



 本文深入探讨SQL Server执行计划中的第二组运算符,包括RID查找、密钥查找和排序运算符,解析它们的工作原理,以及如何优化查询以减少不必要的开销。
本文深入探讨SQL Server执行计划中的第二组运算符,包括RID查找、密钥查找和排序运算符,解析它们的工作原理,以及如何优化查询以减少不必要的开销。
In the previous article, we talked about the first set of operators you may encounter when working with SQL Server Execution Plans. We described the Non Clustered Index, Seek Execution Plan operators, Table Scan, Clustered Index Scan, and the Clustered Index Seek. In this article, we will discuss the second set of these SQL Server execution plan operators.
在上一篇文章中 ,我们讨论了在使用SQL Server执行计划时可能遇到的第一组运算符。 我们描述了非聚集索引,寻求执行计划操作员,表扫描,聚集索引扫描和聚集索引寻求。 在本文中,我们将讨论第二组这些SQL Server执行计划运算符。
Let us first create the below table and fill it with 3K records to use it in the examples of this article. The table can be created and filled with data using the T-SQL script below:
让我们首先创建下表,并在其中填充3K记录,以在本文的示例中使用它。 可以使用以下T-SQL脚本创建表并用数据填充该表:
CREATE TABLE ExPlanOperator_P2
( ID INT IDENTITY (1,1),
EmpFirst_Name VARCHAR(50),
EmpLast_name VARCHAR(50),
EmpAddress VARCHAR(MAX),
EmpPhoneNum varchar(50)
)
GO
INSERT INTO ExPlanOperator_P2 VALUES ('AB','BA','CB','123123')
GO 1000
INSERT INTO ExPlanOperator_P2 VALUES ('DA','EB','FC','456456')
GO 1000
INSERT INTO ExPlanOperator_P2 VALUES ('DC','EA','FB','789789')
GO 1000
SQL Server RID查找运算符 (SQL Server RID Lookup Operator)
Assume that we have a Non-Clustered index on the EmpFirst_Name column of the ExPlanOperator_P2 table, that is created using the CREATE INDEX T-SQL statement below:
假设我们在ExPlanOperator_P2表的EmpFirst_Name列上有一个非聚集索引,该索引是使用下面的CREATE INDEX T-SQL语句创建的:
CREATE INDEX IX_ExPlanOperator_P2_EmpFirst_Name ON ExPlanOperator_P2 (EmpFirst_Name)
If you try to run the below SELECT statement to retrieve information about all employees with a specific EmpFirst_Name values, after including the Actual SQL Server execution plan of that query:
如果您尝试运行下面的SELECT语句以在包含该查询的实际SQL Server执行计划之后检索有关具有特定EmpFirst_Name值的所有雇员的信息:
SELECT * FROM ExPlanOperator_P2 WHERE EmpFirst_Name = 'BB'
Checking the SQL Server explain plan generated after executing the query, you will see that the SQL Server Query Optimizer will use the Non-Clustered index to seek for all the employees with the EmpFirst_Name values equal to ‘BB’, without the need to scan the overall table for these values. On the other hand, the SQL Server Engine will not be able to retrieve all the requested values from that Non-Clustered index, as the query requests all columns for that filtered records. Recall that the Non-Clustered index contains only the key column values and a pointer to the rest of the columns for that key in the base table.
检查执行查询后生成SQL Server说明计划,您将看到SQL Server查询优化器将使用非聚集索引来查找EmpFirst_Name值等于'BB'的所有员工,而无需扫描这些值的总体表。 另一方面,SQL Server引擎将无法从该非聚集索引中检索所有请求的值,因为查询请求该过滤记录的所有列。 回想一下,非聚集索引仅包含键列值和指向基表中该键的其余列的指针。
To dive deeply into the Non-Clustered index subject, see the article Designing effective SQL Server non-clustered indexes.
要深入研究非聚集索引主题,请参阅文章 设计有效SQL Server非聚集索引 。
Due to the fact that this table contains no Clustered index, the table will be considered a heap table that has no criteria to sort its pages and sort the data within the pages.
由于该表不包含聚簇索引,因此该表将被视为堆表,该堆表没有条件对其页面进行排序以及对页面中的数据进行排序。
For more information about the heap table structure, check SQL Server table structure overview.
