Umi-OCR:彻底告别图片文字提取烦恼的免费离线解决方案
 项目地址: https://gitcode.com/GitHub_Trending/um/Umi-OCR
项目地址: https://gitcode.com/GitHub_Trending/um/Umi-OCR 还在为从图片中提取文字而烦恼吗?Umi-OCR作为一款完全免费、开源且支持离线运行的文字识别软件,能够轻松解决你的文档数字化需求。无需网络连接,保护隐私安全,支持截图识别、批量处理、二维码解析等多种场景,是办公、学习、编程等场景下的得力助手。
核心挑战:为什么传统OCR工具无法满足日常需求?
在日常工作和学习中,我们常常遇到这样的困扰:
- 隐私担忧:需要上传图片到云端服务器,敏感文档存在泄露风险
- 网络依赖:没有网络就无法使用,移动办公场景受限
- 费用问题:商业OCR软件价格昂贵,个人用户难以承担
- 功能单一:只能处理简单文字,无法应对复杂排版和代码识别
解决方案:本地化离线OCR的完美平衡
Umi-OCR采用完全离线的运行模式,所有识别过程都在本地计算机完成,从根本上解决了隐私和安全问题。同时,它内置了高效的OCR引擎和多种语言识别库,确保在没有网络连接的情况下也能提供准确的识别结果。
关键优势:离线运行不仅意味着隐私安全,更代表着随时随地可用的便利性。无论你是在飞机上、地铁里,还是在网络信号不佳的偏远地区,Umi-OCR都能稳定工作。
实际应用:从安装到精通的全方位指南
快速部署:三步开启文字识别之旅
第一步:获取软件包 从官方仓库下载最新版本的Umi-OCR压缩包,推荐使用7z格式确保文件完整性。解压后选择纯英文路径存放,避免中文路径可能导致的兼容性问题。
第二步:首次运行配置 首次启动时,建议先进行基础设置:
- 在全局设置中选择适合的界面语言
- 配置截图识别的快捷键组合
- 根据使用习惯设置默认保存格式
第三步:功能验证 尝试截取一小段文字进行识别,验证软件运行是否正常。
 全局设置界面支持语言切换、主题定制等个性化配置,让软件完全贴合你的使用习惯
全局设置界面支持语言切换、主题定制等个性化配置,让软件完全贴合你的使用习惯
实时截图OCR:捕捉屏幕文字的高效方案
截图识别是Umi-OCR最受欢迎的功能之一,特别适合快速提取网页、文档或图片中的文字内容。
操作流程:
- 使用预设快捷键激活截图功能
- 精准框选需要识别的文字区域
- 软件自动完成文字提取与格式优化
- 对识别结果进行必要编辑后导出使用
实用技巧:
- 对于代码片段,建议选择"代码模式"以获得更好的格式保留
- 对于复杂排版文档,可以先识别后再进行手动排版调整
- 识别结果可以直接复制到剪贴板,或保存为文本文件
 截图OCR操作界面,支持实时预览和文本编辑,识别结果可立即使用
截图OCR操作界面,支持实时预览和文本编辑,识别结果可立即使用
批量处理:应对海量图片文档的智能方案
当面对大量图片文档时,批量OCR功能能够显著提升处理效率。无论是扫描件整理、历史文档数字化,还是批量提取图片中的文字信息,Umi-OCR都能轻松应对。
工作流程优化:
