LocalAI:3分钟部署本地AI引擎,无需GPU即可运行任何模型
 项目地址: https://gitcode.com/GitHub_Trending/lo/LocalAI
项目地址: https://gitcode.com/GitHub_Trending/lo/LocalAI 还在为云端AI服务的高昂费用和隐私担忧而烦恼吗?还在为复杂的AI模型部署和配置而头疼吗?LocalAI开源AI引擎为你带来革命性的解决方案——在本地设备上运行任何AI模型,从语言模型到视觉、语音、图像、视频处理,无需GPU即可轻松部署。LocalAI的核心功能源码位于core/,让你完全掌控AI技术栈。
🤖 为什么LocalAI是你的本地AI最佳选择?
想象一下:在自己的电脑上运行ChatGPT级别的对话模型,处理图像生成任务,进行语音识别和合成,而所有数据都安全地留在本地。这就是LocalAI带给你的自由!
传统AI部署的痛点:
- 🔒 隐私风险:数据上传到云端,隐私无法保障
- 💰 高昂成本:按使用量付费,长期使用成本惊人
- ⚙️ 技术门槛高:需要专业配置和GPU硬件
- 🌐 网络依赖:必须保持稳定网络连接
LocalAI的突破性优势:
- 🚀 一键部署:3分钟完成本地AI环境搭建
- 🔒 完全隐私:所有数据在本地处理,绝不外传
- 💰 零成本运行:一次性部署,永久免费使用
- 🖥️ 硬件友好:无需GPU,普通CPU即可运行
- 🌐 离线工作:完全脱离网络依赖
🏗️ LocalAI架构揭秘:统一API,多引擎支持
LocalAI采用创新的"一个API,多个引擎"架构设计,将复杂的AI技术栈封装在简洁的界面背后。

核心架构亮点:
- 统一API层:完全兼容OpenAI和Anthropic API标准,现有应用无需修改即可接入
- 智能路由系统:自动将请求分发到最适合的后端引擎
- 模块化设计:每个AI功能都有独立的后端引擎,按需加载
- 内存管理优化:智能调度算法确保资源高效利用
技术架构组件:
- 前端API服务器:提供标准的RESTful接口
- 智能路由器:负责请求分发和负载均衡
- 后端引擎池:包含llama.cpp、whisper.cpp、vLLM、MLX等专业引擎