有关堆表结构的更多信息,请检查 SQL Server表结构概述 。
Because of this, the SQL Server Engine will use the pointers from the Non-Clustered index, that points to the location of the rest of the columns on the base table, to locate and retrieve the rest of columns from the underlying table, using a Nested Loops operator to join the Index Seek data with the set of data retrieved from the RID Lookup operator, also known as a Row Identifier operator, as shown in the SQL Server execution plan below:
因此,SQL Server引擎将使用非聚集索引中的指针指向基本表上其余列的位置,以使用基本索引从基础表中查找和检索其余列。嵌套循环运算符,用于将索引查找数据与从RID查找运算符(也称为行标识符)运算符检索的数据集结合在一起,如以下SQL Server执行计划中所示:

A RID is a row locator that includes information about the location of that record such as the database file, the page, the slot numbers that helps to identify the location of the row quickly. If you move the mouse to point to the RID Lookup on the generated SQL Server execution plan to view the tooltip of that operator, you will see in the Output List, the list of columns that are requested by the query and returned by this operator, as these columns are not located in the Non-Clustered index, as shown below:
RID是行定位器,其中包含有关该记录位置的信息,例如数据库文件,页面,插槽号,这些信息有助于快速识别行的位置。 如果您将鼠标移至所生成SQL Server执行计划上的RID查找以查看该操作员的工具提示,则将在“输出列表”中看到查询所请求并由该操作员返回的列的列表,因为这些列不在非聚集索引中,如下所示:
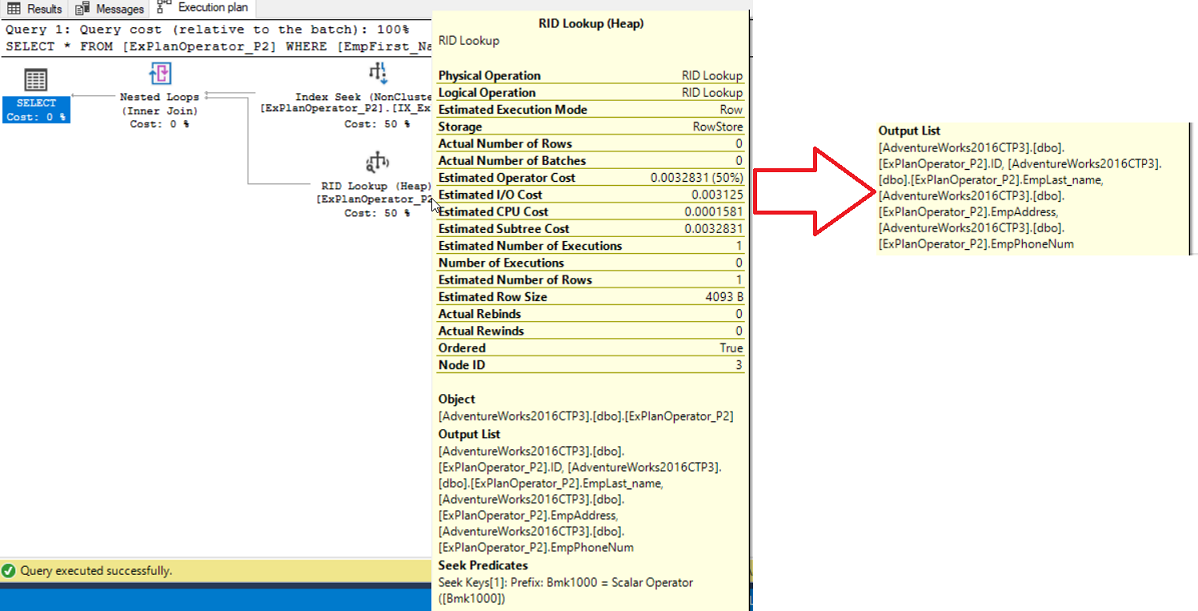
If you look at the RID Lookup operator in the SQL Server execution plan, you will see that the cost of that operator is high related to the overall weight of the plan, which is 50% in our example. This is due to the additional I/O overhead of the two different operations that are performed instead of a single one, before combining it with a Nested Loops operation. This overhead can be neglected when processing small number of rows. But if you are working with huge number of records, it is better to tune that query, rewrite the query by limiting the retrieved columns or create a covering index for that query. If the RID Lookup is eliminated by creating a covering index, the Nested Loops operator would not be needed in this SQL Server execution plan. To dig deeply in the covering index concept, check Working with different SQL Server indexes types.