- 智能排序:软件会自动按文件名或修改时间排序,确保处理顺序合理
- 进度监控:实时显示处理进度和剩余时间,让你随时掌握任务状态
- 质量评估:提供置信度评分,帮助判断识别结果的可靠性
- 批量导出:支持多种格式导出,满足不同场景需求
应用场景示例:
- 学术研究:批量处理文献扫描件
- 办公文档:整理会议记录图片
- 个人资料:数字化家庭老照片中的文字信息
 批量OCR界面,支持多文件同时处理和进度跟踪,大幅提升工作效率
批量OCR界面,支持多文件同时处理和进度跟踪,大幅提升工作效率
进阶功能:解锁更多实用场景
多语言界面无缝切换
Umi-OCR支持界面语言的动态切换,满足国际化使用需求。无论是中文用户、英文用户还是日文用户,都能找到自己熟悉的操作界面。
切换步骤:
- 打开全局设置面板
- 选择语言选项下拉菜单
- 切换至目标语言
- 重启软件完成语言更新
 多语言界面支持,包括中文、日文、英文等多种语言,满足全球用户需求
多语言界面支持,包括中文、日文、英文等多种语言,满足全球用户需求
识别精度优化策略
提升OCR识别准确率需要从多个角度入手:
图像预处理技巧:
- 确保待识别图片清晰、对比度适中
- 对于模糊图片,可以先进行简单的图像增强处理
- 调整图片亮度和对比度,使文字更加清晰
区域选择优化:
- 精准框选文字区域,避免无关内容干扰
- 对于表格类内容,建议分区域识别
- 复杂排版文档可以分段识别后再合并
参数调整建议:
- 根据文字类型选择合适的识别模型
- 调整识别参数以适应不同字体和字号
- 对于特殊字体,可以尝试不同的识别模式
代码识别:程序员的得力助手
对于程序员和技术文档编写者来说,Umi-OCR的代码识别功能是一个巨大的福音。无论是从技术文档中提取代码片段,还是将纸质代码笔记数字化,都能保持原有的格式和结构。
代码识别优势:
- 保持代码缩进和格式
- 准确识别编程语言的特殊字符
- 支持多种编程语言的语法高亮
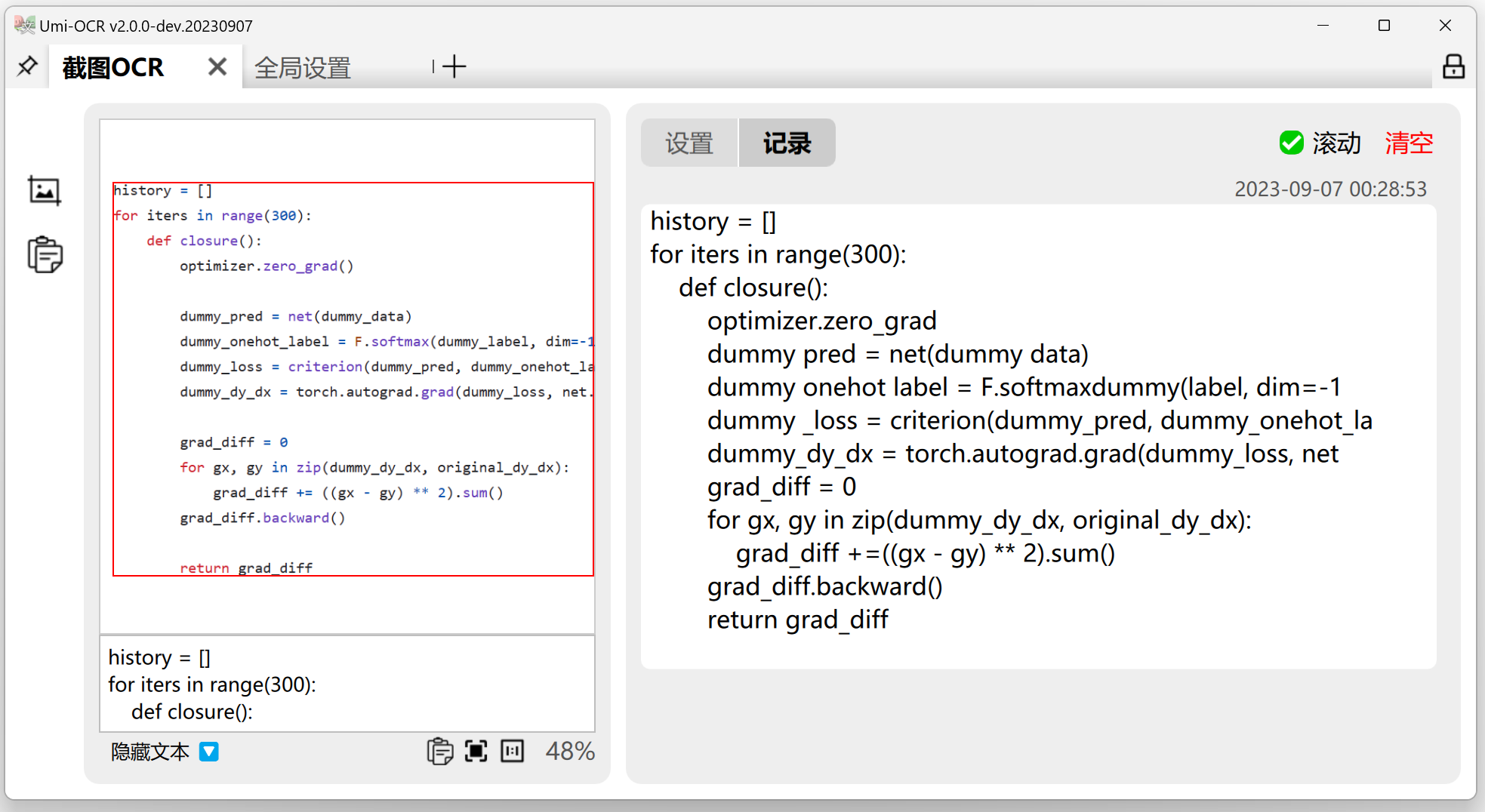 代码识别模块专注于代码截图的精准识别,确保代码格式与逻辑的准确性
代码识别模块专注于代码截图的精准识别,确保代码格式与逻辑的准确性
实用场景深度解析
办公文档数字化处理
场景一:扫描件文字提取 许多历史文档和纸质资料需要数字化保存。Umi-OCR能够:
- 批量处理扫描件,提取文字内容
- 保持原有排版格式
- 支持导出为可编辑文档格式
场景二:会议记录整理 会议中拍摄的白板照片或PPT截图,可以通过Umi-OCR快速转换为文字记录:
- 实时识别会议内容
- 支持多人发言的分段识别
- 导出为会议纪要格式
编程学习辅助应用
场景一:技术文档整理 从技术书籍、在线教程中截图代码片段:
- 快速提取代码示例
- 保持代码格式完整
- 方便后续学习和引用
场景二:错误信息收集 遇到程序错误时,截图错误信息:
- 快速提取错误日志
- 便于搜索和问题定位
- 保存为问题记录文档
常见问题与解决方案
软件启动相关问题
问题:启动闪退 解决方案:
- 检查系统运行库是否完整安装
- 确认软件路径不包含中文字符
- 尝试以管理员身份运行
