Docling多格式处理与AI适配全指南:从格式障碍到智能文档的无缝转换
 项目地址: https://gitcode.com/GitHub_Trending/do/docling
项目地址: https://gitcode.com/GitHub_Trending/do/docling 你是否曾遇到过这样的困境:重要的PDF研究论文无法被AI模型有效解析?精心制作的Excel数据报表难以转换为可分析的格式?扫描版合同文件中的关键信息需要手动提取?在生成式AI时代,文档格式的碎片化已成为数据利用的最大障碍。Docling作为一款专为AI应用设计的文档处理工具,通过创新的"格式无关"理念,让20+种文档格式轻松转换为AI友好型输出。本文将带你从零开始掌握这一强大工具,让任何文档都能成为AI的"优质食材"。
1 核心突破:重新定义文档处理的3大创新机制
1.1 格式无关架构:打破文档格式的"语言壁垒"
想象一下,如果每种文档格式都像一门独立的语言,那么传统处理工具就像是只会单一语言的翻译,而Docling则是掌握20+种语言的同声传译。其核心在于将任何输入格式统一转换为标准化的"Docling Document"中间表示,就像将不同语言的内容都翻译成一种通用语。
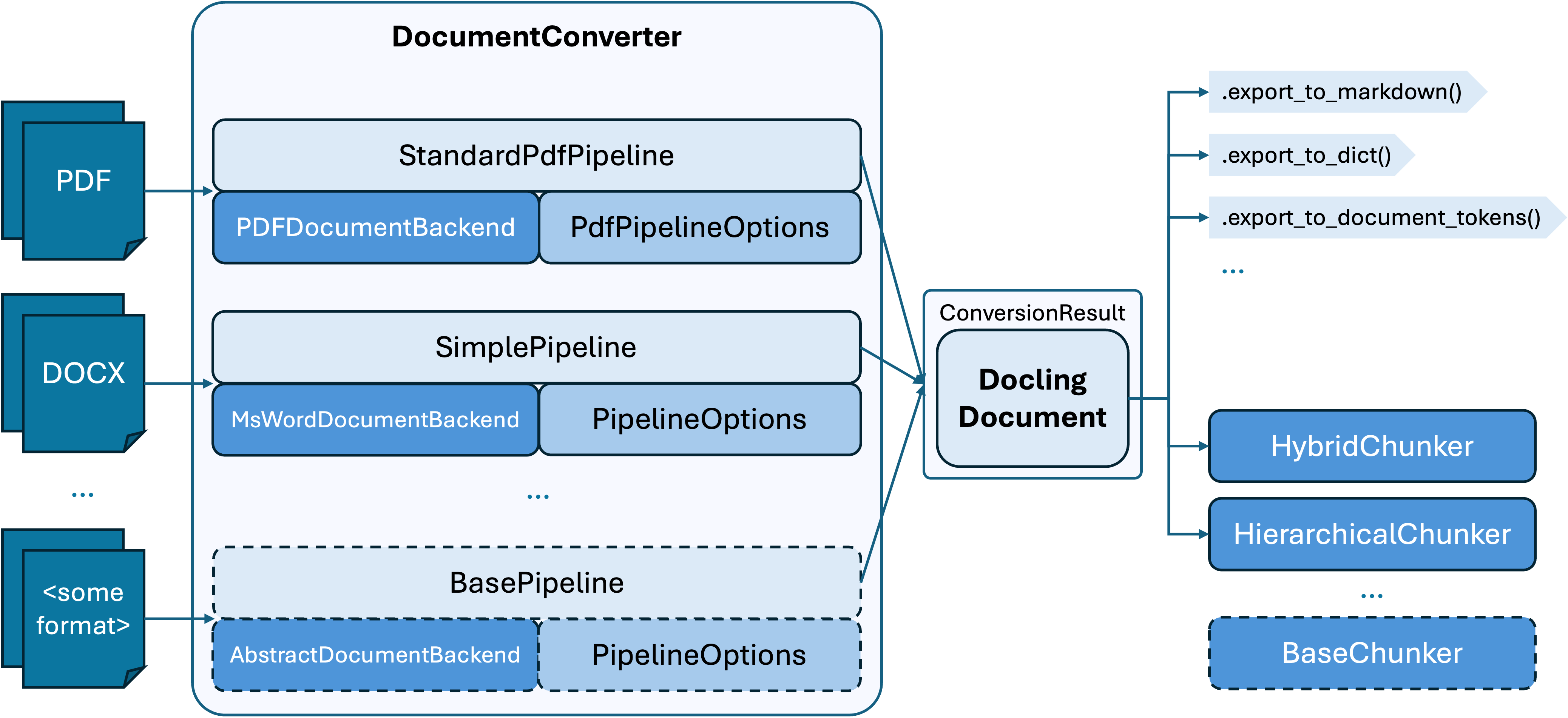
技术选型解析:
- 模块化后端设计:每种格式对应独立后端处理模块(如[backend/pdf_backend.py]处理PDF,[backend/msword_backend.py]处理DOCX),便于扩展新格式
- 分层处理管道:通过BasePipeline、SimplePipeline等不同复杂度的处理流程([pipeline/]),实现从简单到复杂文档的自适应处理
- 统一中间表示:Docling Document数据结构([datamodel/document.py])保存文档的所有语义和布局信息,为后续AI处理提供完整数据基础
1.2 智能解析引擎:让文档"开口说话"的5大能力
Docling不仅仅是格式转换器,更是文档理解专家。它能像人类阅读一样理解文档的层次结构、识别关键元素:
| 核心能力 | 技术实现 | 应用场景 |
|---|---|---|
| 布局分析 | [models/layout/] | 识别标题、段落、列表等结构 |
| 表格提取 | [models/table_structure/] | 从PDF/图片中恢复可编辑表格 |
| 公式识别 | [models/code_formula/] | 将LaTeX或图片公式转换为可解析格式 |
| 图像理解 | [models/picture_description/] | 为图片生成文本描述 |
| OCR处理 | [models/ocr/] | 将扫描件转换为可搜索文本 |
1.3 生态集成设计:AI工作流的"万能适配器"
Docling不是孤立的工具,而是AI应用生态的关键连接者。它就像一个万能插座,能够无缝对接各种主流AI框架和工具:

核心集成能力:
- 检索增强生成(RAG):与LangChain、LlamaIndex等框架深度集成([integrations/])
- 数据处理管道:支持与Data Prep Kit等数据准备工具协同工作
- 模型训练:输出干净文本适合LLM微调([examples/rag_llamaindex.ipynb])
2 零基础实战:3步实现文档的AI适配转换
2.1 环境准备:5分钟快速上手
开始使用Docling就像准备一顿美食,首先需要准备好"厨房"和"食材":
安装步骤:
# 克隆项目仓库
git clone https://gitcode.com/GitHub_Trending/do/docling
cd docling
# 创建并激活虚拟环境
python -m venv venv
source venv/bin/activate # Linux/Mac
venv\Scripts\activate # Windows
# 安装依赖
pip install .
验证安装:
docling --version
2.2 基础转换:一行命令搞定多格式处理
最基本的文档转换就像使用洗衣机——放入"脏衣服"(原始文档),选择"程序"(输出格式),按下"开始":
# 基本转换命令
docling convert input.pdf --output-format markdown --output-dir results/
