格
original_price DECIMAL(10, 2), -- 原价
discount TEXT, -- 折扣信息
recorded_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (product_id) REFERENCES products(product_id)
);
-- 创建索引加速查询
CREATE INDEX IF NOT EXISTS idx_product_id ON price_history(product_id);
CREATE INDEX IF NOT EXISTS idx_recorded_at ON price_history(recorded_at);
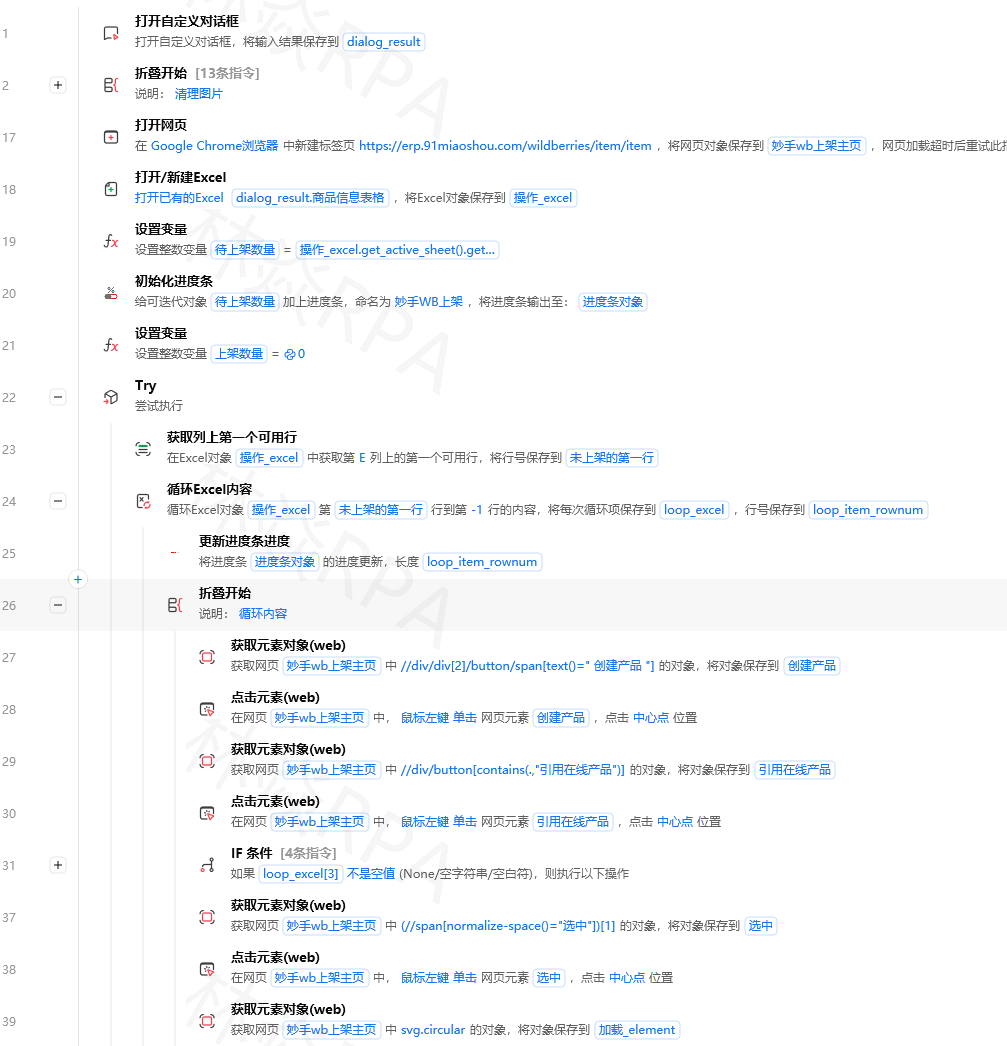
4.2 完整的数据写入流程
import sqlite3
import json
from datetime import datetime
class ProductDataStorage:
"""商品数据存储管理器"""
def __init__(self, db_path="D:/data/电商数据.db"):
self.db_path = db_path
self.conn = self._get_connection()
self._init_tables()
def _get_connection(self):
"""获取优化配置的连接"""
conn = sqlite3.connect(self.db_path)
conn.execute("PRAGMA journal_mode=WAL")
conn.execute("PRAGMA synchronous=NORMAL")
conn.execute("PRAGMA cache_size=-64000")
return conn
def _init_tables(self):
"""初始化表结构"""
self.conn.executescript("""
CREATE TABLE IF NOT EXISTS products (
id INTEGER PRIMARY KEY AUTOINCREMENT,
product_id TEXT UNIQUE NOT NULL,
name TEXT NOT NULL,
category TEXT,
url TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE IF NOT EXISTS price_history (
id INTEGER PRIMARY KEY AUTOINCREMENT,
product_id TEXT NOT NULL,
price DECIMAL(10, 2),
original_price DECIMAL(10, 2),
discount TEXT,
recorded_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (product_id) REFERENCES products(product_id)
);
CREATE INDEX IF NOT EXISTS idx_product_id ON price_history(product_id);
CREATE INDEX IF NOT EXISTS idx_recorded_at ON price_history(recorded_at);
""")
self.conn.commit()
def save_batch(self, products_data, batch_size=5000):
"""批量保存采集数据(事务保护)"""
