3步掌握Kronos金融K线预测:从零部署到实战验证
 项目地址: https://gitcode.com/GitHub_Trending/kronos14/Kronos
项目地址: https://gitcode.com/GitHub_Trending/kronos14/Kronos Kronos作为首个开源金融K线基础模型,为技术爱好者和量化从业者提供了革命性的市场预测工具。本文将通过全新框架,指导你从环境搭建到实战应用,快速掌握这一金融时序预测模型的核心部署技巧。
问题导向:传统金融预测的挑战与Kronos的解决方案
金融时序预测面临三大核心挑战:高噪声数据难以捕捉有效信号、连续价格数据缺乏结构化表示、传统模型泛化能力有限。Kronos通过创新的两阶段架构完美解决了这些问题。

K线Token化技术:模型将连续的OHLCV(开盘价、最高价、最低价、收盘价、成交量)数据量化为分层离散tokens,通过专用Tokenizer Encoder进行特征提取,采用BSQ块级量化技术压缩数据维度。
自回归预测机制:基于Transformer的解码器架构支持512个时间步的上下文窗口,自动学习金融市场的时序规律,实现精准的多步预测。
环境配置:极简部署流程
系统要求检查
- Python 3.10+ 运行环境
- PyTorch 2.0+ 深度学习框架
- CUDA 11.7+ GPU加速支持(可选)
- 至少2GB可用显存(GPU版本)
项目获取与依赖安装
git clone https://gitcode.com/GitHub_Trending/kronos14/Kronos
cd Kronos
pip install -r requirements.txt
专家提示:对于消费级GPU用户,建议安装PyTorch的CUDA 11.8版本以获得最佳兼容性。
核心实战:三步完成首次金融预测
第一步:模型加载与初始化
Kronos提供了预训练模型库,支持从Hugging Face Hub一键加载:
from model import Kronos, KronosTokenizer, KronosPredictor
# 加载预训练tokenizer和模型
tokenizer = KronosTokenizer.from_pretrained("NeoQuasar/Kronos-Tokenizer-base")
model = Kronos.from_pretrained("NeoQuasar/Kronos-small")
# 创建预测器实例(自动选择最优设备)
predictor = KronosPredictor(model, tokenizer, device="auto", max_context=512)
最佳实践:对于内存受限的环境,可使用model = model.half()将模型转换为FP16半精度,显存占用减半。
第二步:数据准备与预处理
Kronos支持标准pandas DataFrame格式的金融数据:
import pandas as pd
# 加载示例数据
df = pd.read_csv("examples/data/XSHG_5min_600977.csv")
df['timestamps'] = pd.to_datetime(df['timestamps'])
# 定义预测参数
lookback = 400 # 历史数据长度
pred_len = 120 # 预测时间步数
# 准备输入数据
x_df = df.iloc[:lookback][['open', 'high', 'low', 'close', 'volume']]
x_timestamp = df.iloc[:lookback]['timestamps']
y_timestamp = df.iloc[lookback:lookback+pred_len]['timestamps']
第三步:执行预测并可视化
# 执行单次预测
pred_df = predictor.predict(
df=x_df,
x_timestamp=x_timestamp,
y_timestamp=y_timestamp,
pred_len=pred_len,
T=0.8, # 温度参数控制随机性
top_p=0.9, # 核采样概率
sample_count=3 # 生成3个样本取平均
)
# 可视化结果对比
from examples.prediction_example import plot_prediction
plot_prediction(df.iloc[:lookback+pred_len], pred_df)

性能优化:多资产批量预测技巧
对于需要同时预测多个资产序列的场景,Kronos提供了高效的批量预测接口:
# 准备多个资产数据
df_list = [df1, df2, df3]
x_timestamp_list = [x_ts1, x_ts2, x_ts3]
y_timestamp_list = [y_ts1, y_ts2, y_ts3]
# 执行批量预测
pred_df_list = predictor.predict_batch(
df_list=df_list,
x_timestamp_list=x_timestamp_list,
y_timestamp_list=y_timestamp_list,
pred_len=pred_len,
T=0.8,
top_p=0.9,
sample_count=1,
verbose=True
)
关键要求:所有序列必须具有相同的历史长度和预测长度,确保批量处理的效率最大化。
实战验证:回测系统搭建与策略评估
回测流程设计
Kronos提供了完整的回测验证流程,通过run_backtest_kronos.py脚本可快速评估模型在实际交易场景中的表现:
python examples/run_backtest_kronos.py --device cuda:0