# 批量转换多个文件
docling convert docs/*.docx --output-format json --output-dir json_results/
常用参数解析:
--output-format:指定输出格式(markdown/json/html/text/doctags)--ocr:对扫描文档启用OCR处理--include-images:保留并处理图像内容--page-range:指定处理页面范围(如1-5,7)
2.3 结果验证:如何检查转换质量
转换完成后,就像烹饪完成需要品尝一样,你需要检查转换质量:
关键检查点:
- 结构完整性:标题层级是否正确([examples/extraction.ipynb])
- 表格还原度:复杂表格是否保持结构([tests/test_backend_csv.py])
- 特殊元素:公式、代码块等是否正确转换
- 图像处理:图片是否被正确描述或嵌入
3 场景化方案:4大行业的文档AI适配策略
3.1 学术研究:从PDF论文到AI分析素材
学术论文通常包含复杂的公式、图表和引用,Docling提供专业处理方案:
推荐配置:
- 输入格式:PDF或LaTeX源文件
- 处理选项:启用公式识别和引用提取
- 输出组合:Markdown(阅读)+ JSON(结构化分析)
- 示例代码:[examples/backend_xml_rag.ipynb]
工作流优化:
- 批量转换整个论文库建立本地知识库
- 使用Docling的分块功能([chunking/])按章节组织内容
- 结合LlamaIndex构建论文问答系统
3.2 企业办公:文档资产的智能盘活
企业积累的大量DOCX、PPTX和XLSX文件是宝贵的知识资产:
推荐配置:
- 输入格式:Office文档全家桶
- 处理选项:表格识别和图像描述生成
- 输出组合:HTML(内部展示)+ CSV(数据提取)
- 最佳实践:[docs/usage/enrichments.md]
价值提升:
- 自动将年度报告转换为交互式网页
- 从历史Excel报表中提取结构化数据
- 为PPT自动生成文字摘要,便于快速检索
3.3 法律行业:扫描合同的智能解析
法律文档常为扫描件,包含复杂条款和关键信息:
推荐配置:
- 输入格式:扫描PDF或图像文件
- 处理选项:高精度OCR和条款识别
- 输出组合:JSON(结构化查询)+ 纯文本(模型训练)
- OCR引擎选择:[models/rapid_ocr_model.py]或[tesseract_ocr_model.py]
效率提升:
- 合同审查时间减少70%
- 关键条款自动提取和分类
- 历史案例库快速检索
3.4 内容创作:多源素材的智能整合
内容创作者需要处理各种来源的素材:
推荐配置:
- 输入格式:网页(HTML)、Markdown、电子书
- 处理选项:去重、格式标准化、内容提取
- 输出组合:Markdown(编辑)+ JSON(元数据)
- 示例代码:[examples/custom_convert.py]
创作提效:
- 多来源素材自动整合
- 格式统一减少排版工作
- 内容结构自动优化
4 进阶技巧:5招提升转换效率与质量
4.1 性能优化:处理大型文档的3个关键配置
处理数百页的大型文档时,效率至关重要:
配置优化:
from docling.datamodel.pipeline_options import PipelineOptions
# 大型文档优化配置
options = PipelineOptions(
batch_size=10, # 批处理大小
use_accelerator=True, # 使用硬件加速
max_workers=4 # 并行处理数量
)
资源调配:
- CPU模式:适合文本为主的文档,配置[accelerator_options.py]
- GPU模式:适合图像密集型文档,启用CUDA加速
- 内存管理:处理超大文件时启用分块处理([chunking/hybrid_chunker.py])
4.2 格式定制:打造符合需求的输出样式
Docling允许你像定制蛋糕一样定制输出格式:
Markdown定制示例:
from docling.backend.md_backend import MarkdownBackend