- 模型管理器:自动下载和管理AI模型文件
🎯 四大核心功能,满足全方位AI需求
1. 智能对话:你的本地ChatGPT
LocalAI支持所有主流开源语言模型,让你拥有完全私有的AI助手。

支持的对话模型:
- Llama系列:从7B到70B参数的各种规模
- Gemma系列:Google的高效小型模型
- Qwen系列:阿里巴巴的多语言模型
- DeepSeek系列:专注于代码和推理的模型
对话功能特色:
- 📝 上下文记忆:支持长达32K tokens的对话历史
- 🔧 函数调用:模型可以调用外部工具和API
- 📊 流式输出:实时显示生成过程
- 🎭 角色扮演:自定义AI助手性格和风格
2. 图像生成:本地Stable Diffusion
无需云端服务,在本地生成高质量图像。
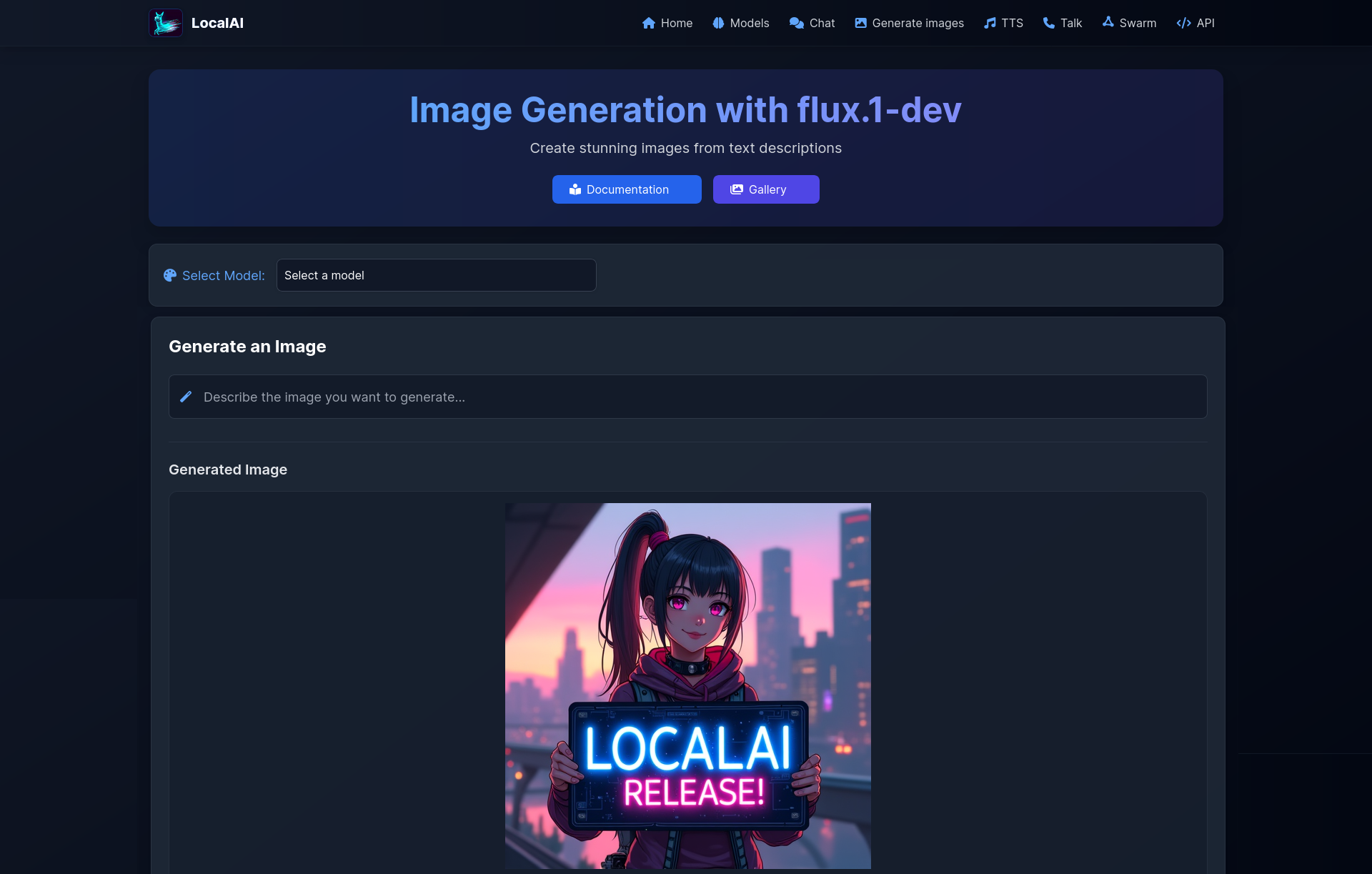
图像生成能力:
- 🎨 文本到图像:根据描述生成逼真图像
- 🔄 图像到图像:基于现有图像进行风格转换
- ✨ 图像增强:提升图像分辨率和质量
- 🎭 风格迁移:应用不同艺术风格
技术优势:
- ⚡ 快速生成:CPU上也能在数秒内完成
- 🎯 精准控制:支持多种采样方法和参数调节
- 📐 多尺寸支持:从512x512到1024x1024多种分辨率
- 🔒 完全隐私:创意想法只在本地处理
3. 语音处理:听与说的AI能力
完整的语音AI套件,支持语音识别和合成。

语音识别功能:
- 🎤 实时转录:将语音实时转换为文字
- 🌍 多语言支持:支持100+种语言识别
- 📝 标点恢复:自动添加标点符号
- 👥 说话人分离:识别不同说话人的语音
语音合成功能:
- 🗣️ 自然语音:生成接近真人发音的语音
- 🎭 情感控制:调节语音的情感和语调
- 🌐 多语言支持:支持多种语言的语音合成
- ⚡ 实时合成:低延迟的语音生成
4. 语音交互:真正的对话体验
结合语音识别和合成,实现自然的语音对话。
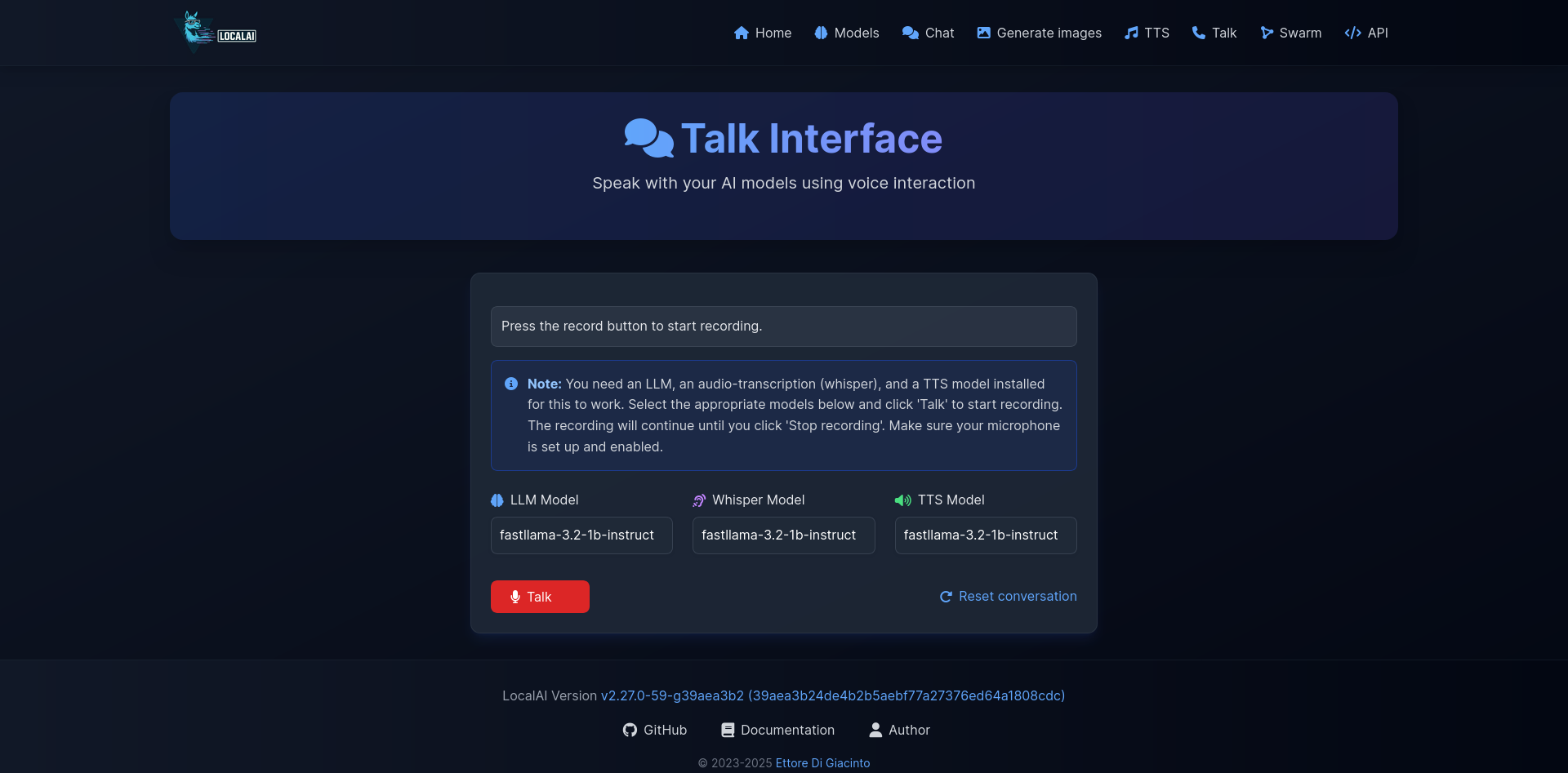
语音对话特色:
- 🎙️ 实时对话:像真人一样自然交流
- 🔄 上下文感知:记住对话历史
- 🎵 情绪表达:语音中带有情感变化
- ⏱️ 低延迟:快速响应,体验流畅