回测结果解读
回测图表展示了模型策略的累积收益表现:
- 黑色虚线:基准指数(如CSI300)表现
- 彩色实线:基于Kronos预测的交易策略收益
- 超额收益:策略相对于基准的稳定超额回报
专家提示:回测中的简单top-K策略仅为演示目的,实际生产环境中需结合投资组合优化和风险因子中性化技术。
个性化模型微调:适应特定市场
数据准备与预处理
# 使用Qlib进行数据预处理
python finetune/qlib_data_preprocess.py
Tokenizer微调
# 调整tokenizer适应特定数据分布
torchrun --standalone --nproc_per_node=2 finetune/train_tokenizer.py
预测器微调
# 微调主预测模型
torchrun --standalone --nproc_per_node=2 finetune/train_predictor.py
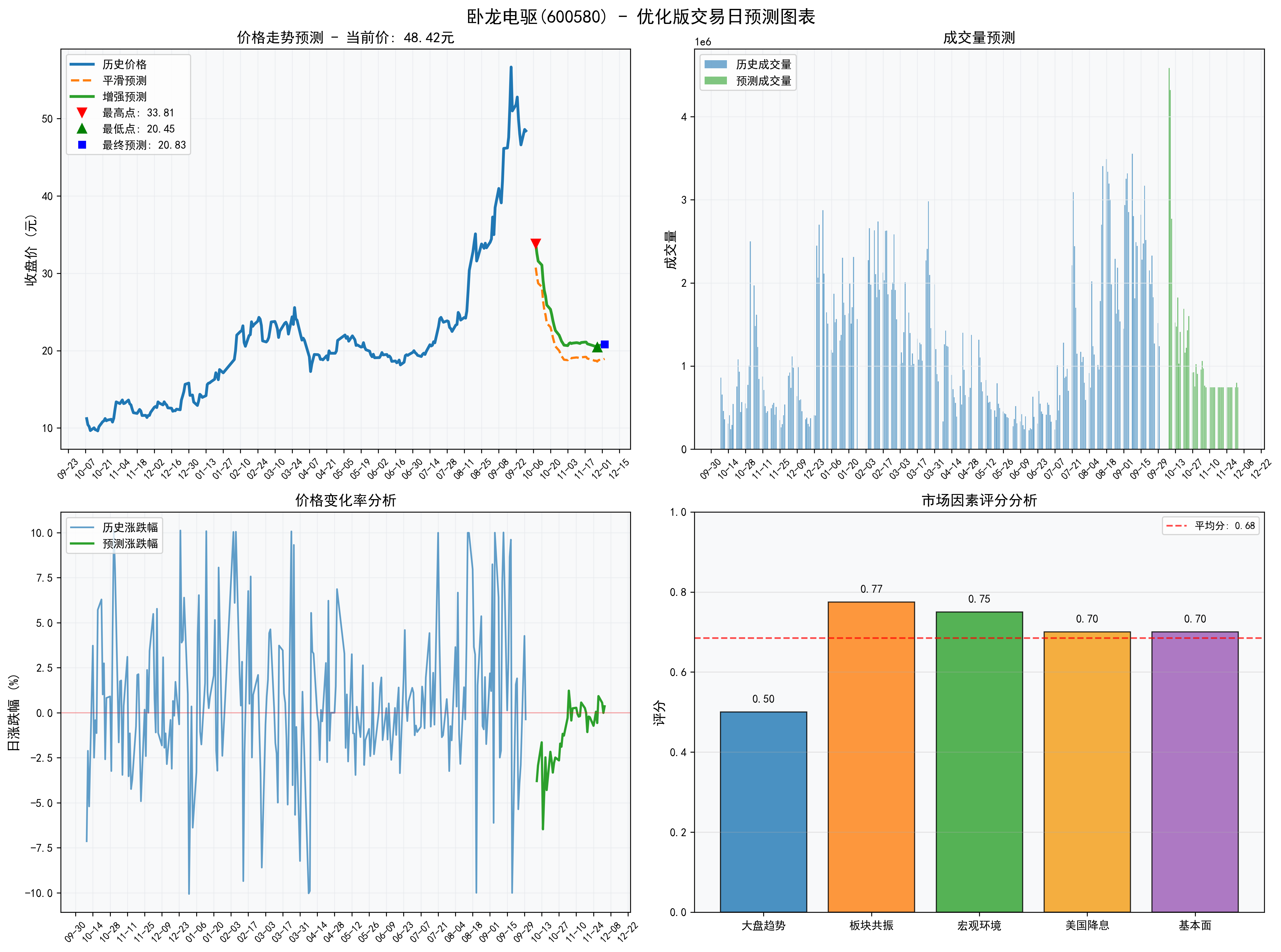
优化后的预测图展示了多维度分析能力:
- 左上:价格走势预测(蓝色历史,绿色增强预测)
- 右上:成交量预测
- 左下:价格变化率分析
- 右下:市场因素评分分析
Web界面部署:零代码可视化体验
Kronos提供了完整的Web界面,支持零代码操作:
cd webui
./start.sh
启动后访问http://localhost:7070即可使用可视化界面,核心功能包括:
- 多格式金融数据加载
- 预测参数实时调节
- 多维度结果展示
- CSV/JSON格式数据导出
进阶学习路径与资源
核心技术模块探索
- 模型架构深度理解:研究
model/kronos.py中的KronosTokenizer和Kronos类实现 - 数据处理流程:分析
examples/prediction_example.py中的数据预处理逻辑 - 微调工具链:探索
finetune/目录下的完整微调流程
性能优化策略
- 内存优化:使用FP16半精度推理减少显存占用
- 批量处理:利用GPU并行处理多个资产序列
- 上下文管理:合理设置max_context参数平衡精度与效率
生产环境部署建议
- 数据质量验证:确保输入数据的完整性和一致性
- 预测稳定性:通过多次采样取平均提高结果可靠性
- 监控系统:建立预测准确率和延迟的监控机制
Kronos为个人投资者和小型量化团队提供了强大的技术支撑,通过本指南的实践步骤,你已掌握了从基础部署到高级应用的完整技能栈。继续深入探索模型源码和微调工具,将能构建更符合特定需求的金融预测系统。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