问题:界面异常 解决方案:
- 调整显示比例设置
- 禁用硬件加速功能
- 更新显卡驱动程序
识别质量优化方案
问题:文字识别错误率高 解决方案:
- 提高原始图片质量
- 调整识别区域选择
- 选择合适的语言模型
- 调整识别参数设置
问题:格式混乱 解决方案:
- 使用排版解析功能
- 分段识别后手动调整
- 选择适合的识别模式
自动化与集成应用
命令行调用方法
通过命令行参数可以实现自动化调用,适合批量处理或集成到其他工作流中:
基础调用格式:
Umi-OCR.exe --folder "图片目录路径" --output "输出格式"
高级参数示例:
Umi-OCR.exe --input "image.jpg" --lang chinese --output txt --threads 4
脚本集成方案
可以将Umi-OCR集成到自动化脚本中,实现定时处理、监控文件夹等功能:
# 示例:监控文件夹并自动处理新图片
while true; do
find /path/to/watch -name "*.jpg" -newer /tmp/lastrun | while read file; do
Umi-OCR.exe --input "$file" --output /path/to/results
done
sleep 60
done
进阶思考:如何最大化利用Umi-OCR的价值?
工作流程优化建议
-
建立标准化处理流程
- 制定统一的文件命名规范
- 建立固定的输出目录结构
- 开发自动化处理脚本
-
质量控制系统
- 定期检查识别准确率
- 建立常见错误的纠正规则
- 收集反馈持续优化参数
-
团队协作方案
- 共享配置文件
- 统一处理标准
- 建立知识库和最佳实践
未来发展方向
随着人工智能技术的不断发展,OCR技术也在持续进化。Umi-OCR作为开源项目,具有以下发展潜力:
- 更多语言支持:扩展识别语言种类
- 智能排版分析:更精准的版面识别
- 手写体识别:支持手写文字的识别
- 云端同步:在保护隐私的前提下提供云备份功能
总结与行动号召
通过本文的介绍,相信你已经全面了解了Umi-OCR的强大功能和实用价值。这款完全免费、开源的离线OCR工具,不仅解决了传统OCR工具的诸多痛点,更为我们提供了一种全新的文字处理方式。
核心收获:
- 掌握了Umi-OCR的安装和基础配置方法
- 学会了截图识别和批量处理的高效技巧
- 了解了多语言支持和代码识别的特殊功能
- 掌握了常见问题的解决方法
立即行动: 现在就开始体验Umi-OCR带来的便捷文字识别服务吧!无论是日常办公、学习研究,还是编程开发,Umi-OCR都能成为你得力的助手。在实际使用中不断探索更多实用功能,让文档数字化变得更加简单高效。
记住,最好的工具是那些能够真正解决实际问题、提升工作效率的工具。Umi-OCR正是这样一款工具——它不仅免费开源,更在功能性和实用性上做到了极致。开始你的文字识别之旅,体验离线OCR带来的自由与便捷!
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