📊 智能模型管理:873个模型一键获取
LocalAI内置强大的模型库,支持873个预配置模型。

模型分类管理:
- 文本生成:对话、代码生成、写作助手
- 图像生成:艺术创作、设计辅助
- 语音处理:识别、合成、翻译
- 多模态:图文理解、视觉问答
- 嵌入模型:语义搜索、文档分析
- 重排序器:搜索结果优化
模型筛选功能:
- 🔍 智能搜索:按名称、标签、描述搜索
- 🏷️ 标签过滤:按功能标签快速筛选
- 📊 类型分类:按AI任务类型分类展示
- ⭐ 热门推荐:显示最受欢迎的模型
🚀 三步快速入门:从零到AI专家
LocalAI的安装过程简单到令人难以置信。

第一步:安装LocalAI(1分钟)
# Docker方式(推荐)
docker run -p 8080:8080 localai/localai:latest
# 二进制方式
curl -LO https://github.com/mudler/LocalAI/releases/latest/download/local-ai
chmod +x local-ai
./local-ai
第二步:选择模型(1分钟)
打开浏览器访问 http://localhost:8080,在模型库中选择你需要的AI模型。LocalAI会自动下载和配置所需文件。
第三步:开始使用(1分钟)
- Web界面:直接在浏览器中与AI交互
- API调用:使用兼容OpenAI的API接口
- 命令行工具:通过CLI快速测试功能
🏢 企业级部署:分布式架构支持
对于需要高可用性和扩展性的企业场景,LocalAI提供完整的分布式解决方案。

分布式架构优势:
- 🔄 负载均衡:智能分配请求到多个工作节点
- 📈 水平扩展:轻松添加更多计算节点
- 🔒 高可用性:单点故障不影响整体服务
- 💾 集中存储:模型文件统一管理
部署方案对比:
| 部署方式 | 适用场景 | 优势 | 配置复杂度 |
|---|---|---|---|
| 单机部署 | 个人使用、开发测试 | 简单快速、资源占用少 | ⭐☆☆☆☆ |
| 容器化部署 | 团队协作、CI/CD集成 | 环境隔离、易于复制 | ⭐⭐☆☆☆ |