cursor = self.conn.cursor()
total = len(products_data)
saved = 0
for i in range(0, total, batch_size):
batch = products_data[i:i + batch_size]
try:
# 开启事务
# 1. 更新商品主表(UPSERT)
product_rows = [
(p["product_id"], p["name"], p.get("category", ""), p.get("url", ""))
for p in batch
]
cursor.executemany("""
INSERT INTO products (product_id, name, category, url)
VALUES (?, ?, ?, ?)
ON CONFLICT(product_id) DO UPDATE SET
name = excluded.name,
category = excluded.category,
url = excluded.url,
updated_at = CURRENT_TIMESTAMP
""", product_rows)
# 2. 插入价格历史
price_rows = [
(p["product_id"], p.get("price", 0), p.get("original_price", 0), p.get("discount", ""))
for p in batch
]
cursor.executemany("""
INSERT INTO price_history (product_id, price, original_price, discount)
VALUES (?, ?, ?, ?)
""", price_rows)
# 提交本批次
self.conn.commit()
saved += len(batch)
print(f"已保存{saved}/{total}条")
except Exception as e:
self.conn.rollback()
print(f"第{i//batch_size + 1}批写入失败:{str(e)}")
# 将失败数据写入错误文件
self._save_error_batch(batch, str(e))
return saved
def _save_error_batch(self, batch, error_msg):
"""保存写入失败的数据"""
error_file = f"D:/logs/db_error_{datetime.now().strftime('%Y%m%d')}.json"
try:
with open(error_file, "a", encoding="utf-8") as f:
for item in batch:
item["_error"] = error_msg
f.write(json.dumps(item, ensure_ascii=False) + "\n")
except:
pass
def get_price_trend(self, product_id, days=30):
"""查询价格趋势"""
cursor = self.conn.cursor()
cursor.execute("""
SELECT date(recorded_at) as date,
AVG(price) as avg_price,
MIN(price) as min_price,
MAX(price) as max_price
FROM price_history
WHERE product_id = ? AND recorded_at >= date('now', ?)