# 自定义Markdown输出
backend = MarkdownBackend(
header_offset=1, # 调整标题层级
table_format="github", # 表格样式
code_block_style="fenced" # 代码块格式
)
HTML定制:
from docling.backend.html_backend import HTMLBackend
# 图像处理策略
backend = HTMLBackend(
embed_images=False, # 不嵌入图像
image_output_dir="assets/images/", # 图像保存目录
css_stylesheet="custom.css" # 自定义样式
)
4.3 常见问题诊断:7大转换难题解决方案
| 问题类型 | 可能原因 | 解决方法 |
|---|---|---|
| PDF文字乱码 | 字体嵌入问题 | 切换后端:--backend pypdfium2 |
| 表格识别错误 | 复杂边框或合并单元格 | 启用增强模式:--enable-table-enhancer |
| OCR识别率低 | 图像质量差 | 预处理:--preprocess enhance |
| 公式转换失败 | 特殊符号或复杂公式 | 使用LaTeX后端:--formula-mode latex |
| 大文件内存溢出 | 内存不足 | 启用流式处理:--streaming |
| 转换速度慢 | 资源配置不足 | 优化参数:--batch-size 20 --max-workers 8 |
| 中文显示异常 | 编码设置问题 | 指定编码:--encoding utf-8 |
4.4 高级集成:与AI框架的无缝对接
Docling输出可以直接喂给AI模型,就像为AI准备好"营养餐":
LangChain集成示例:
from langchain.document_loaders import DoclingLoader
# 使用Docling作为LangChain的文档加载器
loader = DoclingLoader("complex_document.pdf")
documents = loader.load()
# 直接用于RAG应用
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
db = Chroma.from_documents(documents, OpenAIEmbeddings())
LlamaIndex集成:
from llama_index import SimpleDirectoryReader
from llama_index.readers.file.docs import DoclingReader
# 配置Docling作为LlamaIndex的读取器
reader = DoclingReader()
documents = SimpleDirectoryReader(
input_dir="docs/",
file_extractor={".pdf": reader, ".docx": reader}
).load_data()
4.5 批量处理:自动化文档转换流水线
对于大量文档,手动处理效率低下,Docling提供批量解决方案:
批量处理脚本:[examples/batch_convert.py]
关键特性:
- 支持多格式混合输入
- 失败任务自动重试
- 处理进度监控和报告
- 错误日志记录和分析
5 总结:开启文档AI化的新篇章
Docling通过创新的架构设计和强大的处理能力,彻底改变了文档与AI交互的方式。无论是学术研究、企业办公还是内容创作,它都能将复杂多样的文档格式转换为AI友好的标准化表示,为生成式AI应用提供高质量的数据输入。

从今天开始,告别格式转换的烦恼,让Docling成为你与AI之间的文档翻译官。访问项目仓库获取完整文档和示例代码,探索更多高级功能:
git clone https://gitcode.com/GitHub_Trending/do/docling
准备好让你的文档资产焕发AI时代的新价值了吗?只需一行命令,开启智能文档处理之旅!
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