| 分布式部署 | 生产环境、高并发场景 | 高可用、弹性扩展 | ⭐⭐⭐⭐☆ |
| 云原生部署 | 大规模企业应用 | 自动扩缩容、监控完善 | ⭐⭐⭐⭐⭐ |
⚡ 智能调度算法:最大化硬件利用率
LocalAI的智能路由器采用先进的调度算法,确保资源高效利用。
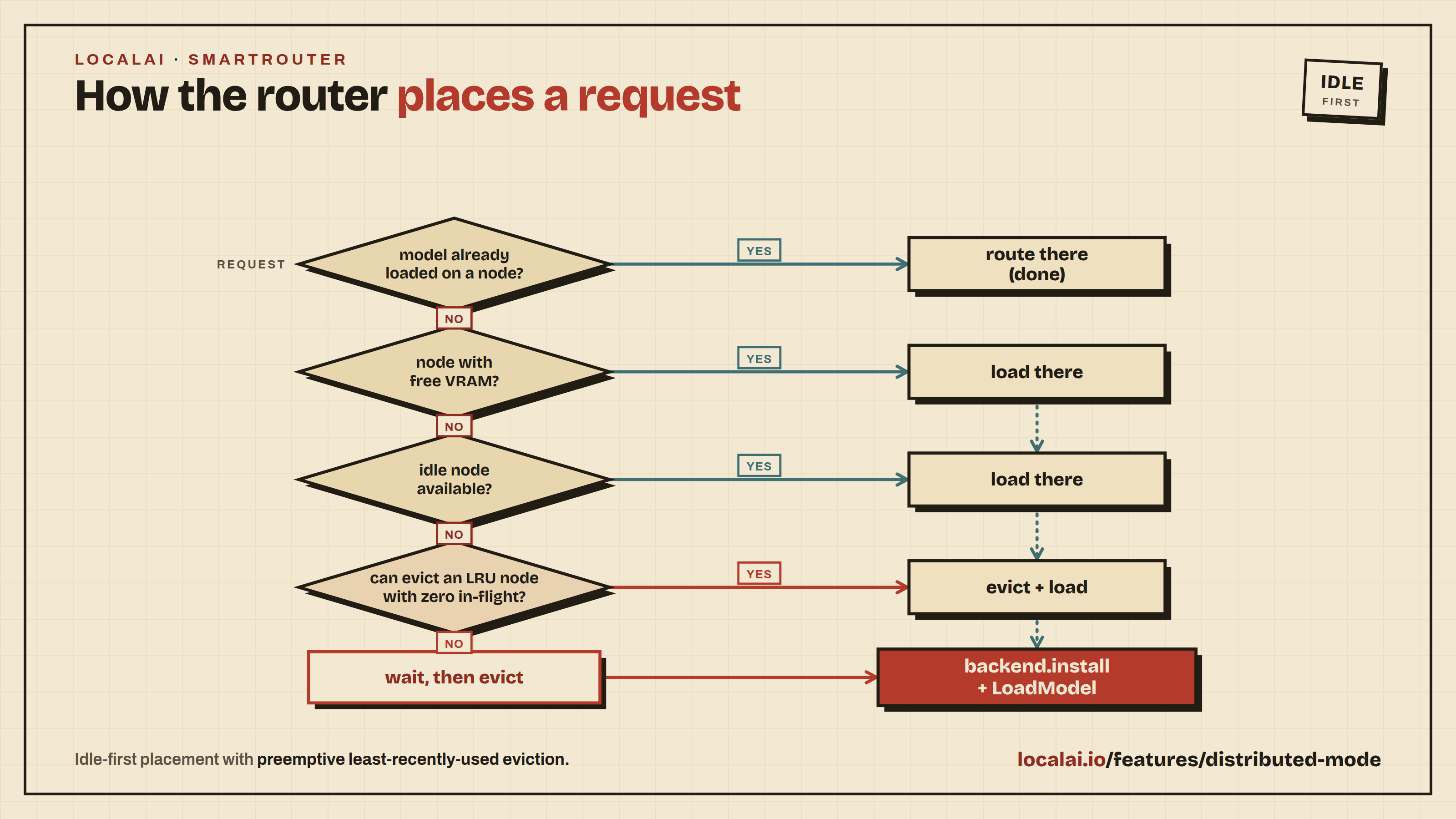
调度策略:
- 空闲优先:优先使用空闲节点的资源
- 内存感知:根据VRAM使用情况智能分配
- LRU淘汰:淘汰最近最少使用的模型
- 预加载优化:预测性加载常用模型
性能优化技巧:
- 🎯 模型量化:使用4-bit或8-bit量化减少内存占用
- ⚡ 批处理优化:合并多个请求提高吞吐量
- 🔄 缓存策略:智能缓存常用模型和结果
- 📊 监控调优:实时监控资源使用情况
🔧 高级配置指南:发挥硬件最大潜力
CPU优化配置
# 配置文件位置:~/.localai/config.yaml
environment_vars:
# 线程数设置(根据CPU核心数调整)
OMP_NUM_THREADS: "8"
# 内存分配优化
GGML_NUM_THREADS: "8"
# 批处理大小
BATCH_SIZE: "32"
内存管理策略
- 分层缓存:热数据放内存,冷数据放磁盘
- 智能预加载:根据使用模式预测性加载
- 动态卸载:长时间不用的模型自动卸载
存储优化建议
- 💾 SSD优先:模型加载速度提升3-5倍
- 🔄 分层存储:常用模型放高速存储
- 📁 目录优化:按模型类型分类存储
🛡️ 安全与隐私:你的数据你做主
数据安全特性
- 🔒 端到端加密:所有数据处理在本地完成
- 🚫 无数据上传:绝不向云端发送任何数据
- 📝 完整审计:所有操作都有详细日志
- 🔐 访问控制:支持API密钥和IP白名单
隐私保护措施
- 🏠 本地存储:所有模型和数据存储在本地
- 🧹 自动清理:临时文件自动删除
- 🔄 内存隔离:不同用户请求内存隔离
- 📊 使用统计:仅记录匿名使用统计
🔌 集成生态:与现有工具无缝对接
开发工具集成
- VS Code扩展:直接在编辑器中调用LocalAI
- Jupyter Notebook:在数据科学工作流中使用
- LangChain支持:作为本地LLM提供者