如果您在SQL Server执行计划中查看RID查找运算符,则会发现该运算符的成本与计划的整体权重有关,在我们的示例中为50%。 这是由于在将其与嵌套循环操作组合在一起之前,执行了两个不同操作而不是单个操作的额外I / O开销。 处理少量的行时,可以忽略此开销。 但是,如果您要处理大量记录,则最好调整该查询,通过限制检索到的列来重写查询或为该查询创建覆盖索引。 如果通过创建覆盖索引消除了RID查找,则此SQL Server执行计划中将不需要嵌套循环运算符。 要深入研究覆盖索引概念,请选中使用不同SQL Server索引类型 。
SQL Server密钥查找运算符 (SQL Server Key Lookup Operator)
The Key Lookup operator is the Clustered equivalent of the RID Lookup operator described in the previous section. Assume that we have the below Clustered index that is created on the ID column of the EmpFirst_Name table, using the CREATE INDEX T-SQL statement below:
密钥查找运算符与上一节中介绍的RID查找运算符等效。 假设我们具有下面的使用CREATE INDEX T-SQL语句在EmpFirst_Name表的ID列上创建的聚集索引:
CREATE CLUSTERED INDEX IX_ExPlanOperator_P2_ID on ExPlanOperator_P2 (ID)
If you try to run the previous SELECT statement that retrieves information about all employees with a specific EmpFirst_Name values, after including the Actual SQL Server execution plan of that query:
如果尝试运行先前的SELECT语句,该语句在包含该查询的实际SQL Server执行计划之后,检索有关具有特定EmpFirst_Name值的所有雇员的信息:
SELECT * FROM ExPlanOperator_P2 WHERE EmpFirst_Name = 'BB'
Checking the SQL Server Execution Plan generated after executing the query, you will notice that the SQL Server Engine performed a seek operation on the Non-Clustered index to retrieve all the employees with the EmpFirst_Name column values equal to ‘BB’. But again, not all the columns can be retrieved from that Non-Clustered index. Therefore, the SQL Server Engine will derive benefits from the pointers existing on that Non-Clustered index that point to the rest of columns in the underlying table. And also due to the fact that this table is a Clustered table, that has a Clustered index that sorts that table’s data, the Non_Clustered index pointers will point to the Clustered index instead of pointing to the underlying table. The rest of columns will be retrieved using a Nested Loops operator to join the Index Seek data with the data retrieved from the Key Lookup operator, as the SQL Server Engine is not able to retrieve the rows in a shot. In other words, the SQL Server Engine will use the clustered index key as a reference to look up for the data that is stored in the clustered index using the clustered key values stored in the Non-Clustered index, as shown in the SQL Server execution plan below:
检查执行查询后生成SQL Server执行计划,您会注意到SQL Server引擎对非聚集索引执行了查找操作,以检索EmpFirst_Name列值等于'BB'的所有雇员。 但是同样,并非所有列都可以从该非聚集索引中检索。 因此,SQL Server引擎将从该非聚集索引上存在的指向基础表中其余列的指针中受益。 而且由于该表是一个群集表,并且具有一个对该表的数据进行排序的群集索引,因此Non_Clustered索引指针将指向该群集索引,而不是指向基础表。 其余的列将使用嵌套循环运算符检索,以将“索引查找”数据与从“键查找”运算符检索的数据结合在一起,因为SQL Server引擎无法检索快照中的行。 换句话说,SQL Server引擎将使用聚簇索引键作为参考,以使用存储在非聚簇索引中的聚簇键值来查找聚簇索引中存储的数据,如SQL Server执行所示计划如下:

Similar to the RID Lookup operator, the Key Lookup is very expensive as it requires additional I/O overhead, depending on the number of records. In addition, the Key Lookup operator is an indicator that a covering or included index is required and may enhance the performance of that query by eliminating the need of the Key Lookup and Nested Loops operators. For example, if we include all the required columns in the existing Non-Clustered index, using the CREATE INDEX T-SQL statement below:
与RID查找操作符类似,密钥查找非常昂贵,因为它需要额外的I / O开销,具体取决于记录的数量。 另外,关键字查找运算符指示是否需要覆盖或包含的索引,并且可以通过消除关键字查找和嵌套循环运算符的使用来提高查询的性能。 例如,如果我们在现有的非聚集索引中包括所有必需的列,请使用下面的CREATE INDEX T-SQL语句:
CREATE INDEX IX_ExPlanOperator_P2_EmpFirst_Name ON ExPlanOperator_P2 (EmpFirst_Name) INCLUDE (ID,EmpLast_name, EmpAddress, EmpPhoneNum) WITH (DROP_EXISTING = ON)
Next run the previous SELECT statement with including the Actual Execution Plan. You will see that the Key Lookup and the Nested Loops operators are no longer used as the SQL Server Engine will retrieve all the requested data by seeking the Non-Clustered index, as shown below:
接下来,运行上一个SELECT语句,其中包括“实际执行计划”。 您将看到不再使用键查找和嵌套循环运算符,因为SQL Server引擎将通过搜索非聚集索引来检索所有请求的数据,如下所示:

SQL Server排序运算符 (SQL Server Sort Operator )
Assume that we run the below SELECT statement that returned the list of employees with a specific EmpFirst_Name value from the ExPlanOperator_P2 table, sorted by the EmpLast_Name column values descending, using the ORDER BY clause:
假设我们运行下面的SELECT语句,该语句从ExPlanOperator_P2表返回具有特定EmpFirst_Name值的雇员列表,并使用ORDER BY子句按EmpLast_Name列值降序排序:
SELECT * FROM ExPlanOperator_P2 WHERE EmpFirst_Name = 'BB' ORDER BY EmpLast_name desc
Checking the SQL Server execution plan generated after executing the query, you will see that the SQL Server Engine seeks the Non-Clustered index to retrieve the requested data, then the output of the Index Seek operator will be flown to the to the SORT operator to sort the data as specified in the ORDER BY clause, with the default ASC sorting direction if not specified. The SQL Server execution plan in our case will be like:
检查执行查询后生成SQL Server执行计划,您会看到SQL Server Engine寻求非聚集索引来检索请求的数据,然后将Index Seek运算符的输出传递给SORT运算符,以按照ORDER BY子句中指定的顺序对数据进行排序,如果未指定,则使用默认的ASC排序方向。 在我们的案例中,SQL Server执行计划将类似于:

If you move the mouse to point to the SORT operator, you will see that the output of the SORT operator is the same input columns but sorted by the specified column, as in the Tooltip shown below:
如果将鼠标移到SORT运算符,您将看到SORT运算符的输出是相同的输入列,但按指定的列排序,如下所示的工具提示中所示:
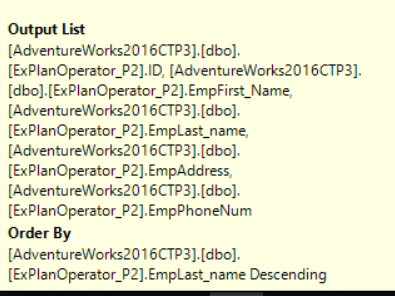
The SORT operator is an expensive operator as you can see from the SQL Server execution plan. Where the cost of the SORT operator in our case is 78% of the overall query cost. This cost is due to that, the column specified in the ORDER BY clause has no index defined on it on the requested order. So that, you need always to think if this sort operation is really required, if you can live without it, it is better not to use it or create an index to have a sorted copy of this column, eliminating the SORT operator overhead.
从SQL Server执行计划可以看出,SORT运算符是一种昂贵的运算符。 在我们的案例中,SORT运算符的成本占总查询成本的78%。 这样做的原因是,在ORDER BY子句中指定的列上没有在所请求订单上定义的索引。 因此,您始终需要考虑是否确实需要这种排序操作,如果可以不使用它,最好不要使用它或创建索引来拥有该列的排序副本,从而消除SORT运算符的开销。
Stay tuned for the next article, in which we will discuss the third set of the SQL Server execution plan operators.
请继续关注下一篇文章,在这篇文章中我们将讨论第三组SQL Server执行计划运算符。
目录 (Table of contents)
翻译自: https://www.sqlshack.com/sql-server-execution-plan-operators-part-2/


















 4887
4887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