GROUP BY date(recorded_at)
ORDER BY date
""", (product_id, f"-{days} days"))
return cursor.fetchall()
def close(self):
"""关闭连接"""
if self.conn:
self.conn.close()
# 使用示例
storage = ProductDataStorage()
# 模拟采集数据
采集数据 = [
{
"product_id": "JD10001",
"name": "iPhone 15 Pro 256GB",
"category": "手机",
"url": "https://item.jd.com/10001.html",
"price": 8999.00,
"original_price": 9999.00,
"discount": "9折"
},
# ... 更多数据
]
# 批量保存
storage.save_batch(采集数据)
# 查询价格趋势
trend = storage.get_price_trend("JD10001", days=30)
print(trend)
storage.close()

五、并发写入安全
5.1 多个机器人同时写入
import sqlite3
import time
import random
def 安全写入(db_path, data, max_retries=3):
"""带重试的安全写入,处理并发冲突"""
for attempt in range(max_retries):
try:
conn = sqlite3.connect(db_path, timeout=30) # 增加等待锁的超时
cursor = conn.cursor()
cursor.executemany(
"INSERT INTO products (name, price) VALUES (?, ?)",
data
)
conn.commit()
[video(video-Z7UPEEr0-1782023944549)(type-csdn)(url-https://live.csdn.net/v/embed/526817)(image-https://v-blog.csdnimg.cn/asset/1d3c3709da119dd8c13ab01e9b282520/cover/Cover0.jpg)(title-TEMU店群矩阵自动化运营核价报活动)]
conn.close()
return True
except sqlite3.OperationalError as e:
if "locked" in str(e) or "busy" in str(e):
# 数据库被锁定,等待后重试
wait = (2 ** attempt) + random.uniform(0, 1)
print(f"数据库繁忙,{wait:.1f}秒后重试(第{attempt+1}次)")
time.sleep(wait)
else:
raise
print(f"写入失败,已重试{max_retries}次")
return False
5.2 写入队列模式
import queue
import threading
class DatabaseWriter:
"""数据库写入队列,单线程写入避免锁冲突"""
def __init__(self, db_path):
self.db_path = db_path
self.queue = queue.Queue()
self.running = True
# 启动写入线程
self.writer_thread = threading.Thread(target=self._write_loop, daemon=True)
self.writer_thread.start()
def _write_loop(self):
"""写入线程:从队列取数据,批量写入"""
conn = sqlite3.connect(self.db_path)
conn.execute("PRAGMA journal_mode=WAL")
cursor = conn.cursor()
buffer = []
last_commit = time.time()
while self.running or not self.queue.empty():
try:
data = self.queue.get(timeout=1)
buffer.append(data)
# 每500条或每5秒提交一次
if len(buffer) >= 500 or (buffer and time.time() - last_commit > 5):
cursor.executemany(
"INSERT INTO products (name, price) VALUES (?, ?)",
buffer
)
conn.commit()
buffer = []
last_commit = time.time()
except queue.Empty:
# 超时,检查是否需要提交缓冲区
if buffer and time.time() - last_commit > 5:
cursor.executemany(
"INSERT INTO products (name, price) VALUES (?, ?)",
buffer
)
conn.commit()
buffer = []
last_commit = time.time()
# 提交剩余数据
if buffer:
cursor.executemany(
"INSERT INTO products (name, price) VALUES (?, ?)",
buffer
)
conn.commit()
conn.close()
def put(self, data):
"""将数据放入写入队列"""
self.queue.put(data)
def stop(self):
"""停止写入线程"""
self.running = False
self.writer_thread.join(timeout=30)

六、性能对比总结
| 写入方式 | 1万条耗时 | 10万条耗时 | 适用场景 |
|---|---|---|---|
| 逐条写入 | 8-12秒 | 80-120秒 | 不推荐 |
| executemany | 0.1-0.3秒 | 1-3秒 | 数据量适中 |
| 分批executemany | 0.1-0.5秒 | 1-5秒 | 大数据量 |
| 写入队列 | 近乎实时 | 近乎实时 | 持续采集 |
关键优化手段排序(按效果从大到小):
- executemany替代逐条执行 → 提速30-50倍
- WAL模式 → 读写不互阻
- 分批提交 → 避免大事务锁
- 增大缓存 → 减少磁盘IO
- 连接池/队列 → 并发安全
总结

数据库操作从基础到进阶的核心要点:
- 事务处理——多表操作必须用事务,保证数据一致性
- 批量写入——executemany比逐条执行快30-50倍
- UPSERT——采集场景必备,避免重复数据
- 分批提交——大数据量分批处理,避免锁表
- 并发安全——重试机制+写入队列,多机器人协同
数据库操作是影刀RPA数据处理的终点站,写不好数据库,前面采集的数据全白费。花时间把批量写入和事务处理搞清楚,比优化采集逻辑更值。
作者:林焱 | 觉得有用就收藏,后续分享更多影刀RPA实战技巧




















 420
420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