- AutoGPT兼容:支持AutoGPT等自动化工具
API兼容性
# 使用OpenAI客户端库(无需修改代码)
import openai
# 只需修改API基础URL
client = openai.OpenAI(
base_url="http://localhost:8080/v1",
api_key="not-needed"
)
# 像使用OpenAI一样使用LocalAI
response = client.chat.completions.create(
model="llama3.2",
messages=[{"role": "user", "content": "你好!"}]
)
企业系统集成
- RESTful API:标准的HTTP接口
- gRPC支持:高性能的RPC通信
- WebSocket:实时双向通信
- GraphQL:灵活的数据查询
📈 性能基准测试:真实数据对比
硬件要求对比
| 模型类型 | 最低配置 | 推荐配置 | 最佳体验 |
|---|---|---|---|
| 7B参数模型 | 4GB RAM, 4核CPU | 8GB RAM, 8核CPU | 16GB RAM, 12核CPU |
| 13B参数模型 | 8GB RAM, 8核CPU | 16GB RAM, 12核CPU | 32GB RAM, 16核CPU |
| 图像生成 | 8GB RAM, 6核CPU | 16GB RAM, 12核CPU | 32GB RAM, GPU加速 |
| 语音处理 | 4GB RAM, 4核CPU | 8GB RAM, 8核CPU | 16GB RAM, 12核CPU |
响应时间测试
- 💬 文本生成:7B模型约50-100ms/token
- 🖼️ 图像生成:512x512图像约5-10秒
- 🎤 语音识别:实时转录,延迟<200ms
- 🗣️ 语音合成:1分钟语音约2-3秒
🚨 常见问题解答
Q1: LocalAI真的不需要GPU吗?
A: 是的!LocalAI经过深度优化,可以在纯CPU环境下运行大多数AI模型。当然,如果有GPU,性能会更好。
Q2: 模型文件有多大?需要多少存储空间?
A: 模型大小从几百MB到几十GB不等。7B参数的量化模型约4GB,13B参数约8GB。建议准备至少20GB可用空间。
Q3: 如何更新模型和软件?
A: LocalAI支持自动更新。在Web界面点击更新按钮,或使用命令行工具:local-ai update
Q4: 支持中文模型吗?
A: 完全支持!LocalAI模型库包含多个优秀的中文模型,如Qwen、ChatGLM等。
Q5: 可以商用吗?有许可证限制吗?
A: LocalAI采用MIT开源协议,允许商业使用。但请注意,部分模型可能有自己的许可证。
🔮 未来展望:LocalAI的发展路线图
短期计划(6个月内)
- 🎯 更多模型支持:扩展到1000+预配置模型
- ⚡ 性能优化:推理速度提升30%
- 🔌 插件系统:支持第三方功能扩展
- 🌐 社区模型:用户贡献模型共享平台
中期目标(1年内)
- 🤖 多模态融合:文本、图像、语音深度融合
- 🔄 联邦学习:分布式模型训练
- 📱 移动端支持:iOS/Android原生应用
- 🎮 游戏集成:游戏内AI助手
长期愿景
- 🌍 去中心化网络:全球AI计算资源共享
- 🧠 个性化AI:根据用户习惯自我优化
- 🔗 区块链集成:AI服务去中心化治理
- 🚀 太空计算:边缘AI在特殊环境的应用
🎉 立即开始你的本地AI之旅
LocalAI不仅仅是一个工具,更是AI民主化的重要一步。它将原本需要专业知识和昂贵硬件的AI技术,变得人人可用、处处可及。
今天就开始:
- 下载安装:选择适合你系统的版本
- 选择模型:从873个模型中挑选
- 开始创造:用AI赋能你的工作和生活
记住,真正的AI自由不是拥有最强大的硬件,而是拥有完全的控制权。LocalAI让你成为AI的主人,而不是被AI服务商控制的用户。
温馨提示:加入LocalAI社区,与全球开发者一起推动开源AI的发展。无论你是技术专家还是AI爱好者,这里都有你的位置。

你的数据,你的AI,你的选择。 这就是LocalAI的承诺——让AI技术真正为每个人服务,而不是为少数公司垄断。现在就开始,体验完全掌控的AI力量!
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







